本文主要是介绍大模型咨询培训老师叶梓:利用知识图谱和Llama-Index增强大模型应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大模型(LLMs)在自然语言处理领域取得了显著成就,但它们有时会产生不准确或不一致的信息,这种现象被称为“幻觉”。为了提高LLMs的准确性和可靠性,可以借助外部知识源,如知识图谱。那么我们如何通过Llama-Index实现知识图谱与LLMs的有效交互,从而提升应用性能呢?
先来了解下知识图谱
知识图谱是一种结构化的语义知识库,它通过图的形式存储和表示实体(如人、地点、组织)以及它们之间的各种关系(如属于、位于、创立者等)。知识图谱通常由顶点(节点)和边组成,顶点代表实体,边代表实体间的关系。知识图谱使得复杂查询成为可能,这些查询可以跨越多个关系和实体进行,从而提供丰富的语义信息和深入的洞察力。
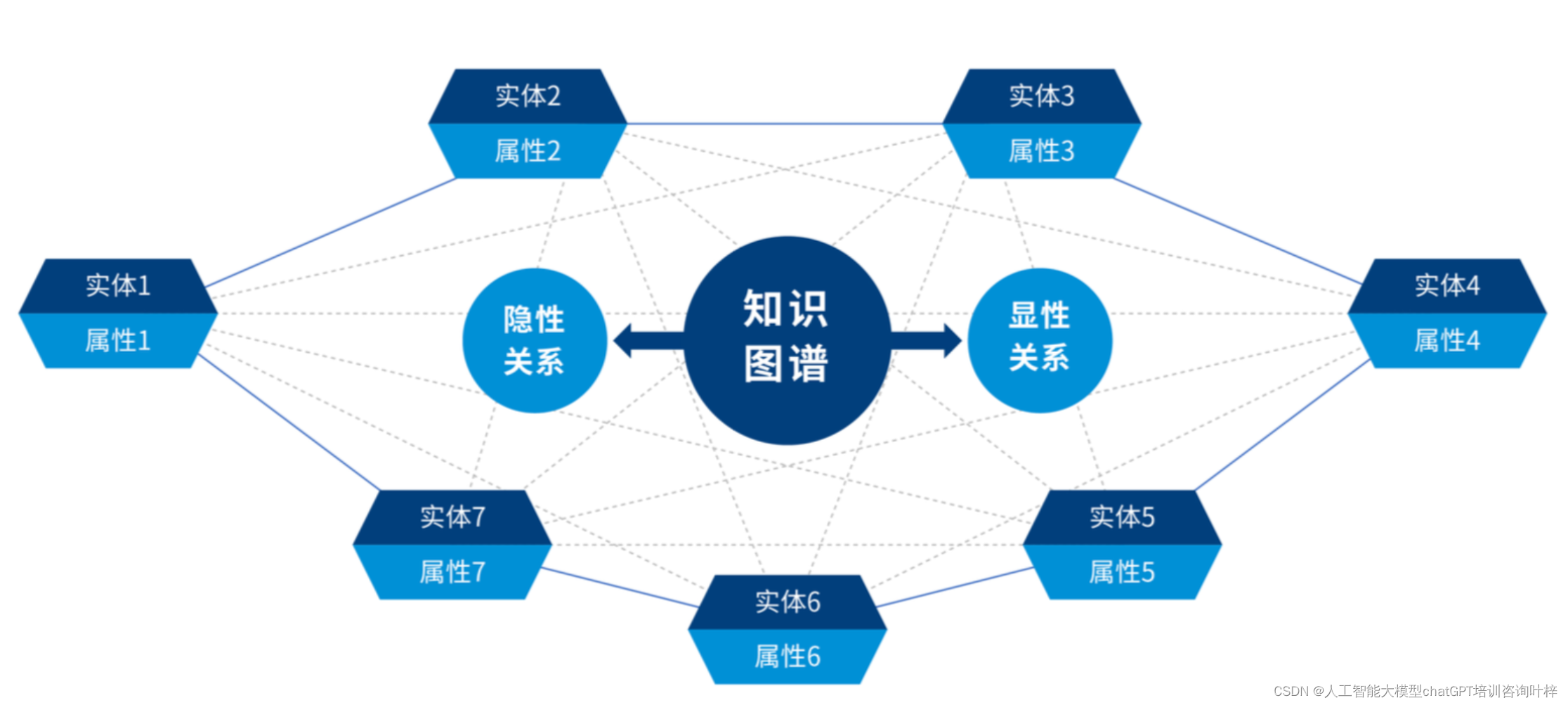
知识图谱在LLMs中的应用优势
精确性
-
具体关系信息:知识图谱存储了实体之间的具体关系,这些关系是明确和结构化的。例如,知识图谱可以明确指出“埃菲尔铁塔”是位于“巴黎”的一座著名建筑物,并且是该城市的地标。这种具体性使得LLMs在生成文本时可以引用这些确切的事实,而不是依赖于可能含糊的上下文或相似度推断。
-
减少歧义:在自然语言中,单词或短语可能有多种含义。知识图谱通过其结构化的数据模型帮助LLMs理解特定上下文中单词的确切含义,从而减少生成文本中的歧义和潜在错误。
复杂查询支持
-
逻辑运算符:知识图谱能够支持使用逻辑运算符(如AND、OR、NOT)的复杂查询,这允许LLMs执行更细致的搜索和信息检索。例如,一个查询可能需要找出所有“位于巴黎且由著名建筑师设计”的建筑物,这种类型的查询在知识图谱中是可行的,而在基于向量的数据库中则难以实现。
-
多跳查询:知识图谱允许执行多跳查询,即查询可以跨越多个关系来寻找答案。这对于需要推理和串联多个知识点的问题至关重要,而向量数据库通常只提供基于相似度的直接匹配。
推理和推断能力
-
间接信息推导:知识图谱不仅可以提供直接的信息,还可以通过实体间的复杂关系推导出间接信息。例如,如果知识图谱中存在“法国的首都是巴黎”和“埃菲尔铁塔位于法国”这样的信息,知识图谱可以推断出“埃菲尔铁塔位于巴黎”。这种推理能力对于LLMs生成连贯和逻辑上一致的文本至关重要。
-
上下文推理:在对话系统或问答应用中,知识图谱可以帮助LLMs根据上下文中的线索进行推理,提供更加准确和相关的答案。
-
知识更新:知识图谱可以更容易地更新和维护,这意味着LLMs可以利用最新的知识库来生成文本,减少了过时信息导致的幻觉。
结合LLMs的应用
通过将知识图谱与LLMs结合,可以创建更加智能和准确的应用,如:
- 智能问答系统:利用知识图谱的精确信息和推理能力,提供基于事实的答案。
- 内容推荐系统:通过理解用户的兴趣和偏好,结合知识图谱中的实体关系,提供个性化推荐。
- 自动文摘生成:LLMs可以利用知识图谱中的结构化信息来生成特定主题的摘要或报告。
知识图谱通过其精确的关系信息、复杂查询处理能力和推理推断机制,为LLMs提供了一个坚实的知识基础,从而减少了幻觉的发生,提高了应用的准确性和可靠性。
Llama-Index的角色和实现
Llama-Index作为一个数据框架和编排工具,它在构建基于大模型(LLMs)的应用程序中扮演了核心角色。它主要负责以下几个方面:
- 数据集成:Llama-Index能够整合私有数据和公共数据,为LLMs提供更丰富的输入上下文。
- 数据结构化:它将非结构化的文本数据转换为结构化的知识图谱,便于LLMs更好地理解和使用这些数据。
- 查询优化:Llama-Index提供了查询工具,可以优化LLMs的查询过程,使其更加高效和准确。
- 多功能解决方案:作为一个多功能的解决方案,Llama-Index支持各种数据处理任务,包括数据摄取、索引构建和查询响应。
实现步骤的详细说明
-
安装依赖:
- 安装Llama-Index及其依赖库是第一步。这可能包括用于图数据可视化的
pyvis库,以及用于交互式计算的Ipython。 - 这些工具和库为后续的知识图谱构建和数据查询提供了必要的技术支持。
- 安装Llama-Index及其依赖库是第一步。这可能包括用于图数据可视化的
-
构建知识图谱索引:
- 使用Llama-Index提供的
KnowledgeGraphIndex模块,开发者可以从各种文档中提取信息,构建出结构化的知识图谱。 - 这一步骤涉及文本解析、实体识别、关系抽取等过程,将非结构化的文本信息转换为图结构的数据表示。
- 使用Llama-Index提供的
-
查询引擎设置:
- 构建好的索引可以作为查询引擎,用于响应用户的查询。
- Llama-Index支持多种查询模式,包括简单的关键词搜索和复杂的语义查询,能够根据用户的提问从知识图谱中检索相关信息。
-
数据持久性:
- 通过调用
storage_context.persist()方法,可以将构建的知识图谱和索引数据进行持久化存储。 - 持久化存储的好处在于,即使在应用程序重启后,之前构建的知识图谱和索引仍然可以被访问和使用,避免了重复计算的开销。
- 通过调用
实现Llama-Index的关键点
- 模块化设计:Llama-Index的设计允许开发者根据需要选择和组合不同的模块,以适应不同的应用场景。
- 可扩展性:随着数据量的增加,Llama-Index提供的解决方案可以方便地进行扩展,以处理更大规模的数据集。
- 易用性:Llama-Index提供了简单直观的API,使得开发者可以快速上手并构建自己的应用程序。
Llama-Index不仅简化了知识图谱的构建和使用,而且提高了LLMs在各种自然语言处理任务中的性能,如问答系统、内容推荐和对话生成等。
知识图谱的图形表示
利用pyvis库,我们可以将知识图谱以图形的方式进行展示,这在可视化实体间关系和依赖性方面非常有用。图形表示提供了一种直观的方式来展示和理解复杂的数据关系。实体和它们之间的关系通过图形化的方式展现出来,使得用户可以一目了然地看到整个知识图谱的结构,以及不同实体是如何相互连接的。
pyvis库的作用
pyvis是一个Python库,它专门用于创建和操作交互式网络图。在知识图谱的上下文中,pyvis可以用来:
- 生成网络图:将知识图谱中的实体作为节点,关系作为边,快速生成一个网络图。
- 交互式探索:生成的网络图是交互式的,用户可以通过点击节点或边来获取更多信息,或者查看实体之间的关系。
- 定制外观:
pyvis允许用户定制网络图的外观,包括节点的大小、颜色、形状,以及边的样式等。
图形表示的实现步骤
-
准备数据:首先,需要将知识图谱的数据结构转换为
pyvis可以识别的格式,通常是通过创建一个包含节点和边信息的列表。 -
创建网络对象:使用
pyvis创建一个Network对象,这是图形表示的核心。 -
添加节点和边:将准备好的节点和边数据添加到
Network对象中。 -
设置图形属性:根据需要设置网络图的属性,比如节点的尺寸、颜色,边的宽度等。
-
启动交互式网络图:使用
Network对象的show方法,可以在Web浏览器中启动一个交互式的网络图。 -
保存和分享:如果需要,可以将网络图保存为HTML文件,方便分享或后续使用。
示例代码
from pyvis.network import Network# 创建网络对象,设置为有向图
net = Network(notebook=True, directed=True)# 添加节点和边,这里只是一个示例
node1 = net.add_node(1, label="Entity 1")
node2 = net.add_node(2, label="Entity 2")
net.add_edge(node1, node2, label="Relation")# 生成并显示网络图
net.show("knowledge_graph.html")知识图谱和Llama-Index的结合为LLMs提供了一个强大的工具,以增强其在处理复杂查询和提供准确信息方面的能力。通过利用知识图谱的结构化信息,可以在LLMs中减少幻觉的发生,生成更准确、更可靠的文本。此外,Llama-Index提供的灵活性和多功能性使其成为构建基于知识图谱的LLM应用程序的理想选择。
这篇关于大模型咨询培训老师叶梓:利用知识图谱和Llama-Index增强大模型应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






