本文主要是介绍携程 Java 暑期实习二面:MQ 消息堆积怎么办?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

更多大厂面试内容可见 -> http://11come.cn
携程 Java 暑期实习二面
MySQL
1、讲讲索引失效的情况
MySQL 的索引结构是 B+ 树,当查询语句使用不当,就会导致无法使用 B+ 树索引进行查询,从而导致出现全表扫描,如下列出来了很多情况,先挑重点进行记忆,比如因为 左模糊查询 、 不符合前缀索引 、 范围查询放在了前边 从而导致索引失效,这些是比较常见的
接下来介绍一下 MySQL 在哪些情况下索引会失效,在实际使用的时候,要尽量避免索引失效:
- 使用左模糊查询
select id,name,age,salary from table_name where name like '%lucs';
在进行 SQL 查询时,要尽量避免左模糊查询,可以改为右模糊查询,在右模糊查询的情况下一般都会走索引
select id,name,age,salary from table_name where name like 'lucs%';
- 不符合最左前缀原则的查询
对于联合索引(a,b,c),来说,不能直接用 b 和 c 作为查询条件而直接跳过 a,这样就不会走索引了
如果查询条件使用 a,c,跳过了 b,那么只会用到 a 的索引
- 联合索引的第一个字段使用范围查询
比如联合索引为:(name,age,position)
select * from employees where name > 'LiLei' and age = 22 and position ='manager';
如上,联合索引的第一个字段 name 使用范围查询,那么 InnoDB 存储引擎可能认为结果集会比较大,如果走索引的话,再回表查速度太慢,所以干脆不走索引了,直接全表扫描比较快一些
可以将范围查询放在联合索引的最后一个字段
- 联合索引中有一个字段做范围查询时用到了索引,那么该字段后边的列都不能走索引
select * from employees where name = 'LiLei' and age > 10 and age < 20 and position = 'manager';
因为联合索引中这个字段如果使用范围查询的话,查询出来的数据对该字段后边的列并不是有序的,因此不能走索引了,所以尽量把范围查询都放在后边
- 对索引列进行了计算或函数操作
当你在索引列上进行计算或者使用函数,MySQL 无法有效地使用索引进行查询,索引在这种情况下也会失效,如下:
select * from employees where LEFT(name,3) = 'abc';
应该尽量避免在查询条件中对索引字段使用函数或者计算。
- 使用了 or 条件
当使用 or 条件时,只要 or 前后的任何一个条件列不是索引列,那么索引就会失效
select * from emp where id = 10010 or name = 'abcd';
如上,假如 name 列不是索引列,即使 id 列上有索引,这个查询语句也不会走索引
- 索引列上有 Null 值
select * from emp where name is null;
如上,name 字段存在 null 值,索引会失效
应该尽量避免索引列的值为 null,可以在创建表的时候设置默认值或者将 null 替换为其他特殊值。
JVM
2、讲讲 JVM 垃圾回收
JVM 垃圾回收部分包括了垃圾回收算法和垃圾回收器
垃圾回收算法有:标记-清除算法、复制算法、标记-压缩算法、分代回收算法
标记-清除算法 会从 GC Roots 开始遍历,将可到达的对象做标记,标记为存活对象,那么其他未标记的对象就是需要对象,将垃圾对象清除掉即可
缺点就是会产生内存碎片
复制算法 需要将内存区域分成大小相等的两块,当需要 GC 时,将其中一块内存区域中的存活对象复制到另外一块区域,再将原来的一块内存区域清空即可
优点是不会产生内存碎片,缺点是存在比较大的空间浪费
标记-压缩算法 是基于标记-清除算法的改进,先标记存活对象,之后将所有存活对象压缩到内存的一端,清除边界以外的垃圾对象即可
优点是既解决了标记-清除算法出现内存碎片的问题,又解决了复制算法中空间浪费的问题,但是效率低于复制算法
分代收集算法 是将 Java 堆分为新生代和老年代,这样就可以对不同生命周期的对象采取不同的收集方式,因为新生代中的对象生命周期短,存活率低,适合使用 复制算法 ,老年代生命周期长,存活率高,适合使用 标记-清除 或 标记-压缩 算法
垃圾收集器
有 8 种垃圾回收器,分别用于不同分代的垃圾回收:
- 新生代回收器:Serial、ParNew、Parallel Scavenge
- 老年代回收器:Serial Old、Parallel Old、CMS
- 整堆回收器:G1、ZGC
这里就不重复介绍了,可以参考 :JVM垃圾收集器
JDK1.8 中默认的垃圾收集器是 Parallel Scavenge(新生代)+Parallel Old(老年代)
公司中一般指定 G1 作为垃圾收集器的比较多 ,因为 G1 的特点就是天生适合用于大内存机器,无论内存多大,都可以指定期望的 GC 停顿时间,这样不至于停顿时间太长,导致用户体验卡顿
扩展:扫描存活对象是从 GC Roots 开始扫描的,那 GC Roots 包含哪些对象?
GC Roots 主要包含以下几类元素:
-
虚拟机栈中引用的对象
如:各个线程被调用的方法中所使用的参数、局部变量等
-
本地方法栈内的本地方法引用的对象
-
方法区中引用类型的静态变量
-
方法区中常量引用的对象
如:字符串常量池里的引用
-
所有被
synchronized持有的对象 -
Java 虚拟机内部的引用
如:基本数据类型对应的 Class 对象、异常对象(如 NullPointerException、OutOfMemoryError)、系统类加载器
3、G1 为什么可以设置 stw 最大时间
因为在 G1 中是将 JVM 堆划分为了多个 Region,每个 Region 的角色都是可以动态变化的,如下:
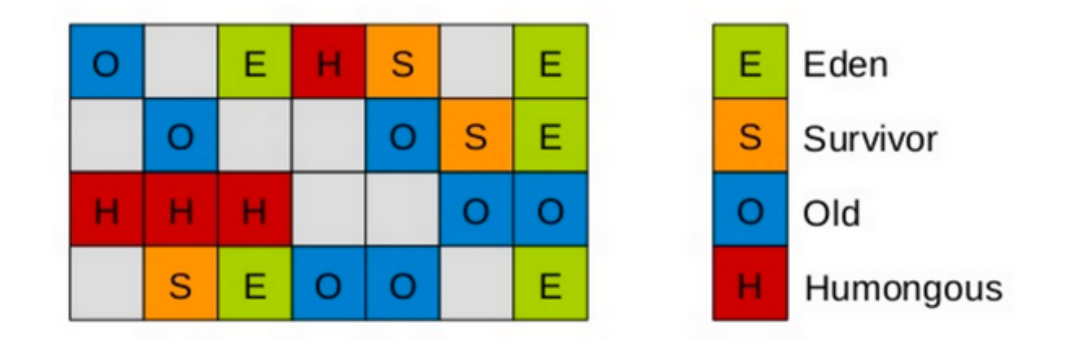
G1 在垃圾回收时,会有计划的进行回收,在指定的 stw 时间之内,尽可能回收价值更大的 Region,提升回收效率,并且保证可以达到期望的 stw (停顿)时间
这也是 G1 名字的由来:Garbage First,即垃圾优先
之前的垃圾回收器无法设置最大 stw 时间,是因为在每次回收都要回收整个区域,这个过程中无法中断,因此可能导致整个 GC 的时间太长
MQ
4、项目中怎么用的 MQ?
先讲清楚项目中的业务,为什么要在这样的业务下去使用 MQ?
可以根据 MQ 的特点来讲: 异步化 、 削峰填谷 、 解耦
从这三个方面来说项目中如何使用 MQ,使用过程中还有其他的问题,比如使用了 MQ 之后,肯定是会出现消息重复发送的情况,那么就要保证消费的 幂等性 ,那么如何保证消费的幂等性呢,也可以讲一下
5、MQ 消息堆积怎么办?
这里以 RocketMQ 为例来讲解
事发时处理
RocketMQ 发生了消息积压, 事发时 一般有两种处理方式:
- 加速消费:增加消费者的数量: 如果 Topic 下的 Message Queue 有很多,可以通过 增加消费者的数量 来处理消息积压,如果 Topic 下的 Message Queue 有很多,那么每个消费者是会分配一个或多个 Message Queue 进行消费的,那么此时就可以通过增加消费者的数量,来加快该 Topic 中消息的消费速度,
消费者数量必须小于 MessageQueue 的数量,增加消费者的数量才有效,如果消费者的数量已经大于 Message Queue 的数量了,再增加消费者的数量就没有作用了,因为一个 MessageQueue 最多只能由一个消费者进行消费 - 临时扩容:新建 Topic 进行消息迁移: 如果 Topic 下的 Message Queue 很少, 那么此时增加消费者的数量也没有用了,可以临时 新创建一个 Topic ,将该 Topic 的 Message Queue 设置多一点,再新创建一组消费者将原 Topic 中的消息转发到新 Topic 中,此时就可以对新 Topic 采用增加消费者数量的方式来处理消息积压了
案例
这里举一个例子:假如说有 1000 万条的消息积压,Topic 下有 3 个队列,有 3 个消费者,买个消费者 1s 可以处理 1000 条数据
那么 1000w 条数据处理完大约需要 50 分钟左右,那么如果不可以容忍这么长时间的话,就需要想办法提升消息的消费速度了
解决方案一:加速消费
如果 Message Queue 的队列大于消费者的数量,可以增加消费者数量来提升消费速度
但是如果队列数量大于等于消费者数量,那么再增加消费者数量就不起作用了,因此这种方法的效果有限
解决方案二:临时扩容
新建一个 Topic,队列设置为 30 个,消费者同时也创建 30 个,再新建一个消费者,将原来 Topic 下的消息转移到新的 Topic 下,此时就可以在新创建的 Topic 中进行消费了,速度相当于原来的 10 倍,可以将处理时间压缩在 5 分钟左右
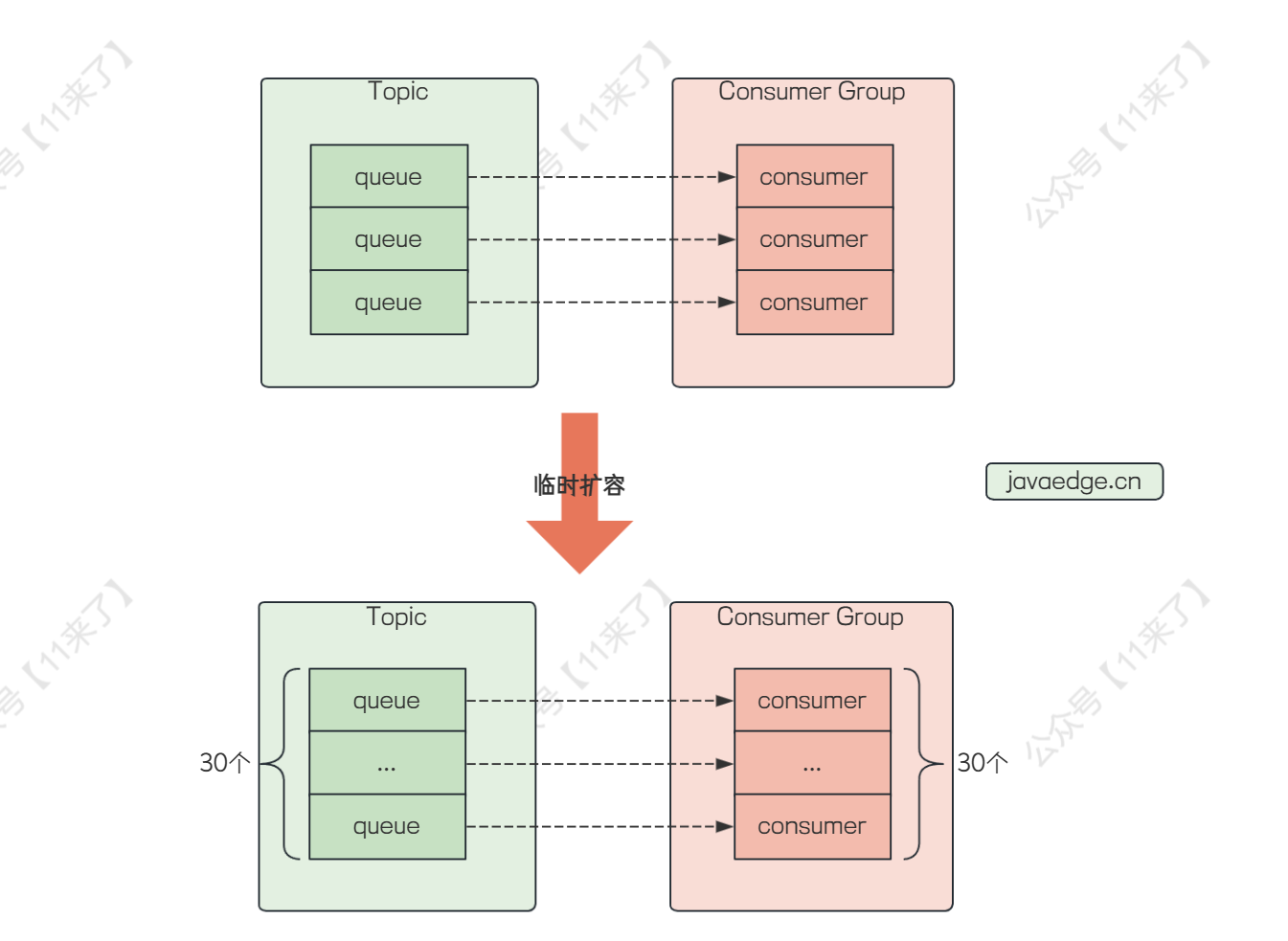
针对消息积压问题,提前预防
提前预防的话,主要可以从以下几个方面来考虑:
- 生产者
对于生产者,可以进行限流,并且评估 Topic 峰值流量,合理设计 Topic 下的队列数量,添加异常监控,及时发现
- 存储端
可以将次要消息转移
- 消费者
对于消费者来说,可以进行 降级 处理:将消息先落库,再去异步处理
并且要合理地根据 Topic 的队列数量和应用性能来部署响应的消费者机器数量
- 上线前
在上线前,采用灰度发布,先灰度小范围用户进行使用,没问题之后,再全量发布
这篇关于携程 Java 暑期实习二面:MQ 消息堆积怎么办?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





