本文主要是介绍【算法】人工蜂群算法,解决多目标车间调度问题,柔性车间调度问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 复现论文
- 什么是柔性作业车间调度问题?
- 数据处理
- ABC算法
- 编码解码
- 种群初始化
- 雇佣蜂操作
- IPOX交叉
- 多点交叉
- 观察蜂操作
- 侦察蜂操作
- 算法流程
- 结果
- 程序截图
- 问询、帮助
复现论文

什么是柔性作业车间调度问题?
也叫多目标车间调度问题。
柔性作业车间调度问题(Flexible Job Shop Scheduling Problem,简称FJSP)是传统作业车间调度问题的一种扩展。在传统的作业车间调度问题中,每个工件的每个工序只能在指定的一台机器上加工。而在柔性作业车间调度问题中,突破了这种资源唯一性的限制,允许每个工件的每个工序在多台不同的机器上加工,且这些机器上的加工时间可能不同。
这种灵活性使得作业车间调度问题更加贴合实际生产情况,因为实际生产中,同一道工序可能由不同的机器完成,不同的机器完成同一工序的时间和成本也可能有所差异。因此,FJSP 考虑了更多的生产实际,其目标通常是最小化最大完工时间(makespan),即所有工件中最后一个完工的工件的完成时间。
柔性作业车间调度问题的复杂性较高,因为它不仅要考虑工序的加工顺序,还要考虑不同机器上的加工时间差异,以及可能的机器选择问题。这些问题的组合导致了庞大的搜索空间,使得找到最优解或近似最优解成为一个具有挑战性的优化问题。
在数据集中,有10个待加工的工件,每一行就是一个工件。
下图是数据集截图,表示是,工件0一共有6个工序。后面数字是21534,表示第一道工序可选机器有2个,选择机器1花费时间为5可以完成这个工序的加工,选择机器3花费时间为4可以完成这个工序的加工。后面3533521是一组,表示第二个工序可选机器有3个,选择机器1花费时间为5可以完成这个工序的加工,选择机器3花费时间为4可以完成这个工序的加工,选择机器3花费时间为4可以完成这个工序的加工

全部数据集如下:
0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34
6,2,1,5,3,4,3,5,3,3,5,2,1,2,3,4,6,2,3,6,5,2,6.0,1.0,1.0,1.0,3.0,1.0,3.0,6.0,6.0,3.0,6.0,4.0,3.0
5,1,2,6,1,3,1,1,1,2,2,2,6,4,6,3,6,5,2,6,1,1,,,,,,,,,,,,,
5,1,2,6,2,3,4,6,2,3,6,5,2,6,1,1,3,3,4,2,6,6,6.0,2.0,1.0,1.0,5.0,5.0,,,,,,,
5,3,6,5,2,6,1,1,1,2,6,1,3,1,3,5,3,3,5,2,1,2,3.0,4.0,6.0,2.0,,,,,,,,,
6,3,5,3,3,5,2,1,3,6,5,2,6,1,1,1,2,6,2,1,5,3,4.0,2.0,2.0,6.0,4.0,6.0,3.0,3.0,4.0,2.0,6.0,6.0,6.0
6,2,3,4,6,2,1,1,2,3,3,4,2,6,6,6,1,2,6,3,6,5,2.0,6.0,1.0,1.0,2.0,1.0,3.0,4.0,2.0,,,,
5,1,6,1,2,1,3,4,2,3,3,4,2,6,6,6,3,2,6,5,1,1,6.0,1.0,3.0,1.0,,,,,,,,,
5,2,3,4,6,2,3,3,4,2,6,6,6,3,6,5,2,6,1,1,1,2,6.0,2.0,2.0,6.0,4.0,6.0,,,,,,,
6,1,6,1,2,1,1,5,5,3,6,6,3,6,4,3,1,1,2,3,3,4,2.0,6.0,6.0,6.0,2.0,2.0,6.0,4.0,6.0,,,,
6,2,3,4,6,2,3,3,4,2,6,6,6,3,5,3,3,5,2,1,1,6,1.0,2.0,2.0,6.0,4.0,6.0,2.0,1.0,3.0,4.0,2.0,,最终目标是要求加工完所有工件所需要的最小时间:

数据处理
10种类型的工件要加工,一共有6台机器:
da = data_deal(10, 6)
读取数据,解析数据:
Tmachine, Tmachinetime, tdx, work, tom, machines = da.cacu()
Tmachine 一行就是一个工件可以选择的机器。不足长度的补充0。
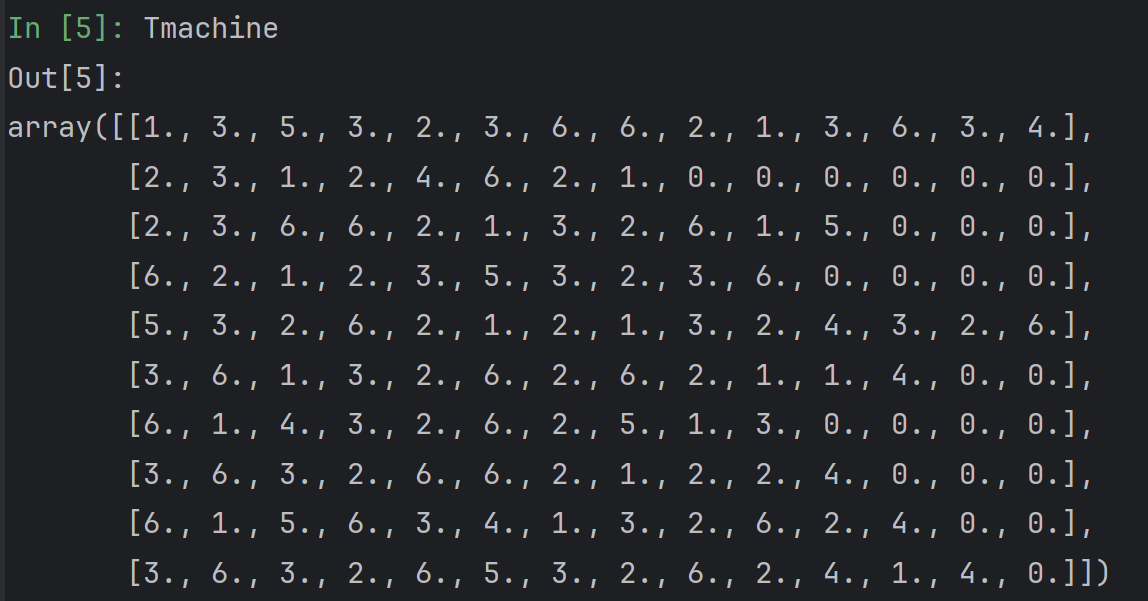
Tmachinetime和Tmachine 同样形状,表示每个机器对应需要多少时间:
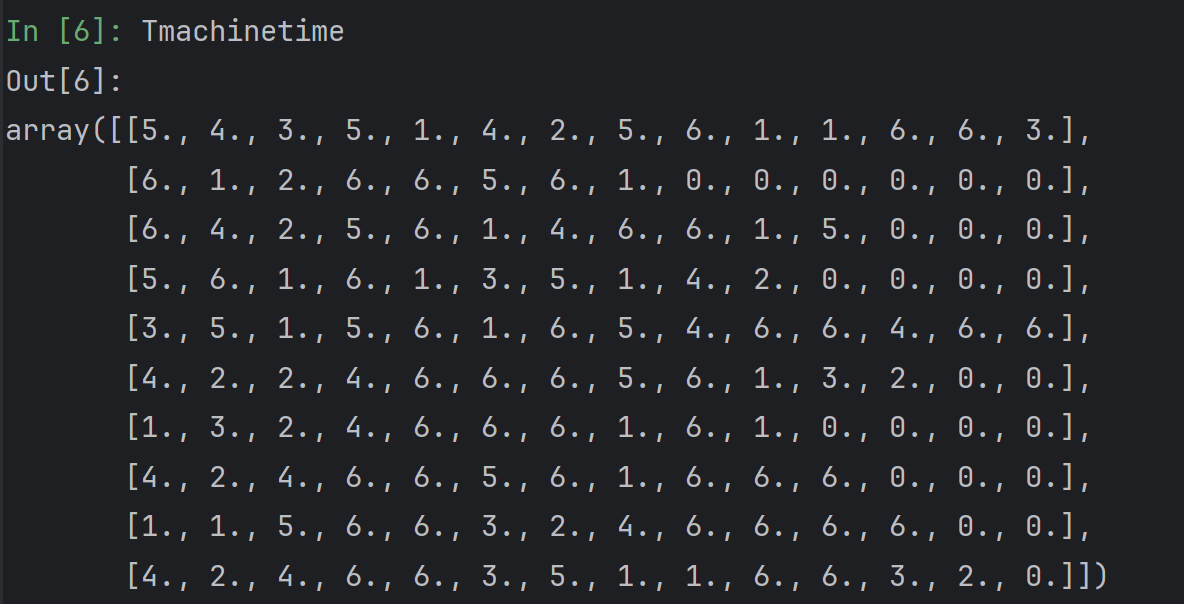
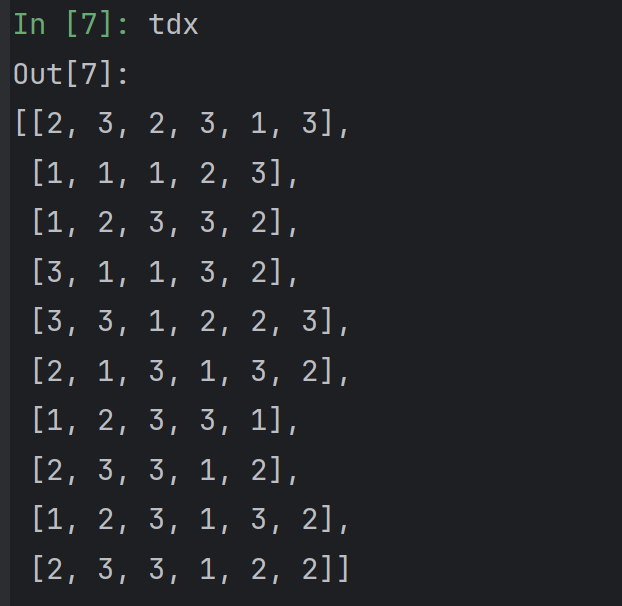
tdx表示每个工序可选的机器数量,比如第一个零件的第一个工序可以选择2台机器加工。而且tdx[0]的长度表示了零件0需要有6个工序才能加工完成。
ABC算法
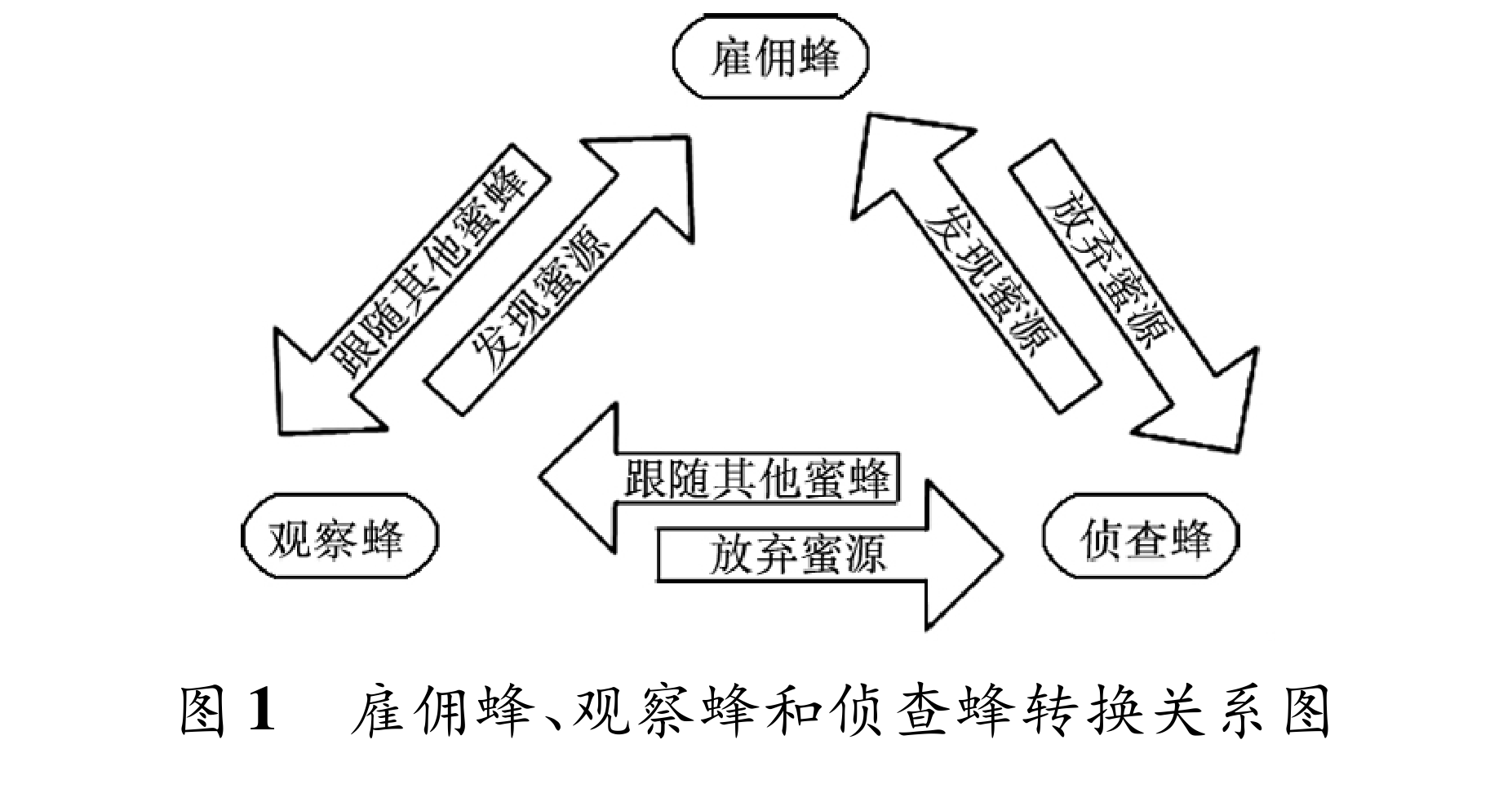
ABC(Artificial Bee Colony)算法是一种启发式优化算法,模拟了蜜蜂在寻找食物过程中的行为。这个算法由三种类型的蜜蜂组成:雇佣蜂、观察蜂和侦查蜂。
-
雇佣蜂:雇佣蜂负责在已知的蜜源周围搜索,它们相当于解决问题的候选解。每个蜜源都对应一个雇佣蜂,它们具有记忆功能,能够存储搜索到的蜜源信息,并根据蜜源的好坏与观察蜂分享信息。
-
观察蜂:观察蜂接收雇佣蜂分享的蜜源信息,并选择其中满意的蜜源进行跟随。观察蜂的数量与雇佣蜂相等。
-
侦查蜂:侦查蜂负责搜索新的蜜源位置,以保持算法的多样性和全局搜索能力。
这三种蜜蜂之间可以相互转换,以达到更好的搜索效果。ABC 算法通过模拟蜜蜂群体的这种协作和信息共享机制,实现了对优化问题的求解。
编码解码
ABC算法是一种启发式优化算法,最初用于处理连续解空间的问题。然而,在柔性作业车间调度这种离散问题中,标准的ABC算法并不直接适用。因此,我们需要对问题进行适当的编码和解码。
针对柔性作业车间调度问题,我们采用双层编码的形式:
-
工序串编码:这一层编码用于确定工序的加工顺序。比如,考虑一个工序串[3 1 2 1 2 2],它表示了不同工件的工序顺序。在这个串中,数字代表工件号,数字出现的次数表示该工件有多少个工序。比如,在串中的第一个数字3表示工件3的第一个工序,第一个数字1表示工件1的第一个工序。因此,工序串的加工顺序为:O31 → O11 → O21 → O12 → O22 → O23。
-
机器串编码:这一层编码表示每个工序选择的机器。比如,机器串编码[2 2 1 1 3 3]表示了每个工序选择的机器编号。在这个串中,数字代表机器编号,按工件序号和工序顺序排列。比如,在串中的第一个位置的数字2表示工序O11选择了机器M2进行加工,第五个位置的数字1表示工序O23选择了机器M1进行加工。
通过这样的双层编码,我们可以将柔性作业车间调度问题转化为一个适合ABC算法处理的问题。
在代码种,对应为:
class FJSP():def __init__(self, job_num, machine_num, P_GLR, parm_data, P_MSR):self.job_num = job_num # 工件数self.machine_num = machine_num # 机器数self.p1 = P_GLR[0] # 全局选择的概率self.p2 = P_GLR[1] # 局部选择的概率self.Tmachine, self.Tmachinetime, self.tdx, self.work, self.tom = parm_data[0], parm_data[1], parm_data[2], \parm_data[3], parm_data[4]self.machines = parm_data[5]self.p3 = P_MSR[0] # 剩余负荷最大规则的概率self.p4 = P_MSR[1] # 加工时间最短的概率def creat_Machine(self):job = np.copy(self.work)Ma_time = np.zeros((self.job_num,))machine, machine_time = [], [] # 初始化矩阵a_global = np.zeros((1, self.machine_num))r = np.random.rand()for i in range(self.job_num):a_part = np.zeros((1, self.machine_num))time = 0for j in range(self.machines[i]):highs = self.tom[i][j]lows = self.tom[i][j] - self.tdx[i][j]n_machine = self.Tmachine[i, lows:highs].tolist()n_time = self.Tmachinetime[i, lows:highs].tolist()index_select = []if r < self.p1 or r > 1 - self.p2:for k in range(len(n_machine)):m = int(n_machine[k]) - 1index_select.append(m)t = n_time[k]a_global[0, m] += t # 全局负荷计算a_part[0, m] += t # 局部负荷计算if r < self.p1: # 全局选择select = a_global[:, index_select]idx_select = np.argmin(select[0])else: # 局部选择select = a_part[:, index_select]idx_select = np.argmin(select[0])m_select = n_machine[idx_select]t_index = n_machine.index(m_select)machine.append(m_select)machine_time.append(n_time[t_index])time += n_time[t_index]else: # 否则随机挑选机器index = np.random.randint(0, len(n_time), 1)machine.append(n_machine[index[0]])machine_time.append(n_time[index[0]])time += n_time[index[0]]Ma_time[i] = timereturn machine, machine_time, Ma_timedef creat_job(self):count = np.zeros((1, self.job_num), dtype=np.int_)machine, machine_time, Ma_time = self.creat_Machine()time_last = Ma_time.copy()rember = [sum(self.machines[:i]) for i in range(len(self.machines))]job = []for i in range(len(self.work)):r = np.random.rand()a = np.argwhere(time_last > 0) # 挑选剩余工件加工时间大于0的索引if r < self.p3 + self.p4: # 剩余负荷最大规则和加工时间最短优先规则b = time_last[a].reshape(a.shape[0], ).tolist() # 按照索引取出具体工件的加工时间if r < self.p3: # 剩余负荷最大规则a_index = b.index(max(b))jobb = int(a[a_index, 0])job.append(jobb)else: # 加工时间最短优先规则a_index = b.index(min(b))jobb = int(a[a_index, 0])job.append(jobb)else: # 随机选择规则index = np.random.randint(0, a.shape[0], 1)jobb = int(a[index, 0])job.append(jobb)loc = count[0, jobb]loc1 = rember[jobb] + loctime = machine_time[loc1]time_last[jobb] -= time # 更新剩余工件加工时间count[0, jobb] += 1return job, machine, machine_time
种群初始化
种群初始化对于算法的性能至关重要。如果完全随机生成初始种群,那么初始解的质量可能参差不齐,这会影响算法寻找最优解的速度,可能需要增加迭代次数和种群大小来获得更好的结果,这会增加优化时间。为了解决这个问题,我们采用了随机选择和按规则选择相结合的方法来初始化种群。
在机器串编码中,我们采用了三种初始化规则:全局选择(Global Selection,GS)、局部选择(Local Selection,LS)和随机选择(Random Selection,RS)。GS和LS可以平衡每台机器的负载,提高机器利用率,从而在一定程度上减小初始解的最大完工时间。而具有强随机性的RS可以保证初始解的多样性,能够取得解空间中的任意解。
在工序串编码中,我们采用了三种初始化规则:剩余负荷最大规则(Maximum Residual Load,MRL)、加工时间最短优先规则(Shortest Process Time,SPT)和随机选择(Random Selection,RS)。MRL优先处理剩余加工时间最长的工件,SPT优先处理剩余加工时间最短的工件,而RS则随机选择工序进行排序。
为了更好地平衡这些规则的应用,我们对机器串和工序串生成规则进行了概率分配。具体来说,机器串生成规则GS/LS/RS的选择概率分别为30%、30%和40%,而工序串的生成规则MRL/SPT/RS的选择概率也分别为30%、30%和40%。
这样的概率分配旨在保证算法能够在初始阶段充分利用规则性和随机性,从而获得多样性的初始种群,有利于提高算法的搜索效率和收敛性。
雇佣蜂操作
针对柔性作业车间调度问题,我们对传统的雇佣蜂操作进行了改进,采用了两种交叉方法:IPOX交叉和多点交叉。
IPOX交叉
在IPOX交叉中,我们首先从种群中选择一条工序串作为父代X1,并生成一个0到1之间的随机数。如果随机数小于0.5,则选择全局最优解作为X2;否则,从种群中选择另一条工序串作为X2(但不同于X1)。接下来,我们将工件分为两个互补的工件集R1和R2。然后,我们将X1中包含在R1工件集中的工序号按照在X1中的位置复制到子代C1中,并将X2中包含在R2工件集中的工序按照原顺序插入到C1的空缺处。类似地,我们将X2中包含在R2工件集中的工序号复制到子代C2中,并将X1中包含在R1工件集中的工序按照原顺序插入到C2的空缺处。最后,我们计算子代C1和C2的适应度值,选择适应度值较大的子代作为交叉后的子代,并检查是否需要替换父代X1的适应度值。
多点交叉
多点交叉作用于机器串的交叉操作。首先,我们选择与父代X1工序串对应的机器串作为机器串父代P1,并选择与父代X2工序串对应的机器串作为机器串父代P2。然后,我们随机生成一个由0和1组成的与机器串长度相等的二进制串。接着,我们将P1中与二进制串中与1位置相同的机器号复制到子代S1的相同位置,并将P2中与二进制串中与0位置相同的机器号复制到S1的相同位置。然后,我们将P2中与二进制串中与1位置相同的机器号复制到子代S2的相同位置,并将P1中与二进制串中与0位置相同的机器号复制到S2的相同位置。最后,我们计算子代S1和S2的适应度值,选择适应度值较大的作为机器串多点交叉后的子代,并检查是否需要替换父代P1的适应度值。
这两种交叉方法不会产生非法解,同时能够将父代个体中的优良基因传递到下一代,从而帮助改进解的质量和收敛速度。
观察蜂操作
-
蜜蜂觅食行为:
- 蜜蜂使用轮盘赌选择蜜源的位置,选择概率与蜜源的适应度值成正比。适应度值高的蜜源被选中的概率更大。
- 选择概率的计算使用公式(10),其中fit_w是第w个解的适应度值,D是蜜源的数量,即种群数量的一半。
- 蜜源的适应度值按照公式(12)计算,其中obj_w是蜜源w的目标值。
-
工序串优化:
- 采用变换步长策略对选择的蜜源位置附近进行搜索。大步长交换可行解中多对工序的顺序,增强全局搜索能力,避免陷入局部最优;小步长交换可行解中一对工序的顺序,适合在当前解空间进行更深一步的搜索。
- 为了结合大步长和小步长的优势,设定了一个阈值,当搜索次数小于阈值时进行小步长搜索,反之进行大步长搜索,并在切换时将搜索次数清零。
- 在计算适应度值时,采用贪婪策略选择适应度高的个体,以保留精英个体。
- 对工序串进行插入变异时,从工序串中选择任意一道工序插入到工序串的任意位置,然后按照原有顺序排序,并计算适应度值。同样地,对机器串进行变异操作时,随机选择一道工序,在其可选机器集中随机选择一台机器进行变异,并计算适应度值。最后,采用贪婪策略选择适应度高的染色体保留到下一代种群中。
侦察蜂操作
在标准的ABC算法中,如果雇佣蜂在同一个蜜源上进行了limit次(即达到最大搜索次数)而没有改进,那么它就会转变为侦查蜂。在传统ABC算法中,每次只有一只雇佣蜂会被转变为侦查蜂,而侦查蜂生成的随机解对种群的改进影响较小,不利于算法跳出局部最优解。
因此,在这里提出了一种改进的方法:如果有Y个蜜源经过limit次搜索没有改进,那么就采用种群初始化方法(来自文中第2.2节)生成Y个新的蜜源。通过增加侦查蜂的数量,保持种群的多样性,这有助于提高算法的全局搜索能力。
具体来说,当Y个蜜源达到搜索次数上限时,会生成Y个新的蜜源,以增加算法的搜索空间,从而提高发现更好解的可能性,增强算法的全局搜索能力。
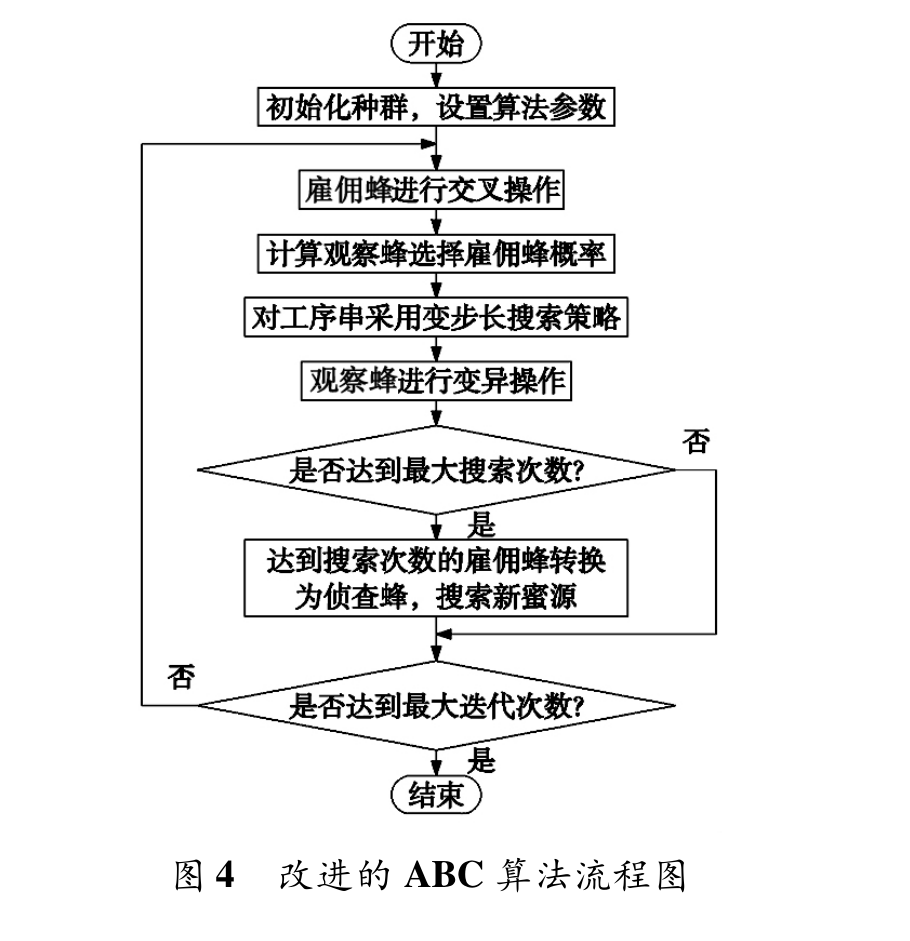
算法流程
- 建立柔性作业车间调度模型。
- 确定调度的约束条件。
- 初始化种群以及设置参数。
- 计算适应度值,雇佣蜂进行 IPOX 交叉和多点交叉操作。
- 计算各蜜源的适应度值,并且计算观察蜂选择跟随各雇佣蜂的概率。
- 观察蜂采用变步长搜索策略,并且进行变异操作。
- 判断蜜源是否达到最大搜索次数,若满足条件则雇佣蜂转换为侦查蜂,搜索新的蜜源,否则进入步骤 8。
- 判断算法是否达到最大迭代次数,如果是则算法结束;如果未达到最大迭代次数,则跳转到步骤 4。
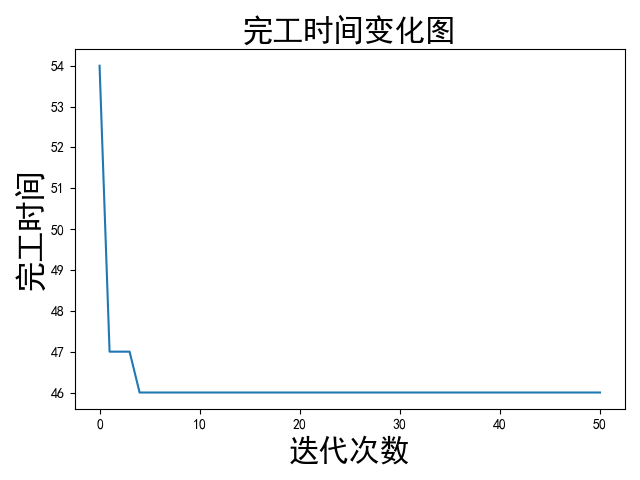
结果
计算这个问题,设置了50轮的答案搜索,完工时间由大变小,体现出算法寻找最优解的变化,整体是收敛的。
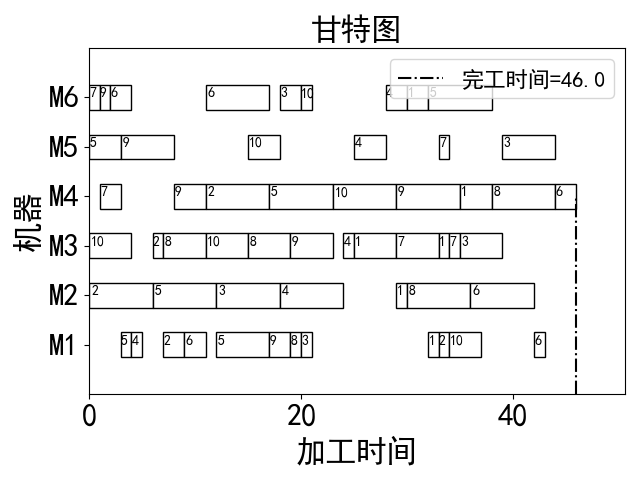
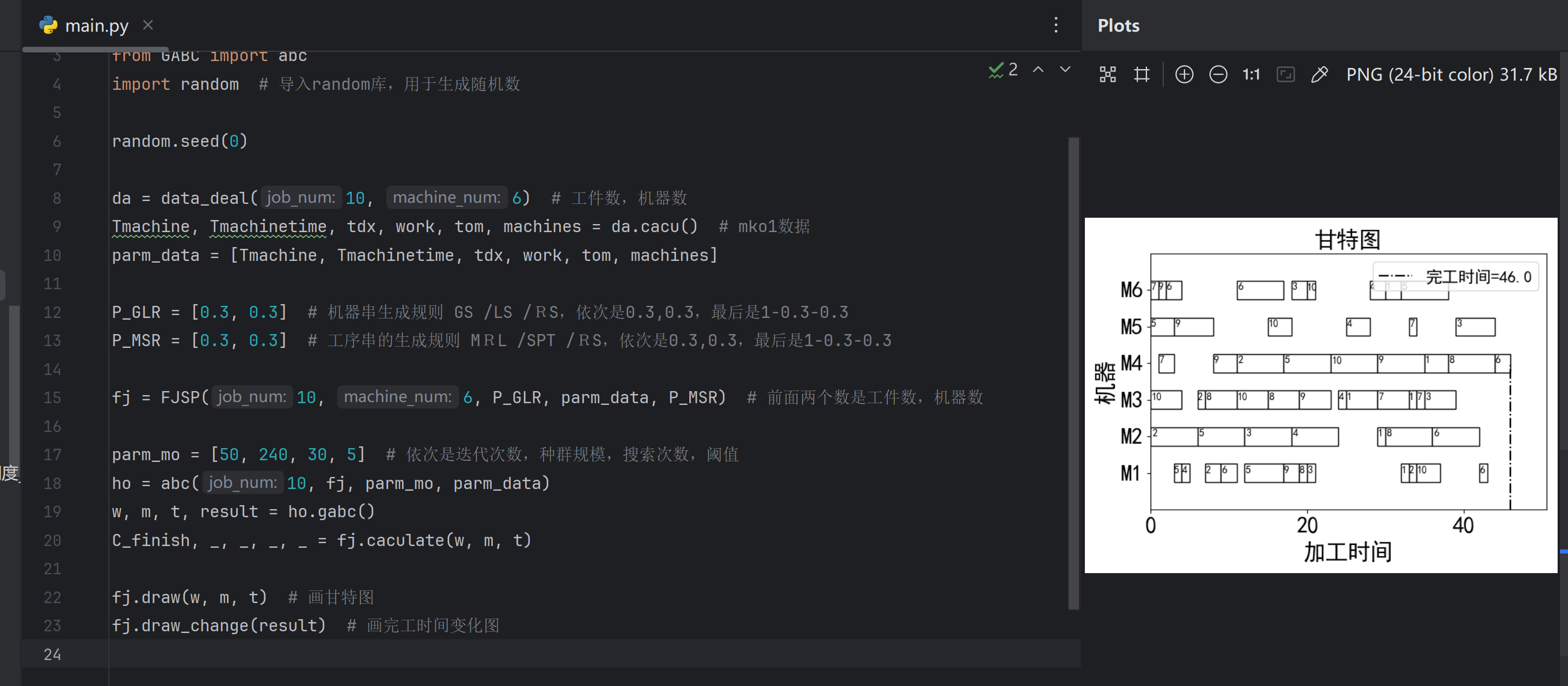
从甘特图种可以看出6台机器如何分配才能达到最优最短的完工时间,比如可以看到机器M1的加工顺序是零件4、零件4、等等。总的完工时间花费是46。
程序截图
用python运行main.py后即可得到甘特图和结果图:
问询、帮助
https://docs.qq.com/sheet/DUEdqZ2lmbmR6UVdU?tab=BB08J2
这篇关于【算法】人工蜂群算法,解决多目标车间调度问题,柔性车间调度问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







