本文主要是介绍15(第十四章,大数据和数据科学),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
概述
基本概念
数据仓库/传统商务智能与数据科学的比较
数据科学的过程
大数据
大数据来源
数据湖
机器学习
监督学习
无监督学习
强化学习
扩展
1、数据仓库(Data Warehouse)
2、数据湖(Data Lake)
3、大数据平台1.0
4、数据中台
5、数据底座
6、湖仓一体化大数据平台(Data Lakehouse)
7、数据仓库、数据湖和湖仓一体的差异
概述
传统的商务智能(BI)提供“后视镜”式的报告,通过分析结构化的数据展示过去的趋势。
信息收敛三角:
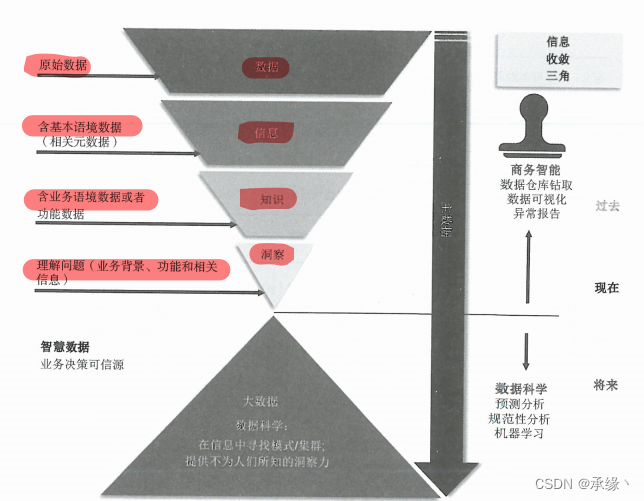
数据科学将数据挖掘、统计分析、机器学习与数据集成整合,结合数据建模能力,去构建预测模型、探索数据内容模式。因为数据分析师或数据科学家会使用一些科学的方法来开发和评估模型,所有开发预测模型有时被称为数据科学。
基本概念
数据仓库/传统商务智能与数据科学的比较
| 数据仓库/传统商务智能 | 数据科学 | |
|---|---|---|
| 描述性分析 | 预测性分析 | 规范性分析 |
| 事后结论 | 洞察 | 预见 |
| 基于历史: 过去发生了什么? 为什么发生? | 基于预测模型: 未来可能会发生什么? | 基于场景: 我们该做什么才能保证事情发生? |
数据科学的过程
- 定义大数据战略和需求
- 选择数据源
- 获得和接收数据源
- 制定数据假设和方法
- 集成和调整进行数据分析
- 使用模型探索数据
- 部署和监控
大数据
早期通过3V来定义大数据的特征:数据量大(Volume)、数据更新快(Velocity)、数据类型多样/可变(Variety)。
后来V列表有了更多的扩展:
- 数据量大 (Volume)。大数据通常拥有上千个实体或数十亿个记录中的元素。
- 数据更新快 (Velocity)。指数据被捕获、生成或共享的速度。大数据通常实时地生成、分发及进行分析。
- 数据类型多样/可变(Variety/Variability)。指抓取或传递数据的形式。大数据需要多种格式储存。通常,数据集内或跨数据集的数据结构是不一致的。
- 数据黏度大(Viscosity)。指数据使用或集成的难度比较高
- 数据波动性大 (Volatility)。指数据更改的频率,以及由此导致的数据有效时间短
- 数据准确性低 (Veracity)。指数据的可靠度不高。
大数据来源
来源于结构化数据和非结构化数据。
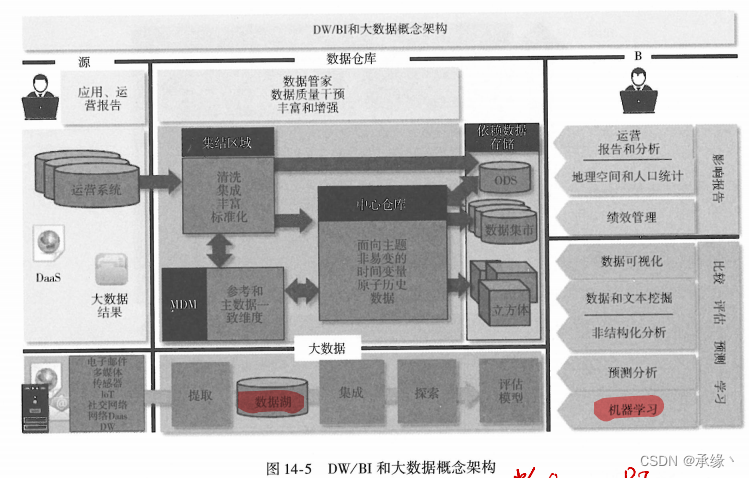
从上图其实我们能看出来:
数据仓库是面向BI的;
数据科学是面向AI的。
数据湖
数据湖是一种可以提取、存储、评估和分析不同类型和结构海量数据的环境,可供多种场景使用。例如,它可以提供:
- 数据科学家可以挖掘和分析数据的环境。
- 原始数据的集中存储区域,只需很少量的转换 (如果需要的话)。
- 数据仓库明细历史数据的备用存储区域。
- 信息记录的在线归档。
- 可以通过自动化的模型识别提取流数据的环境。
数据湖的风险在于,它可能很快会变成数据沼泽一一杂乱、不干净、不一致。为了建立数据湖中的内容清单,在数据被摄取时对元数据进行管理至关重要。
机器学习
预测分析是有监督学习的子领域,规范分析比预测分析更进一步。
监督学习
基于通用规则,例如将SPAM邮件与非SPAM邮件区分开,这种结果是有限制的,刚刚那个例子,结果就是“是”或“否”。
无监督学习
基于找到的哪些隐藏的规律(数据挖掘),结果是无限的,例如让他去预测明年的销售业绩是多少这种。
强化学习
基于目标的实现,例如让他在国际象棋中击败对手。
扩展
我们凑这篇文章,介绍下数据仓库、大数据平台、数据湖、数据中台、数据底座、湖仓一体化大数据平台的差异。
1、数据仓库(Data Warehouse)
听过很多次了,数据仓库是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。数据仓库是数据库的一种概念上的升级,可以说是为满足新需求而设计的一种新数据库,能容纳更加庞大的数据集。
2、数据湖(Data Lake)
数据湖是将来自不同数据源、不同数据类型(结构化、半结构化、非结构化)的数据,以原始格式存储进行存储的系统,并按原样存储数据,而无需事先对数据进行结构化处理。是各种原始数据的集合(不产生数据),原则上不对数据进行清洗、整合(不能对业务数据进行修改),入湖数据需要进行注册(经过流程制度的处理,如确定数据Owner,满足要求)。
3、大数据平台1.0
个性化、多样化数据,以处理海量数据存储、计算及流数据实时计算等场景为主的一套基础设施,以 Hadoop、Spark、Hive 等作为大数据基础能力层,在大数据组件上搭建包括数据分析、机器学习程序等 ETL 流水线,另外可以包括数据仓库系统等核心功能。
4、数据中台
阿里提出的中国本地的一个概念,数据中台是企业级数据能力共享平台,提供企业级数据服务,实现数据共享。数据通过分层与水平解耦,经过汇聚、存储、整合、分析、加工,沉淀公共的数据能力,再经过服务封装,形成通用的调用接口,为前端应用提供数据服务调用,支撑前端应用敏捷迭代和快速构建。数据直接用于业务链路和交易场景, 服务更多业务。数据中台不是一个标准化的产品,是一整套策略和解决方案的集合。
5、数据底座
数据底座是企业统一的数据平台,是数据的逻辑集合,由数据湖和数据主题联接两层构成,集成公司内部各个业务系统数据及外部数据,为业务可视、分析、决策等数据消费提供数据服务。数据底座由数据湖和数据主题联接构成。
6、湖仓一体化大数据平台(Data Lakehouse)
是新兴起的一种数据架构,它同时吸收了数据仓库和数据湖的优势,数据分析师和数据科学家可以在同一个数据存储中对数据进行操作,同时它也能为公司进行数据治理带来更多的便利性。就是把面向企业的数据仓库技术与数据湖存储技术相结合,为企业提供一个统一的、可共享的数据底座。
大数据平台1.0+数据中台的功能+数据运营的功能=大数据平台2.0=湖仓一体化大数据平台(简称大数据平台)。
7、数据仓库、数据湖和湖仓一体的差异
数据仓库、数据湖和湖仓一体之间的差异主要体现在以下几点。
- (1)数据类型:数据仓库内部高度结构化且多为关系型数据库,一般只支持在入仓前完成处理工作的结构化数据存储;数据湖可包容开放的数据类型,但其主要存储原始格式的数据,数据加工处理属于额外工作;湖仓一体存储所有类型的已处理和原格式数据。
- (2)采集过程:数据仓库的写时模式需在数据入仓前预先建模,并按照既定的ETL模式,以专属格式导入;数据湖的读时模式在数据入湖后按需定义架构,湖中数据以开放格式存在以适应多变的业务需求,ELT;湖仓一体同时支持预定义数据和开放数据导入以及需求导向的数据加工转换。
- (3)访问方式:数据仓库内的数据访问以SQL(Structured Query Language)为主,用户可以获取具有专属格式的数据;数据湖和湖仓一体配置大量开放API,可支持对数据的直接读取,读取方式包括SQL、 R、Python等语言,湖仓一体同时支持原格式和处理后数据的访问。
- (4)可靠性和安全性:数据仓库发展较为成熟,基于其高度结构化的管理能力,可实现高质量和安全性的数据存储;数据湖内部数据具有多源异构性,尚未形成有效治理策略,易导致数据沼泽,这也是其当前面临的最大挑战;湖仓一体在湖存储机制上添加数据仓库管理功能和数据安全保障机制,可显著提高数据可靠性和安全性。
- (5)适用场景:数据仓库适用于BI(Business Intelligence)、SQL应用和报告等;数据湖适用于数据科学和机器学习,二者仅支持有限应用场景;湖仓一体可同时满足SQL分析需求和数据科学、机器学习等高级分析需求,且支持直接在原始数据上应用各类分析工具,以及对流数据的持续处理和实时分析。
| 数据类型 | 采集过程 | 访问方式 | 可靠性和安全性 | 使用场景 | |
|---|---|---|---|---|---|
| 数据仓库 | 结构化、已处理数据 | 写时模式 | SQL为主,支持API | 数据质量高、安全性高 | BI |
| 数据湖 | 结构化、半结构化、非结构化原始数据 | 读时模式 | 开放API | 数据质量低、安全性低、易形成数据沼泽 | AI |
| 数仓一体 | 结构化、半结构化、非结构化原始数据 | 写时模式、读时模式 | 开放API | 数据质量高、安全性高 | 丰富场景 |
这篇关于15(第十四章,大数据和数据科学)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





