本文主要是介绍零基础机器学习|逻辑回归(判断客户是否患病),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、逻辑回归本质
从回归问题到分类问题,比如是1否0患病,是1否0可以贷款等
机器学习的分类过程就是可能性大小的过程
用线性回归函数+阶跃函数实现分类。如果单纯的用分类线实施分类会造成有些点预测的误差大,而回归函数对于一些靠近0、1 的点既是中间点不能很好的分类预测,于是引入sigmoid函数,样本越靠近分类阈值,函数对它们越来越敏感如下图
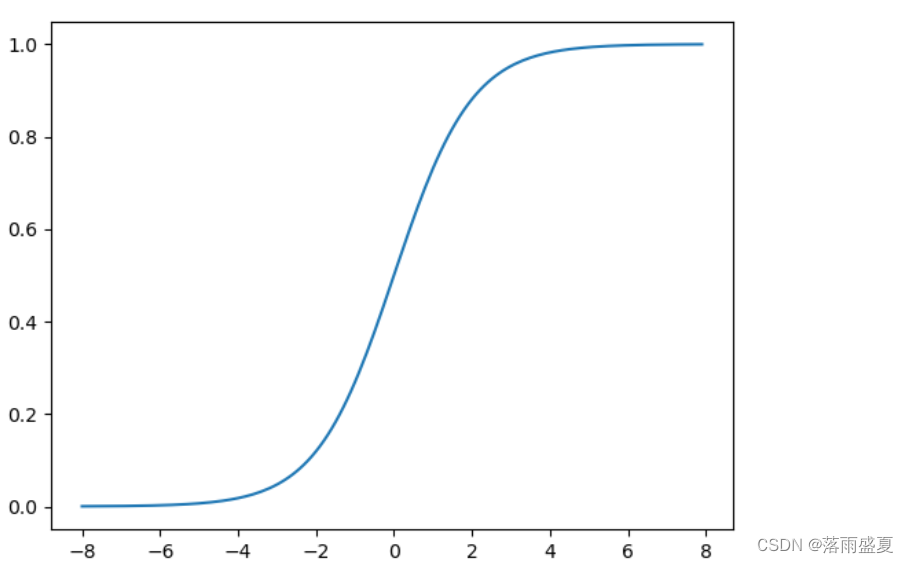
对于这种s型函数,我们称为logistic function 即为逻辑函数,请注意logic function 和logistic function不是同一个东西
sigmoid函数的公式 g ( z ) = 1 1 + e − z g(z) = {\frac{1}{1+e^{-z}}} g(z)=1+e−z1 与线性回归模型的式子 z = w 0 x 0 + w 1 + x 1 + . . . . + w n x n + b = W T X z = w_0x_0+w_1+x_1+....+w_nx_n+b = W^TX z=w0x0+w1+x1+....+wnxn+b=WTX联立得到 h ( x ) = 1 1 + e − ( W T X ) h(x) = {\frac{1}{1+e^{-(W^TX)}}} h(x)=1+e−(WTX)1既是逻辑回归的假设函数,想象一下上述表示的图像为线性回归函数+阶跃函数。
二、损失函数与梯度下降函数使用logisticRegression
对照之前的线性回归函数的损失函数,我们自定义了loss function和gradient_descent ,对于这里的逻辑回归函数我们并不能直接使用,要增加sigmoid的函数细节这里不过多展示代码细节,因为对于数据集来说,容易出现迭代次数过多导致的过拟合(后续正则化处理)现象,所以我们直接调用python中封装好的逻辑回归模型进行数据的训练,代码如下
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(X_train,y_train)
print("Sk learn逻辑回归准确率为{:.2f}".format(lr.score(X_test,y_test)*100))
三、哑特征处理
数据集中的中文要处理成数字0,1…这样的形式有助于机器识别,有时候对于转换类型多的数字,比如中毒类型有1,2,3,4种类型,但是与数字大小无关,所以机器就会误以为这是中毒程度去比较,实际上只是一个代号,解决方式就是把一个变量转换成多个哑变量,如下代码
a = pd.get_dummies(df_heart['cp'],prefix = 'cp')
b = pd.get_dummies(df_heart['thal'], prefix = 'thal')
c = pd.get_dummies(df_heart['slope'],prefix = 'slope)
将原始的特征拆分成二进制编码,使用pandas库中的dummies(拆分对象,拆分后的前缀保留名)
说明
导入数据后,调用from sklearn.preprocessing import MinMaxScaler进行数据归一化处理,然后拆分数据调用from sklearn.model_selection import train_test_split ,最后进行逻辑函数库的调用得到最后的测试准确率
四、(优化)正则化,欠拟合,过拟合
正则化(regularization):调整模型,约束权重
调整数据,特征缩放:
1.标准化(normalization):数据正太分布,平均值0,标准差1
2.规范化(standardization):限定在一个范围里面[ 0,1]
1、 拟合问题(过 欠拟合)
过拟合:数据高度重合训练集,无泛化能力到测试集,正则化解决
欠拟合:数据在测试集和训练集的误差都很大,提高迭代次数
2、正则解决
分类:L1 根据权重的绝对值综合来乘法惩罚权重(套索Lasso回归)
L2 根据全权重的平方惩罚权重(岭Ridge回归)
正则化参数——c值
C值越大,分类精度越大,过拟合
C值过小,正则为了追求泛化效果,导致失去区分度
如何选C值
1)选择高的测试集准确率
2)选择训练集和测试集之间准确率小的
以下是关于鸢尾花的花萼花瓣的分类算法,注意观察正则化后调整C参数的准确率
import numpy as np
import numpy as pd
from sklearn import datasetsiris = datasets.load_iris()#获取sklearn里面的鸢尾花数据集
x_sepal = iris.data[:,[0,1]]#全部行+第一二列数据
x_pedal = iris.data[:,[2,3]]
y = iris.target#获取标签值from sklearn.model_selection import train_test_split#数据拆分测试和训练
from sklearn.preprocessing import StandardScaler#标准化
X_train_sepal,X_test_sepal,y_train_sepal,y_test_sepal =train_test_split \(x_sepal,y , test_size = 0.3,random_state=0)
scaler = StandardScaler();
X_train_sepal = scaler.fit_transform(X_train_sepal)
X_test_sepal = scaler.transform(X_test_sepal)
##可以省略以下的标签合并
# X_combined_sepal = np.vstack((X_train_sepal,X_test_sepal))
# Y_combined_sepal = np.hstack((y_train_sepal,y_test_sepal))from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(penalty = 'l2',C = 0.1)#设定正则类型和C参数
lr.fit(X_train_sepal,y_train_sepal)#lr中没有fit_transform
score = lr.score(X_test_sepal,y_test_sepal)
print("SKlearn测试的准确率{:.2f}".format(score*100))from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(penalty = 'l2',C = 10)#设定正则类型L2,和C参数值
lr.fit(X_train_sepal,y_train_sepal)
score = lr.score(X_test_sepal,y_test_sepal)
print("修改C后SKlearn测试的准确率{:.2f}".format(score*100))这篇关于零基础机器学习|逻辑回归(判断客户是否患病)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




