本文主要是介绍4.18.2 EfficientViT:具有级联组注意力的内存高效Vision Transformer,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
现有Transformer模型的速度通常受到内存低效操作的限制,尤其是MHSA(多头自注意力)中的张量整形和逐元素函数。
设计了一种具有三明治布局的新构建块,即在高效FFN(前馈)层之间使用单个内存绑定的MHSA,从而提高内存效率,同时增强通道通信。
注意力图在头部之间具有高度相似性,导致计算冗余。
为了解决这个问题,提出了一个级联的组注意力模块,为注意力头提供完整特征的不同分割。
Transformer模型的速度通常受内存限制。内存访问延迟阻碍了GPU/CPU中计算能力的充分利用,从而对Transformer的运行速度产生严重的负面影响。
内存效率最低的操作是多头自注意力(MHSA)中频繁的张量整形和逐元素函数。通过适当调整MHSA和FFN(前馈网络)层之间的比例,可以在不影响性能的情况下显著减少内存访问时间。
通过向每个头提供不同的特征来显式分解每个头的计算来缓解冗余问题。
为了提高参数效率,我们使用结构化剪枝来识别最重要的网络组件,并总结模型加速参数重新分配的经验指导。
结构化剪枝是在神经网络已经训练好的情况下,按照一定的剪枝策略来修剪掉一部分神经元或连接,从而减少模型的大小,保持模型的精度,形成一个新的更加简单的模型。
结构化剪枝能够直接减少卷积核的参数量和运算量,减少网络运行时的内存占用,不需要特征运算库即可实现运算加速。
EfficientViT
- MBConv模块使用深度可分离卷积,即每个输入通道只与一个卷积核进行卷积,然后再将结果相加,从而减少了参数数量。
- Lighted Multi-scale Self-attention (轻量级多尺度自注意力)
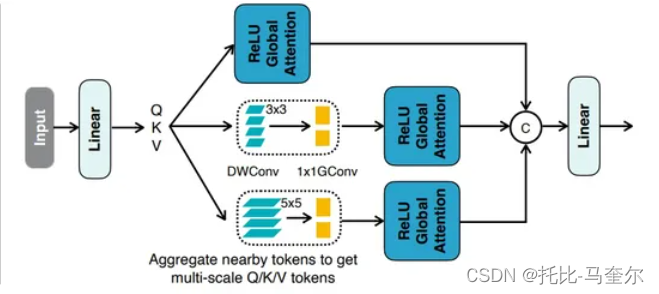
DWConv指的是深度卷积,GConv指的是组卷积。
深度卷积是组卷积的极端情况,即分组数g等于输入通道数cin,也等于输出通道数cout
组卷积常用在轻量型高效网络中,因为它用少量的参数量和运算量就能生成大量的feature
map,而大量的feature map意味着能够编码更多的信息。
组卷积指的是什么:
组卷积是将输入特征图分成多个组,然后在每个组内进行卷积操作,最后将每个组的输出特征图拼接起来作为最终的输出特征图
假设输入特征图的通道数为C,组数为G,每组的通道数为C/G,那么组卷积的操作可以表示为
- 将输入特征图分成G组,每组包含C/G个通道。
- 对每个组进行卷积操作,得到每组的输出特征图。
- 将G个组的输出特征图拼接起来,得到最终的输出特征图。
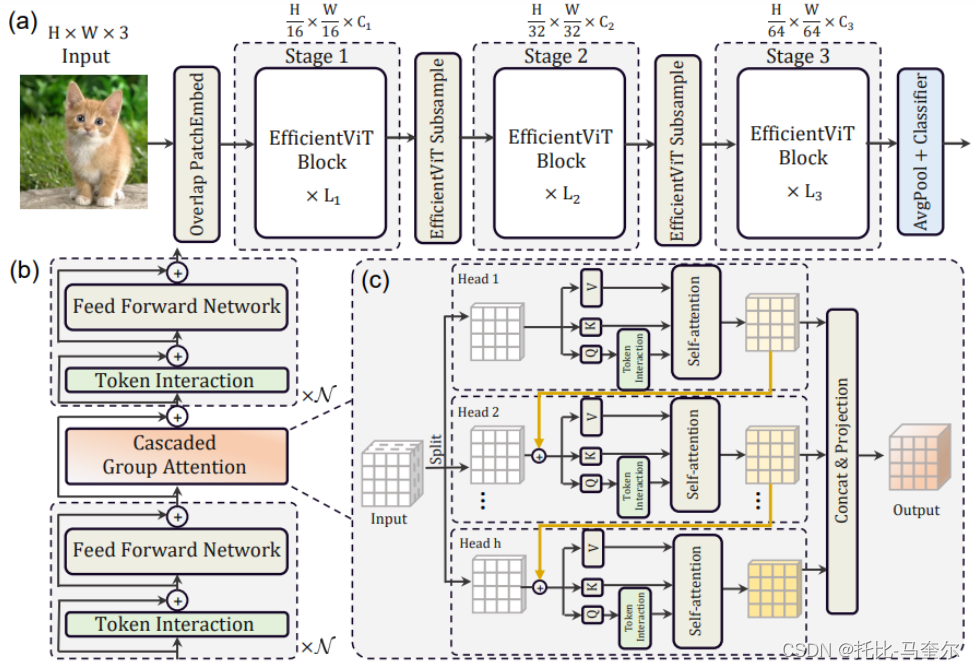
设计一个具有三明治布局的新块来构建模型:
三明治布局块在FFN层之间应用单个内存绑定的MHSA层;
并应用更多的FFN层来允许不同通道之间的通信,从而提高内存效率
内存绑定的MHSA(多头自注意力)层通过优化数据结构和计算流程,减少了内存使用,提高了计算效率。这种优化可能包括更有效的张量整形操作、减少不必要的数据复制、以及使用更紧凑的数据表示等
级联群体注意力(CGA)
与先前对所有头使用相同特征的自注意力相比,CGA为每个头提供不同的输入分割,并将输出特征级联到各个头。
该模块不仅减少了多头注意力中的计算冗余,而且还通过增加网络深度来提高模型容量。我们通过扩大关键网络组件(例如值投影)的通道宽度来重新分配参数,同时缩小重要性较低的组件(例如FFN中的隐藏维度)
使用Vision Transformers加快速度
内存效率
内存访问开销是影响模型速度的关键因素。Transformer中的许多运算符,例如频繁的整形、逐元素加法和归一化,都是内存效率低下的,需要跨不同内存单元进行耗时的访问。
我们通过减少内存效率低下的层来节省内存访问成本。内存效率低下的操作主要位于MHSA(多头注意力)而不是FFN层。然而,大多数现有的ViT使用相同数量的两层,无法达到最佳效率。
事实证明,适当降低MHSA层利用率可以在提高模型性能的同时提高内存效率。
这篇关于4.18.2 EfficientViT:具有级联组注意力的内存高效Vision Transformer的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




