本文主要是介绍yolact模型推理导出ONNX环境搭建,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文使用的anaconda安装版本是:
anaconda下keras&tensorflow @ubuntu18.04开发环境安装_tugouxp的专栏-CSDN博客前面尝试在windows10上安装keras&tensorflow开发环境,总体上感觉还是比较麻烦的,今天抽时间在ubuntu18.04上安装了一把,很快就搞定了回归训练的模型,发现anaconda对Linux环境是比较友好的,以后可以在Linux下干活了。现在简要介绍一下搭建环境并执行回归训练用例的过程下载anaconda我选择的版本是https://repo.anaconda.com/archive/Anaconda3-2020.11-Linux-x86_64.shhttps:/https://blog.csdn.net/tugouxp/article/details/120464891?spm=1001.2014.3001.5502yolact下载地址:
git clone https://github.com/dbolya/yolact.git
安装环境:
cd yolact,执行
conda env create -f environment.yml

下载模型权重:


运行测试用例:
python eval.py --trained_model=weights/yolact_base_54_800000.pth --score_threshold=0.15 --top_k=15 --images=/home/czl/images/:/home/czl/out
添加上--cuda=False也于事无补。
python -m eval --trained_model=./weights/yolact_darknet53_54_800000.pth --cuda=False --score_threshold=0.4 --top_k=15 --display --image=/home/caozilong/darknet/data/dog.jpg:output3.jpg
似乎走到的死胡同。
由于我们下载的是非GPU版本的pytorch,所以出现了上图中的错误,接下来换一套CPU版本的yolact环境尝试一下,yolact CPU版本的实现在另一个地址:
git clone -b add-evaluation-without-cuda-support https://github.com/ar90n/yolact.git
将权重文件拷贝过来:

执行conda activate yolact-env激活anaconda yolact环境,再次执行命令:
python -m eval --trained_model=./weights/yolact_darknet53_54_800000.pth --cuda=False --score_threshold=0.4 --top_k=15 --display --image=/home/caozilong/darknet/data/dog.jpg:output3.jpg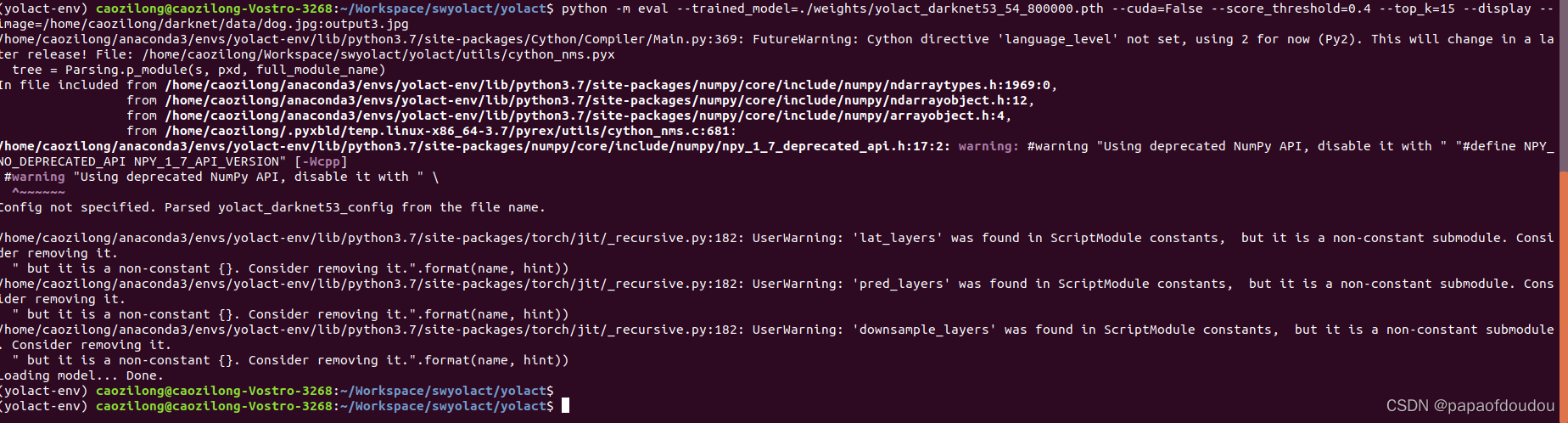
命令成功执行,输出的图片为output3.jpg,打开后结果如下:

换一张图片测试:
python -m eval --trained_model=./weights/yolact_darknet53_54_800000.pth --cuda=False --score_threshold=0.4 --top_k=15 --display --image=/home/caozilong/Workspace/ncnn-origin/ncnn/build/examples/beauty.jpg:girl.jpeg
针对这张图片的召回率和精度有些问题,只框出了一位美女,并且手机也识别错了。

图像:

car.jpeg

导出ONNX模型
根据网上的资料,将代码修改后导出ONNX模型:
diff --git a/eval.py b/eval.py
index e295093..10675d2 100644
--- a/eval.py
+++ b/eval.py
@@ -569,17 +569,19 @@ def evalimage(net:Yolact, path:str, save_path:str=None):batch = FastBaseTransform()(frame.unsqueeze(0))preds = net(batch)- img_numpy = prep_display(preds, frame, None, None, undo_transform=False)
-
- if save_path is None:
- img_numpy = img_numpy[:, :, (2, 1, 0)]
+ torch.onnx._export(net, batch, "yolact.onnx", export_params=True, keep_initializers_as_inputs=True, opset_version=11)- if save_path is None:
- plt.imshow(img_numpy)
- plt.title(path)
- plt.show()
- else:
- cv2.imwrite(save_path, img_numpy)
+ # img_numpy = prep_display(preds, frame, None, None, undo_transform=False)
+
+ # if save_path is None:
+ # img_numpy = img_numpy[:, :, (2, 1, 0)]
+
+ # if save_path is None:
+ # plt.imshow(img_numpy)
+ # plt.title(path)
+ # plt.show()
+ # else:
+ # cv2.imwrite(save_path, img_numpy)def evalimages(net:Yolact, input_folder:str, output_folder:str):if not os.path.exists(output_folder):
diff --git a/yolact.py b/yolact.py
index c1a5b3f..d45d2c0 100644
--- a/yolact.py
+++ b/yolact.py
@@ -23,7 +23,8 @@ if torch.cuda.is_available():torch.cuda.current_device()# As of March 10, 2019, Pytorch DataParallel still doesn't support JIT Script Modules
-use_jit = not torch.cuda.is_available() or torch.cuda.device_count() <= 1
+#use_jit = not torch.cuda.is_available() or torch.cuda.device_count() <= 1
+use_jit = Falseif not use_jit:print('Multiple GPUs detected! Turning off JIT.')@@ -616,7 +617,7 @@ class Yolact(nn.Module):else:pred_outs['conf'] = F.softmax(pred_outs['conf'], -1)- return self.detect(pred_outs)
+ return pred_outs之后运行命令:
python -m eval --trained_model=./weights/yolact_darknet53_54_800000.pth --cuda=False --score_threshold=0.4 --top_k=15 --display --image=/home/caozilong/car.jpeg:car.jpeg
最终生成了ONNX格式的YOLACT模型文件:

端侧部署
将上一步生成的yolact.onnx模型部署到某款NPU上,仿真端跑出的结果,与原来相比,精度略有损失.

而且看trunk目标,显然存在这个区域内识别除了两个目标,从打印也可以看出来:
![]()
可以看到,还有一个置信度为57%的目标被识别出来,这就很奇怪了,从绘制的框可以看出,很明显两个框的IOU已经非常非常高了,几乎重合,不仔细看几乎看不出来是两个框,为何NMS去重时没有去掉其中一个呢?
原来NMS去重的前提是识别的是同一类目标,如果目标不是同一类,即便两个框完全一样,也是都要数出来的.根据上图的打印可以看出,这个范围识别出来的两个目标class id是不同的,分别是3和8,这就不足为奇了。
如何提高精度:
RGB数据送入网络前,要经过前处理归一化,之后再进行量化,所以,送入网络的是量化的数据。这里面可以操作的是归一化参数,上面的推理,我们默认使用了归一化参数为 0 和 0.0039,这样0-256范围的RGB数据经过处理后变为了0-1区间,效果既然不好,我们重新调整参数,另一个普遍被使用的归一化系数(实际上由训练的数据集决定)为:103.94, 116.78, 123.68. 0.017423.我们用它进行尝试:
置信度大大提高,狗的的识别出现了误识别情况,这可能和我导出的模型有关了。

关于这些归一化参数的来源,可以参考原始代码的config.py文件,可能yolact算法是基于imagenet数据集训练的吧。

pytorch模型格式
.pt,pth,.pkl是pytorch框架支持的输出模型格式,上面介绍的模型用的就是.pth格式的模型文件,如同onnx模型一样,.pth模型也是权重和模型结构描述保存在同一个文件中的。利用netron工具,可以直接打开.pth格式的模型文件,比如,github中的yolact模型实际上提供好几个模型文件,它们的主要区别是模型主干结构不同.


貌似对PTH的支持并不友好,实际上,netron官网给出的支持列表并不包含.pth文件,而是给出的.pt文件,.pt文件是可以看到层间的连接关系的.
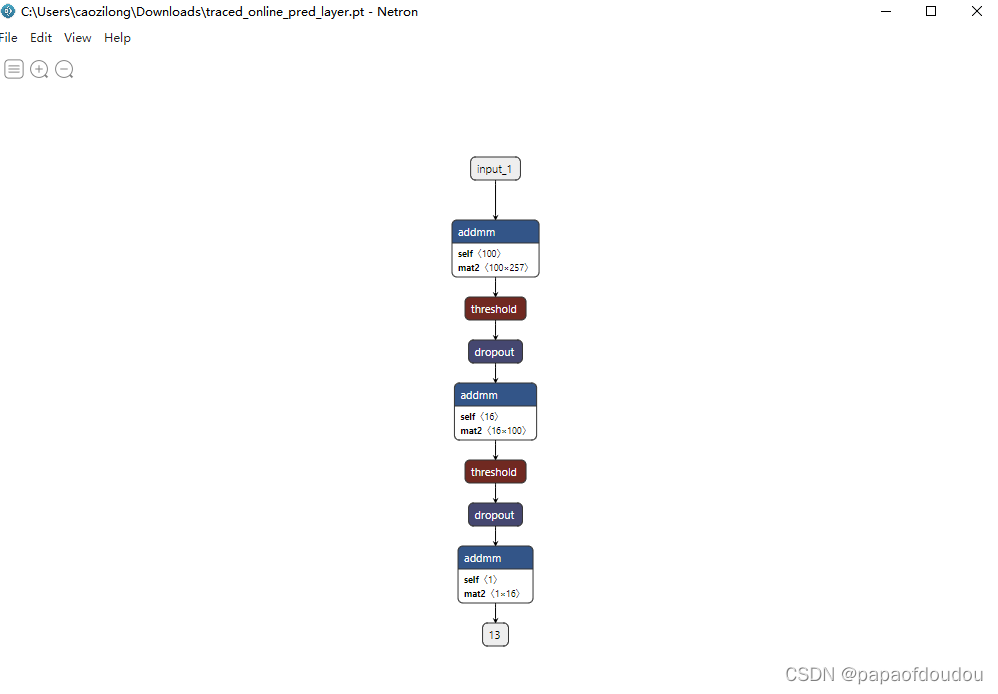
这样也可以理解一个问题,就是芯原微的部署工具不支持.pth,但是支持.pt,.pth的模型需要先转换成.pt,才能被部署工具导入,或许原因就在于此吧。
使用其余模型进行推理:
python -m eval --trained_model=./weights/yolact_base_54_800000.pth --cuda=False --score_threshold=0.4 --top_k=15 --display --image=/home/caozilong/car.jpeg:car.jpeg
模型文件yolact_im700_54_800000.pth
python -m eval --trained_model=./weights/yolact_im700_54_800000.pth --cuda=False --score_threshold=0.4 --top_k=15 --display --image=/home/caozilong/car.jpeg:car.jpeg
yolact_resnet50_54_800000.pth
python -m eval --trained_model=./weights/yolact_resnet50_54_800000.pth --cuda=False --score_threshold=0.4 --top_k=15 --display --image=/home/caozilong/car.jpeg:car.jpeg
结束~!
这篇关于yolact模型推理导出ONNX环境搭建的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








