本文主要是介绍pytest数据驱动DDT,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
常见的DDT技术
数据结构:
列表、字典、json串
文件:
txt、csv、xcel
数据库:
数据库链接
数据库提取
参数化:
@pytest.mark.parametrize()
@pytest.fixture()
DDT参数化
- DDT技术和@pytest.mark.parametrize参数化结合
- DDT技术和conftest.py结合
DDT上面两种方法不要混用。
- 要么:import+@pytest.mark.parametrize参数化:可以设置一个单独的数据驱动层,存放数据文件和数据驱动。团队成员需要数据时,直接import 然后使用
- 要么:使用conftest.py+@pytedt.fixture。conftest.py原理是,运行pytest项目之前,默认优先执行同级目录下的conftest.py文件,数据处理完后,加上固件
一、@pytest.mark.parametrize
1.数据库驱动(已安装MySQL)
安装mysqlclient模块
brew install mysql pkg-config //windows不用该步骤
pip3 install mysqlclient
import MySQLdb # 必须要安装mysqlclient模块
import pytest# 数据库链接
conn = MySQLdb.connect(user='root',passwd='m****',host='localhost',port=3306,db='basejnu' # 数据库database
)def get_data():query_sql = "select customer_id,account_num,customer_region_id from customer LIMIT 20" # 获取数据lst = []cursor = conn.cursor() # 创建游标try:cursor.execute(query_sql)r = cursor.fetchall() # 获取customer_id,account_num数据print(r)for x in r:u = (x[0], x[1]) # 第一列和第二列lst.append(u)return lstfinally:cursor.close()conn.close()@pytest.mark.parametrize('customer_id,account_num', get_data())
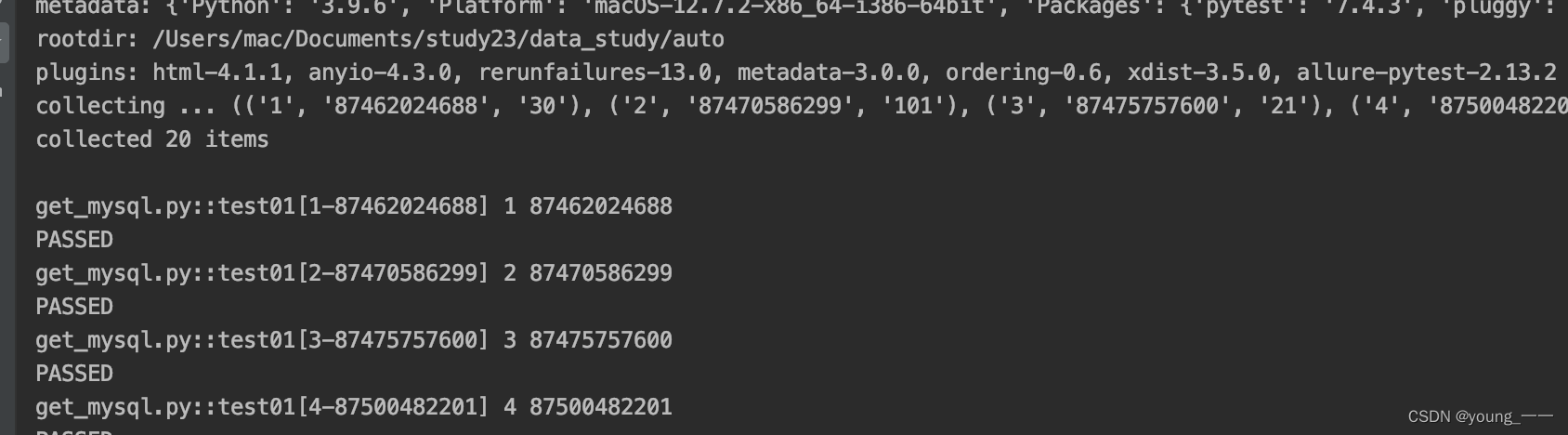
def test01(customer_id, account_num):print(customer_id, account_num)if __name__ == '__main__':pytest.main(["-sv", "get_mysql.py"])
运行效果:
2. execl数据驱动
安装pandas模块
pip3 install pandasimport pandas as pd
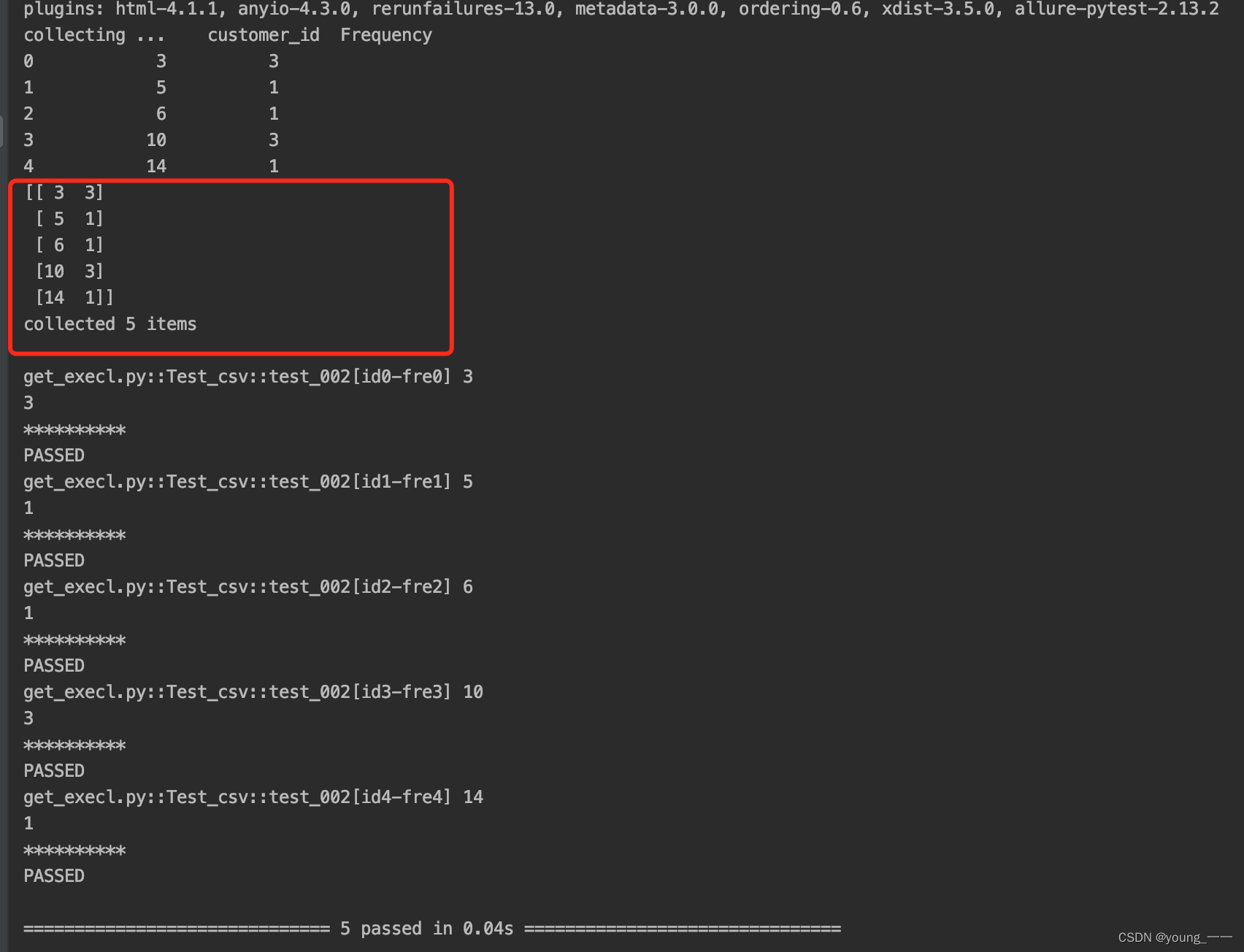
import pytestdef get_data():df = pd.read_csv('/Users/mac/Documents/study23/data_study/data/customer1997.csv', index_col=None)data = pd.DataFrame(df) # 转化为列表data00 = data[['customer_id', 'Frequency']] # 获取所需部分# data01 = data00.head() # 获取全部数据data01 = data00.head(5) #获取前5行数据print(data01)data02 = data01.valuesprint(data02)return data02class Test_csv():@pytest.mark.parametrize('id,fre', get_data())def test_002(self, id, fre):print(id)print(fre)print("*"*10)if __name__ == '__main__':pytest.main(["-sv", "get_execl.py"])运行效果:
3. yaml数据驱动
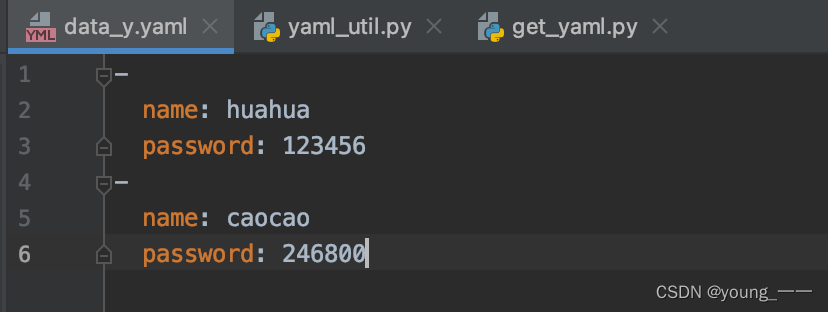
data_y.yaml
yaml_util.py
import yamlclass YamlUtil:def __init__(self, yaml_file):"""通过init方法把Yaml文件传入到这个类:param yaml_file:"""self.yaml_file = yaml_file# 读取Yaml文件def read_yaml(self):"""读取Yaml,对yaml反序列化,就是把我们的yaml格式转换成dict格式:return:"""with open(self.yaml_file, encoding='utf-8')as f:value = yaml.load(f, Loader=yaml.FullLoader)return value测试用例get_yaml.py
import pytest
import os
from common.yaml_util import YamlUtil# 文件地址
realpath = os.path.abspath(os.path.join(os.path.dirname(os.path.split(os.path.realpath(__file__))[0]), '.'))
# 项目地址
project_dir = os.path.dirname(realpath)@pytest.mark.parametrize('args', YamlUtil(project_dir + '/data_study/data/data_y.yaml').read_yaml())
def test_01_huahua(args):name = args['name']password = args['password']print(name)print(password)if __name__ == '__main__':pytest.main(['-vs', "get_yaml.py"])
运行结果:

二、DDT技术和conftest.py结合
pytest有更方便的管理数据驱动方法的办法:conftest.py
conftest.py特点:
1.conftest.py名字固定的,不可以修改
2.conftest.py文件所在目录必须存在__init__py文件
3.conftest.py文件不能被其他文件导入
4.所有同目录测试文件运行前都会执行conftest.py文件
conftest.py一般和@pytest.fixture()固件放在一起使用
conftest原理是,运行pytest项目之前,默认优先执行当前层的conftest.py文件,数据处理完后,加上固件赋予直接传参的能力.注意;如果想conftest.py对所有文件都生效的话,一般建在根目录下
这篇关于pytest数据驱动DDT的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




