本文主要是介绍【nougat推理】pdf转markdown文件代码demo示例web_demo示例,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 模型介绍
- 安装依赖
- 直接使用
- 搭建web并生成.md文件
- 测试结果
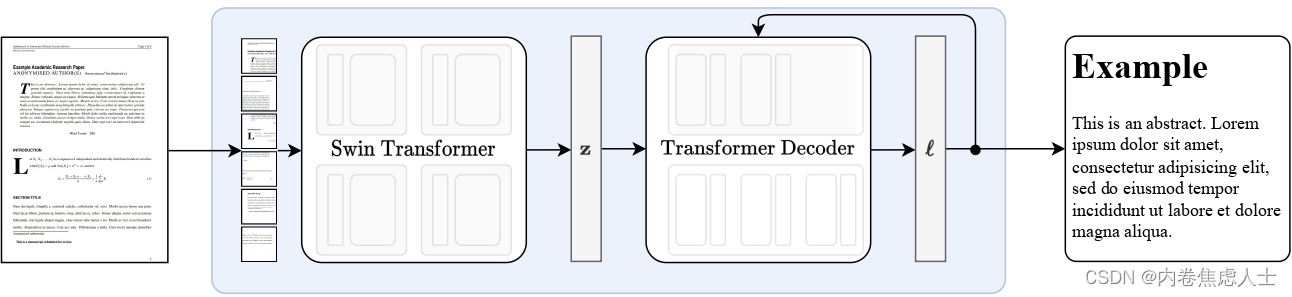
模型介绍
Nougat是一个名为Donut的模型,它经过训练,可以将PDF文档转录成Markdown格式文档。该模型由Swin Transformer作为视觉编码器,以及mBART模型作为文本解码器组成。
该模型被训练成在只给出PDF图像像素作为输入的情况下,自回归地预测Markdown格式。
https://huggingface.co/facebook/nougat-base
安装依赖
pip install nltk python-Levenshtein
pip install spaces
pip install git+https://github.com/facebookresearch/nougat
直接使用
from huggingface_hub import hf_hub_download
import re
from PIL import Image
from pdf2image import convert_from_path
from transformers import NougatProcessor, VisionEncoderDecoderModel
from datasets import load_dataset
import torch
import osprocessor = NougatProcessor.from_pretrained("/your/model/path/nougat-base")
model = VisionEncoderDecoderModel.from_pretrained("/your/model/path/nougat-base")device = "cuda"
model.to(device)# prepare PDF image for the model
pdf_file = 'your/pdf_data/path/xxx.pdf'
pages = convert_from_path(pdf_file, 300) # 300 是输出图片的 DPI(每英寸点数)
# 创建保存图片的目录
output_dir = os.path.join(os.path.dirname(pdf_file), 'images')
os.makedirs(output_dir, exist_ok=True)for i, page in enumerate(pages):image_path = os.path.join(output_dir, f'page_{i + 1}.jpg')page.save(image_path, 'JPEG')image = Image.open(image_path)print("*"*30,f"第{i}页","*"*30)pixel_values = processor(image, return_tensors="pt").pixel_values# generate transcription (here we only generate 30 tokens)outputs = model.generate(pixel_values.to(device),min_length=1,max_new_tokens=3000,bad_words_ids=[[processor.tokenizer.unk_token_id]],)sequences = processor.batch_decode(outputs, skip_special_tokens=True)for sequence in sequences:sequence = processor.post_process_generation(sequence, fix_markdown=False)# note: we're using repr here such for the sake of printing the \n characters, feel free to just print the sequenceprint(repr(sequence))
搭建web并生成.md文件
from huggingface_hub import hf_hub_download
import re
from PIL import Image
import requests
from nougat.dataset.rasterize import rasterize_paper
from transformers import NougatProcessor, VisionEncoderDecoderModel
import torch
import gradio as gr
import uuid
import os
import spacesprocessor = NougatProcessor.from_pretrained("/your/model/path/nougat-base")
model = VisionEncoderDecoderModel.from_pretrained("/your/model/path/nougat-base")device = "cuda" if torch.cuda.is_available() else "cpu"
model.to(device) def get_pdf(pdf_link):unique_filename = f"{os.getcwd()}/downloaded_paper_{uuid.uuid4().hex}.pdf"response = requests.get(pdf_link)if response.status_code == 200:with open(unique_filename, 'wb') as pdf_file:pdf_file.write(response.content)print("PDF downloaded successfully.")else:print("Failed to download the PDF.")return unique_filename@spaces.GPU
def predict(image):#为模型准备PDF图像image = Image.open(image)pixel_values = processor(image, return_tensors="pt").pixel_valuesoutputs = model.generate(pixel_values.to(device),min_length=1,max_new_tokens=3000,bad_words_ids=[[processor.tokenizer.unk_token_id]],)page_sequence = processor.batch_decode(outputs, skip_special_tokens=True)[0]page_sequence = processor.post_process_generation(page_sequence, fix_markdown=False)return page_sequencedef inference(pdf_file, pdf_link):if pdf_file is None:if pdf_link == '':print("未上传任何文件,也未提供任何链接")return "未提供任何数据。上传一个pdf文件或提供一个pdf链接,然后重试!"else:file_name = get_pdf(pdf_link)else:file_name = pdf_file.namepdf_name = pdf_file.name.split('/')[-1].split('.')[0]images = rasterize_paper(file_name, return_pil=True)sequence = ""# 推理每一页并合并for image in images:sequence += predict(image)content = sequence.replace(r'\(', '$').replace(r'\)', '$').replace(r'\[', '$$').replace(r'\]', '$$')with open(f"{os.getcwd()}/output.md","w+") as f:f.write(content)f.close()return content, f"{os.getcwd()}/output.md"css = """#mkd {height: 500px; overflow: auto; border: 1px solid #ccc; }
"""with gr.Blocks(css=css) as demo:gr.HTML("<h1><center>Nougat模型推理PDF转Markdown 🍫<center><h1>")with gr.Row():mkd = gr.Markdown('<h4><center>上传PDF</center></h4>')mkd = gr.Markdown('<h4><center>提供PDF链接</center></h4>')with gr.Row(equal_height=True):pdf_file = gr.File(label='PDF 📑', file_count='single')pdf_link = gr.Textbox(placeholder='在此处输入arxiv链接', label='Link to Paper🔗')with gr.Row():btn = gr.Button('运行 🍫')with gr.Row():clr = gr.Button('清除输入和输出 🧼')output_headline = gr.Markdown("## Markdown展示👇")with gr.Row():parsed_output = gr.Markdown(elem_id='mkd', value='输出文本 📝')output_file = gr.File(file_types = ["txt"], label="输出文件 📑")btn.click(inference, [pdf_file, pdf_link], [parsed_output, output_file])clr.click(lambda : (gr.update(value=None), gr.update(value=None),gr.update(value=None), gr.update(value=None)), [], [pdf_file, pdf_link, parsed_output, output_file])gr.Examples([["/your/pdf_data/path/xxx.pdf", ""], [None, "https://arxiv.org/pdf/2308.08316.pdf"]],inputs = [pdf_file, pdf_link],outputs = [parsed_output, output_file],fn=inference,cache_examples=True,label='点击下面的任何示例,快速获取 Nougat OCR 🍫结果:')demo.queue()
demo.launch(debug=True,share=True, server_name="192.168.10.60", server_port=7899)测试结果
正常的arxiv上的论文识别效果很好,但是这个只限于英文
对于特殊pdf的识别效果很差,nougat自己的rasterize_paper函数没有pdf2image好
另外文档的排版也会干扰识别结果
这篇关于【nougat推理】pdf转markdown文件代码demo示例web_demo示例的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






