本文主要是介绍【网络爬虫】使用HttpClient4.3.5抓取数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
使用jar——Apache client
下载地址:
http://hc.apache.org/downloads.cgi
结构:

代码结构:
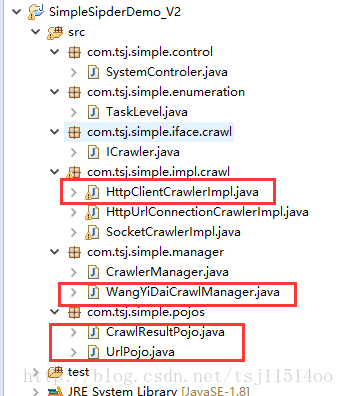
具体代码:
抓取结果封装
/*** 抓取结果的封装* @author tsj-pc**/
public class CrawlResultPojo {private boolean isSuccess;private String pageContent;private int httpStatuCode;public boolean isSuccess() {return isSuccess;}@Overridepublic String toString() {return "CrawlResultPojo [httpStatuCode=" + httpStatuCode+ ", isSuccess=" + isSuccess + ", pageContent=" + pageContent+ "]";}public void setSuccess(boolean isSuccess) {this.isSuccess = isSuccess;}public String getPageContent() {return pageContent;}public void setPageContent(String pageContent) {this.pageContent = pageContent;}public int getHttpStatuCode() {return httpStatuCode;}public void setHttpStatuCode(int httpStatuCode) {this.httpStatuCode = httpStatuCode;}}RUL任务的POJO类
/*** url任务的pojo类* @author tsj-pc**/
public class UrlPojo {private Map<String, Object> parasMap;public Map<String, Object> getParasMap() {return parasMap;}public void setParasMap(Map<String, Object> parasMap) {this.parasMap = parasMap;}public UrlPojo(String url) {this.url = url;}public UrlPojo(String url, Map<String, Object> parasMap) {this.url = url;this.parasMap = parasMap;}@Overridepublic String toString() {return "UrlPojo [taskLevel=" + taskLevel + ", url=" + url + "]";}public UrlPojo(String url, TaskLevel taskLevel) {this.url = url;this.taskLevel = taskLevel;}private String url;private TaskLevel taskLevel = TaskLevel.MIDDLE;public String getUrl() {return url;}public void setUrl(String url) {this.url = url;}public TaskLevel getTaskLevel() {return taskLevel;}public void setTaskLevel(TaskLevel taskLevel) {this.taskLevel = taskLevel;}public HttpURLConnection getConnection() {try {URL url = new URL(this.url);URLConnection connection = url.openConnection();if (connection instanceof HttpURLConnection) {return (HttpURLConnection) connection;} else {throw new Exception("connection is errr!");}} catch (Exception e) {e.printStackTrace();}return null;}public String getHost() {try {URL url = new URL(this.url);return url.getHost();} catch (Exception e) {e.printStackTrace();}return null;}
}
使用HttpClient4.3.5抓取数据
public class HttpClientCrawlerImpl implements ICrawler {//当CloseableHttpClient不再需要,并且不再连接管理的范围,需要调用CloseableHttpClient.close()方法将其关闭public CloseableHttpClient httpclient = HttpClients.custom().build();@Overridepublic CrawlResultPojo crawl(UrlPojo urlPojo) {if (urlPojo == null) {return null;}CrawlResultPojo crawlResultPojo = new CrawlResultPojo();CloseableHttpResponse response1 = null;BufferedReader br = null;try {HttpGet httpget = new HttpGet(urlPojo.getUrl());response1 = httpclient.execute(httpget);HttpEntity entity = response1.getEntity();InputStreamReader isr = new InputStreamReader(entity.getContent(),"utf-8");br = new BufferedReader(isr);String line = null;StringBuilder stringBuilder = new StringBuilder();while ((line = br.readLine()) != null) {stringBuilder.append(line + "\n");}crawlResultPojo.setSuccess(true);crawlResultPojo.setPageContent(stringBuilder.toString());return crawlResultPojo;} catch (Exception e) {e.printStackTrace();crawlResultPojo.setSuccess(false);} finally {if (response1 != null) {try {response1.close();} catch (IOException e1) {e1.printStackTrace();}}if (br != null) {try {br.close();} catch (IOException e1) {e1.printStackTrace();}}}return crawlResultPojo;}/*** 传入加入参数post参数的url pojo*/public CrawlResultPojo crawl4Post(UrlPojo urlPojo) {if (urlPojo == null) {return null;}CrawlResultPojo crawlResultPojo = new CrawlResultPojo();CloseableHttpResponse response1 = null;BufferedReader br = null;try {RequestBuilder rb = RequestBuilder.post().setUri(new URI(urlPojo.getUrl()));;// .addParameter("IDToken1",// "username").addParameter("IDToken2", "password").build();Map<String, Object> parasMap = urlPojo.getParasMap();if (parasMap != null) {for (Entry<String, Object> entry : parasMap.entrySet()) {rb.addParameter(entry.getKey(), entry.getValue().toString());}}HttpUriRequest httpRequest = rb.build();response1 = httpclient.execute(httpRequest);HttpEntity entity = response1.getEntity();InputStreamReader isr = new InputStreamReader(entity.getContent(),"utf-8");br = new BufferedReader(isr);String line = null;StringBuilder stringBuilder = new StringBuilder();while ((line = br.readLine()) != null) {stringBuilder.append(line + "\n");}crawlResultPojo.setSuccess(true);crawlResultPojo.setPageContent(stringBuilder.toString());return crawlResultPojo;} catch (Exception e) {e.printStackTrace();crawlResultPojo.setSuccess(false);} finally {if (response1 != null) {try {response1.close();} catch (IOException e1) {e1.printStackTrace();}}if (br != null) {try {br.close();} catch (IOException e1) {e1.printStackTrace();}}}return crawlResultPojo;}public static void main(String[] args) throws Exception {HttpClientCrawlerImpl httpClientCrawlerImpl = new HttpClientCrawlerImpl();String url = "http://www.wangdaizhijia.com/front_select-plat";UrlPojo urlPojo = new UrlPojo(url);Map<String, Object> parasMap = new HashMap<String, Object>();int max_page_number = 1000;parasMap.put("currPage", 30);parasMap.put("params", "");parasMap.put("sort", 0);urlPojo.setParasMap(parasMap);CrawlResultPojo resultPojo = httpClientCrawlerImpl.crawl4Post(urlPojo);if (resultPojo != null) {System.out.println(resultPojo);}}
}结果:
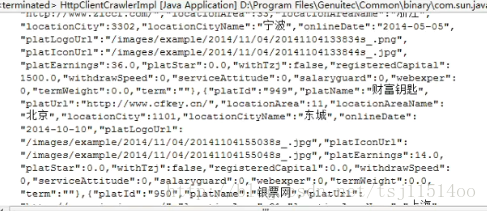
这篇关于【网络爬虫】使用HttpClient4.3.5抓取数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




