本文主要是介绍Day 31 贪心算法理论基础 455.分发饼干 376. 摆动序列 53. 最大子序和,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
贪心算法理论基础
贪心算法的本质:选择每一个阶段的局部最优,从而达到系统的整体最优;
贪心的套路就是没有套路,最好的策略就是举反例,因为大多数时候并不要求严格证明,只需要得到普遍性结论即可;
贪心算法一般分为如下四步:
- 将问题分解为若干个子问题
- 找出适合的贪心策略
- 求解每一个子问题的最优解
- 将局部最优解堆叠成全局最优解
做题的时候,只要想清楚局部最优是什么推导出全局最优就够了。
分发饼干
假设你是一位很棒的家长,想要给你的孩子们一些小饼干。但是,每个孩子最多只能给一块饼干。
对每个孩子 i,都有一个胃口值 g[i],这是能让孩子们满足胃口的饼干的最小尺寸;并且每块饼干 j,都有一个尺寸 s[j] 。如果 s[j] >= g[i],我们可以将这个饼干 j 分配给孩子 i ,这个孩子会得到满足。你的目标是尽可能满足越多数量的孩子,并输出这个最大数值。
示例 1:
- 输入: g = [1,2,3], s = [1,1]
- 输出: 1 解释:你有三个孩子和两块小饼干,3 个孩子的胃口值分别是:1,2,3。虽然你有两块小饼干,由于他们的尺寸都是 1,你只能让胃口值是 1 的孩子满足。所以你应该输出 1。
示例 2:
- 输入: g = [1,2], s = [1,2,3]
- 输出: 2
- 解释:你有两个孩子和三块小饼干,2 个孩子的胃口值分别是 1,2。你拥有的饼干数量和尺寸都足以让所有孩子满足。所以你应该输出 2.
提示:
-
1 <= g.length <= 3 * 10^4
-
0 <= s.length <= 3 * 10^4
-
1 <= g[i], s[j] <= 2^31 - 1
大尺寸的饼干既可以满足胃口大的孩子也可以满足胃口小的孩子,那么就应该优先满足胃口大的;
这种题的思路以局部最优换全局最优,思路就像田忌赛马一样;
思路:排序饼干数组和小孩数组,然后从后向前遍历小孩数组,用大饼干优先满足胃口大的,并统计满足小孩数量;
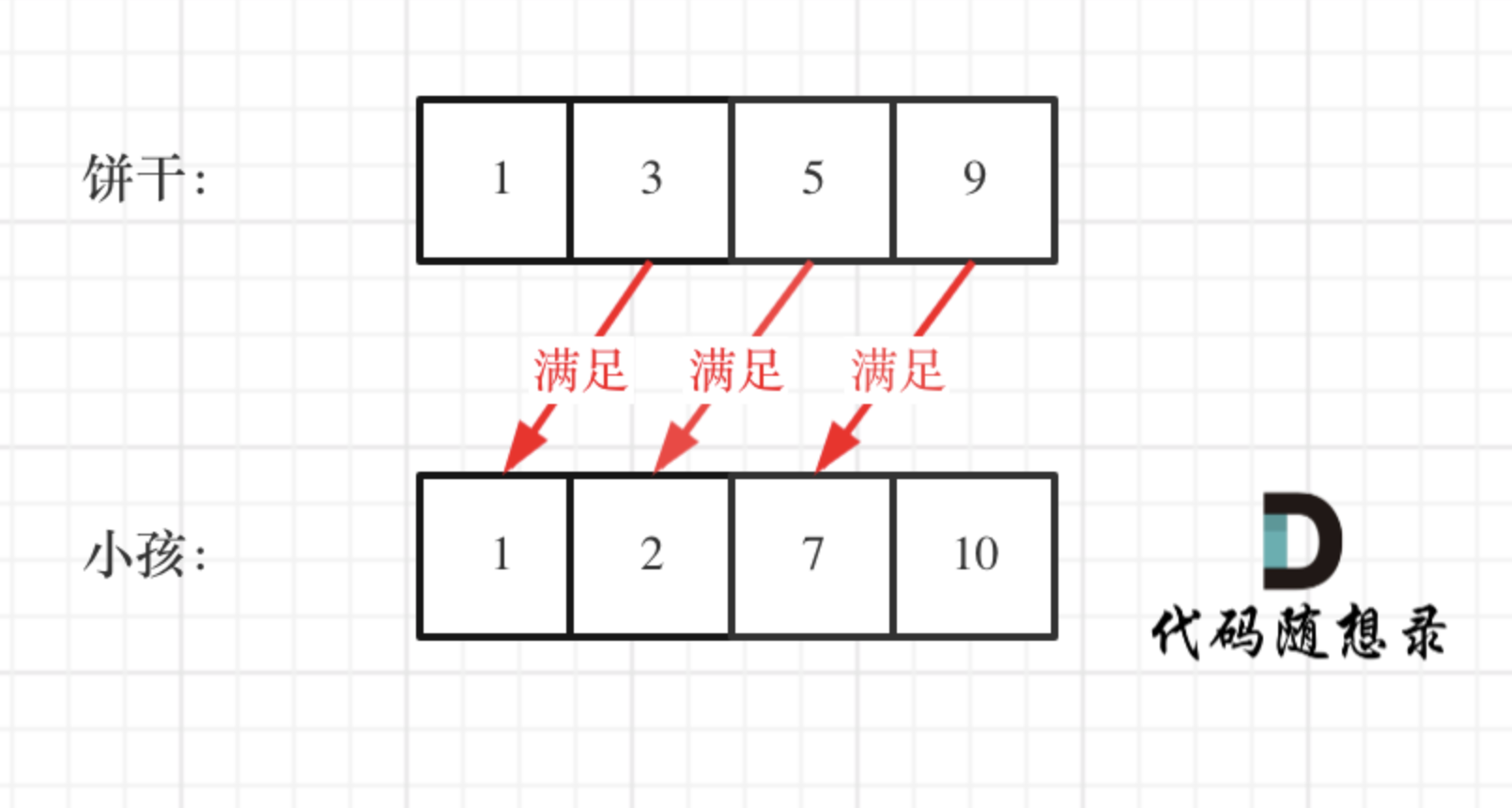
代码如下:
class Solution {
public:int findContentChildren(vector<int>& g, vector<int>& s) {sort(g.begin(), g.end());//排序胃口sort(s.begin(), s.end());//排序饼干int index = s.size() - 1; // 饼干数组的下标int result = 0;for (int i = g.size() - 1; i >= 0; i--) { // 遍历胃口if (index >= 0 && s[index] >= g[i]) { // 遍历饼干,先喂胃口大的result++;index--;}//无须两个for循环,自减操作即可完成}return result;}
};
如果把遍历胃口放在for循环里,遍历饼干放在循环体里,则需要更改遍历顺序,不然可能出现如下这种极端情况:
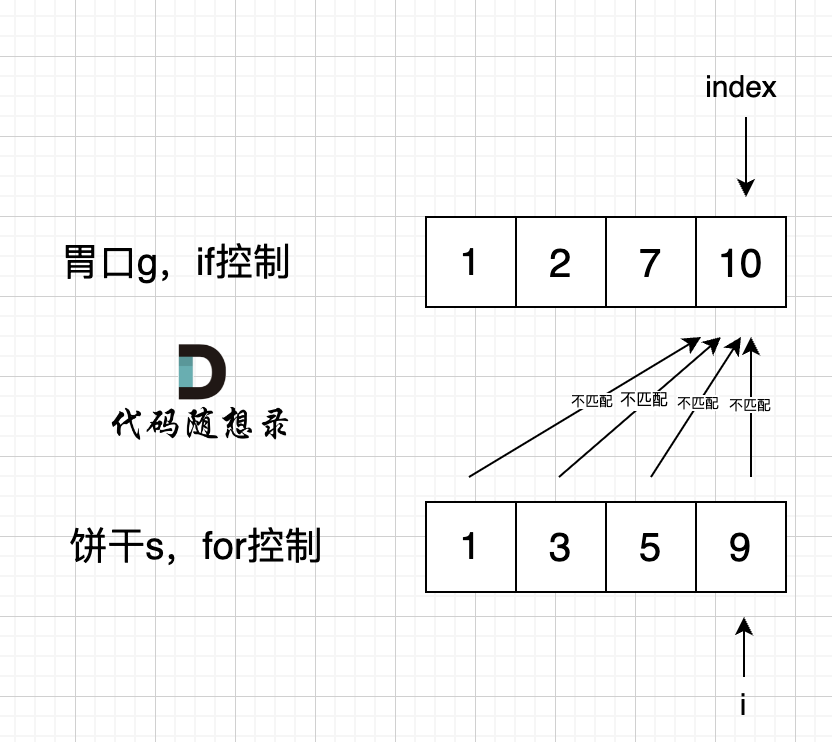
这时需要更改遍历逻辑即可:
class Solution {
public:int findContentChildren(vector<int>& g, vector<int>& s) {sort(g.begin(), g.end());sort(s.begin(), s.end());int index = 0;for(int i = 0; i < s.size(); i++){if(index < g.size() && g[index] <= s[i]){//先喂胃口小的index++;}}return index;}
};
摆动序列
如果连续数字之间的差严格地在正数和负数之间交替,则数字序列称为摆动序列。第一个差(如果存在的话)可能是正数或负数。少于两个元素的序列也是摆动序列。
例如, [1,7,4,9,2,5] 是一个摆动序列,因为差值 (6,-3,5,-7,3) 是正负交替出现的。相反, [1,4,7,2,5] 和 [1,7,4,5,5] 不是摆动序列,第一个序列是因为它的前两个差值都是正数,第二个序列是因为它的最后一个差值为零。
给定一个整数序列,返回作为摆动序列的最长子序列的长度。 通过从原始序列中删除一些(也可以不删除)元素来获得子序列,剩下的元素保持其原始顺序。
示例 1:
- 输入: [1,7,4,9,2,5]
- 输出: 6
- 解释: 整个序列均为摆动序列。
示例 2:
- 输入: [1,17,5,10,13,15,10,5,16,8]
- 输出: 7
- 解释: 这个序列包含几个长度为 7 摆动序列,其中一个可为[1,17,10,13,10,16,8]。
示例 3:
-
输入: [1,2,3,4,5,6,7,8,9]
-
输出: 2
可以看出,删除的元素来自于单调子区间内的元素,此时就达到局部最优的最短单调区间;整个序列得到最多峰值,则局部最优达到整体最优;如下所示:
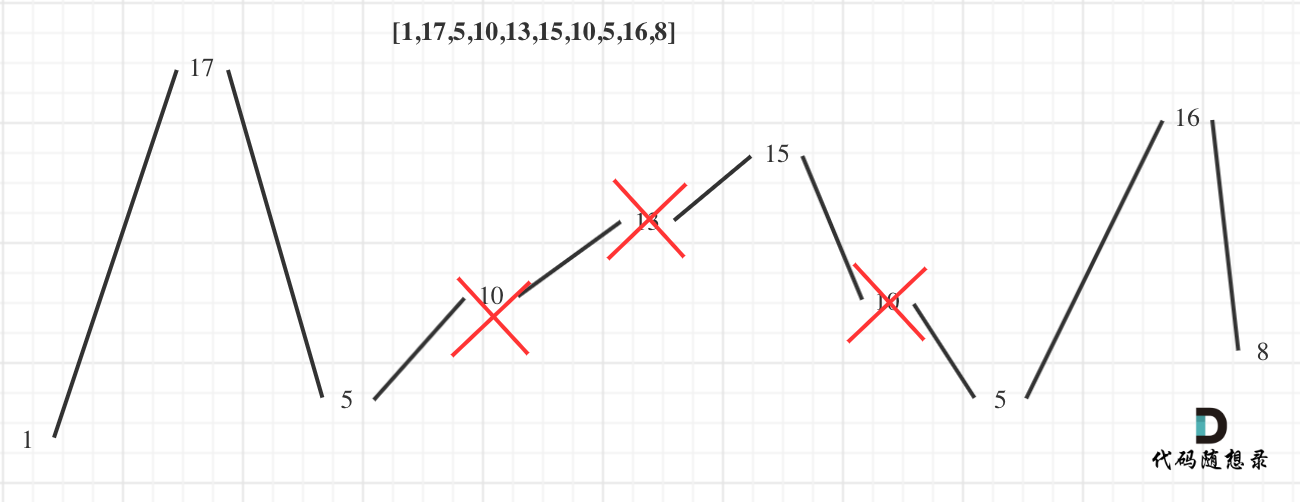
整体思路即为判断 pre = nums[i] - nums[i - 1] 与 cur = nums[i + 1] - nums[i]是否为一正一负即记录一个峰值;
考虑特殊情景:
1.存在平坡; 2.两端元素;
处理上下中间平坡:
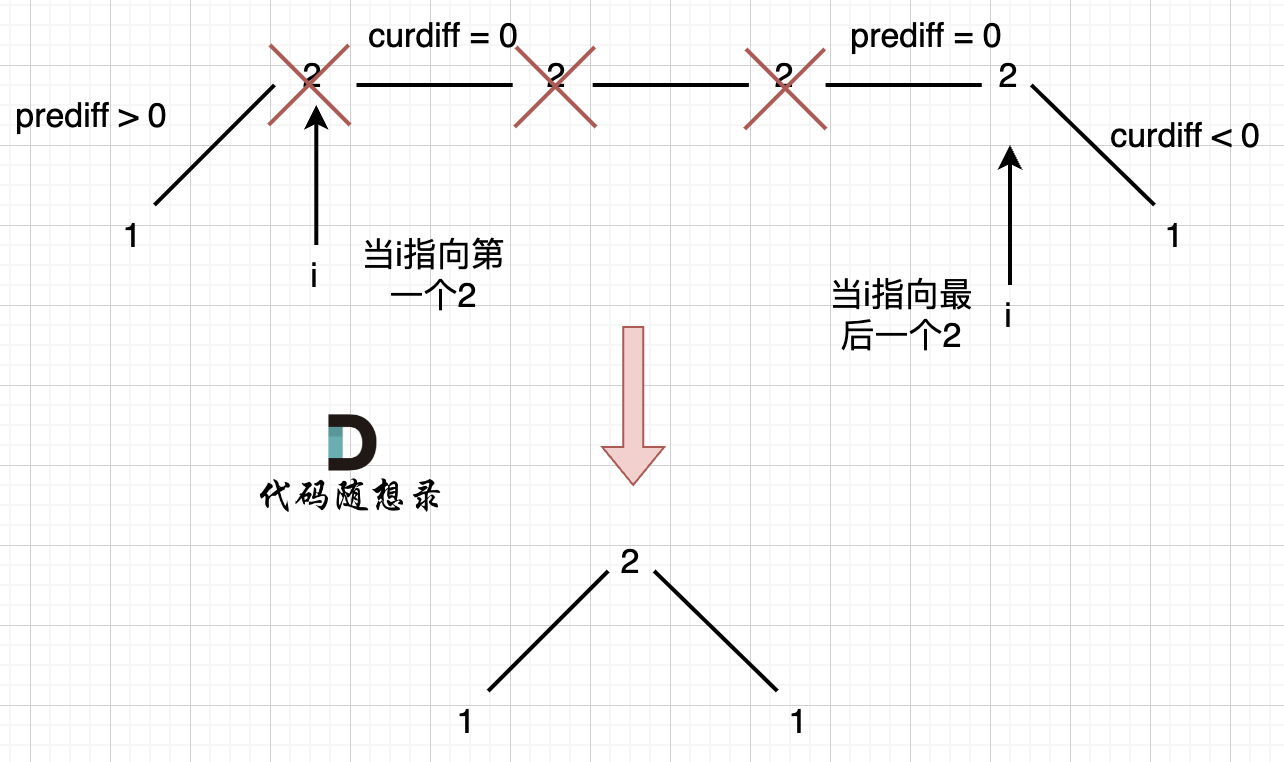
可见,此处需要考虑pre =0 && cur < 0 时,删除左边的重复元素,记录一个峰值;
然后考虑数组两端:由于判断pre和cur需要三个元素确定,所以需要延长这个数组,即默认pre = 0 ;
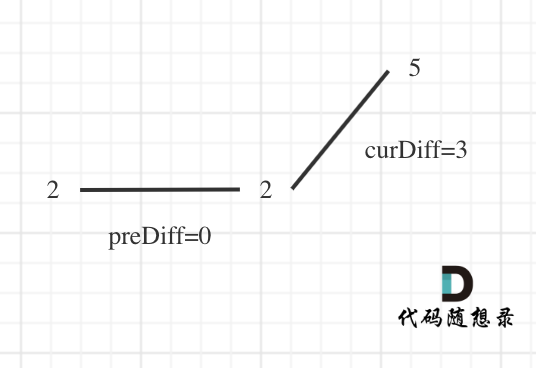
针对以上情形,result 初始为 1(默认最右面有一个峰值),此时 curDiff > 0 && preDiff <= 0,那么 result++(计算了左面的峰值),最后得到的 result 就是 2(峰值个数为 2 即摆动序列长度为 2);
核心代码实现如下:
int wiggleMaxLength(vector<int>& nums){if(nums.size() <= 1) return nums.size();int prediff = 0;//前一个差值;int curdiff = 0;//当前差值int res = 1;//默认右边有一个峰值for(int i = 0; i < nums.size() - 1; i++){//不处理最后一个元素curdiff = nums[i + 1] - nums[i];if((prediff <= 0 && curdiff > 0) || (prediff >= 0 && curdiff < 0)){res++;}prediff = curdiff;//实时更新}return res;}
这段代码提交是有误的,因为没有考虑另一种情况;
即单调增的平坡状态:
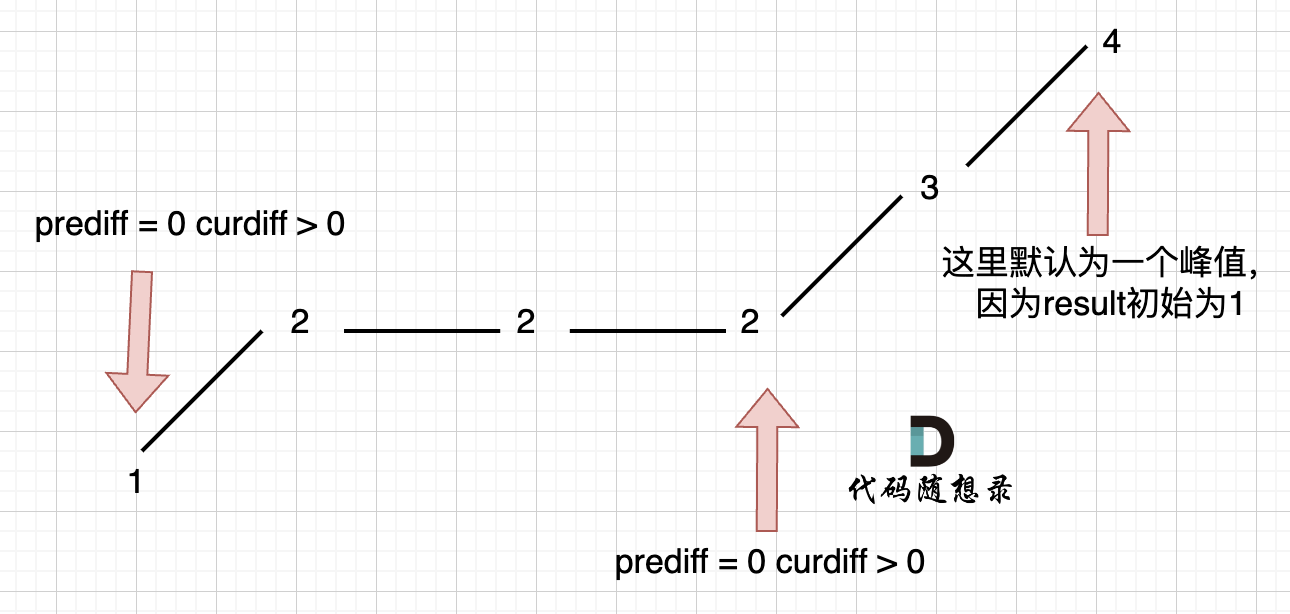
可以看出,上面的代码在三个地方都记录峰值,但其实结果应为2,因为单调中的平坡不能算峰值(即摆动);
出问题是因为实时更新了 prediff;
只需要在这坡度摆动变化的时候,更新prediff即可,这样 prediff在单调区间有平坡的时候就不会发生变化,造成误判;
即:
int wiggleMaxLength(vector<int>& nums){if(nums.size() <= 1) return nums.size();int prediff = 0;//前一个差值;int curdiff = 0;//当前差值int res = 1;//默认右边有一个峰值for(int i = 0; i < nums.size() - 1; i++){//不处理最后一个元素curdiff = nums[i + 1] - nums[i];if((prediff <= 0 && curdiff > 0) || (prediff >= 0 && curdiff < 0)){res++;prediff = curdiff;}//prediff = curdiff;//实时更新}return res;}
最大子序和
给定一个整数数组 nums ,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
示例:
- 输入: [-2,1,-3,4,-1,2,1,-5,4]
- 输出: 6
- 解释: 连续子数组 [4,-1,2,1] 的和最大,为 6。
很简单的想法是暴力法,两个for循环搞事情,肯定不这么整;
思考局部最优思路:当**连续和为负数**时,舍弃这个连续和,然后从下一个元素重新开始寻找子序列;

[注]:
1.并非见到负数就舍弃,使用res记录count的值即可,这样能保证res一直是最大值,同时res也保证了终止条件,因为本题只要求返回最大和;
2.负数只会让下一次相加后的结果变得更小,所以舍弃所有连续和为负的结果;
代码如下:
class Solution {
public:int maxSubArray(vector<int>& nums) {int res = INT32_MIN;//记录最大值int count = 0;for(int i = 0; i < nums.size(); i++){count += nums[i];if(count > res) res = count;if(count <= 0) count = 0;}return res;}
};
这篇关于Day 31 贪心算法理论基础 455.分发饼干 376. 摆动序列 53. 最大子序和的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




