本文主要是介绍【算法刷题】手撕LRU算法(原理、图解、核心思想),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

文章目录
- 1.LRU算法
- 1.1相关概念
- 1.2图解举例
- 1.3基于HashMap和双向链表实现
- 1.3.1核心思想
- 1.3.2代码解读
- 1.3.3全部代码
1.LRU算法
1.1相关概念
- LRU(Least Recently Used,最近最久未使用算法):
- 定义:根据页面调入内存后的使用情况来做决策。LRU页面置换算法选择最近最久未使用的页面予以淘汰;
- 支持:该算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问内以来锁经历的时间t;当淘汰一个页面时,选择现有页面中 t值最大的(即最近最久未使用的)页面进行淘汰
- 两种硬件支持(选择其中一种即可):
- 寄存器:
- 作用:其中包含了标记位和时间戳,标记位可以快速判断缓存块(页面)是否有效,而无需遍历整个栈来查找。时间戳可以快速记录和更新缓存块(页面)的访问时间,而不必每次访问都遍历栈来更新。
- 栈:
- 作用:用于记录缓存块(页面)的访问顺序(当前使用中的各个页面的页面号)。
- 新增页面步骤:
- 每当进程访问某页面时,判断该页面在栈中是否存在
- 若存在,则将该页面的页面号从栈中取出,并将该原页面号压入栈顶;
- 若不存在,则将栈底元素移除,并将新页面号压入栈顶;
- 因此,栈顶始终是最新被访问页面的页面号 , 栈底则是最近最久未使用页面的页面号!
- 每当进程访问某页面时,判断该页面在栈中是否存在
- 寄存器:
1.2图解举例
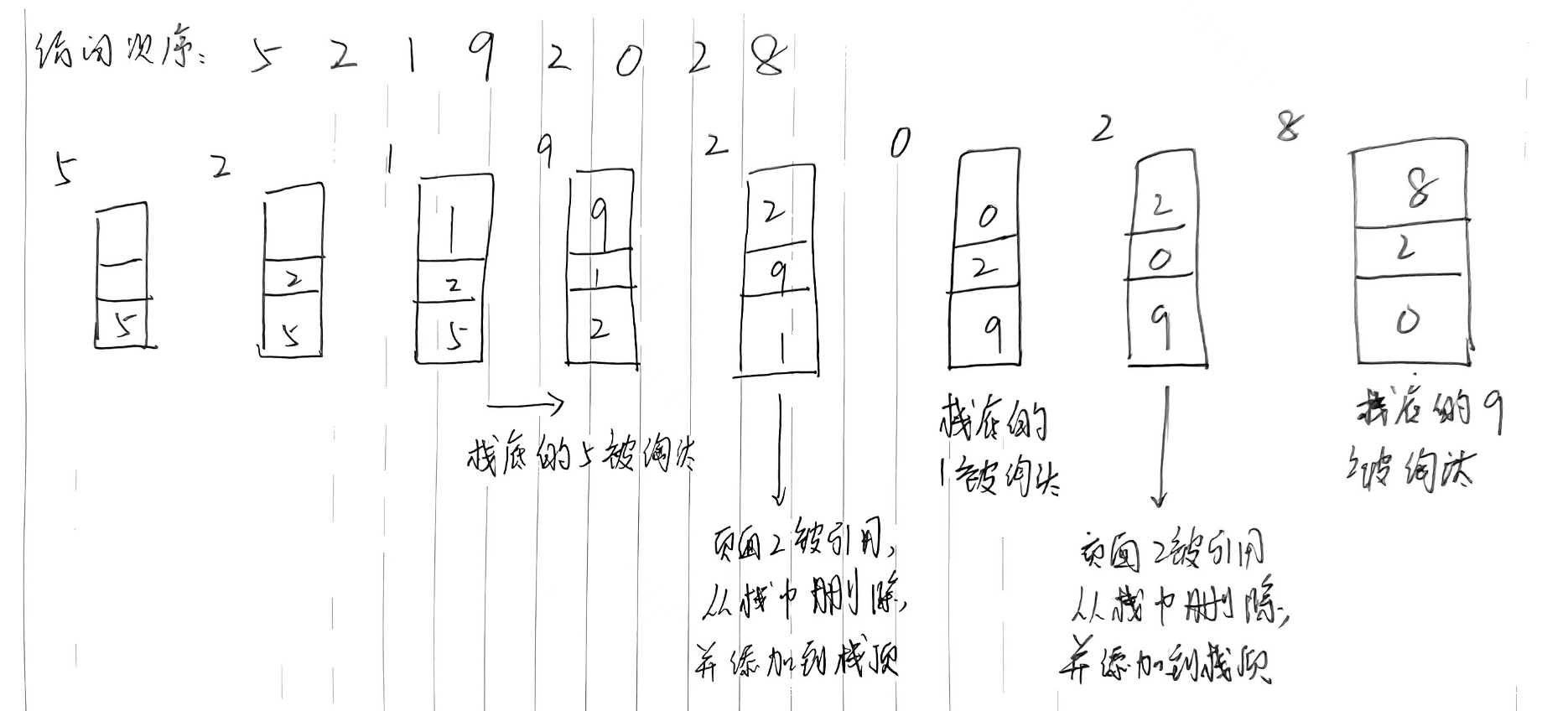
- 举例前提:假设内存只能容纳3个页大小,进程按照 5 2 1 9 2 0 2 8的次序访问页
- 假设内存按照栈的方式来描述访问时间,并保证 栈顶始终是最新被访问页面的页面号 , 栈底则是最近最久未使用页面的页面号
1.3基于HashMap和双向链表实现
1.3.1核心思想
-
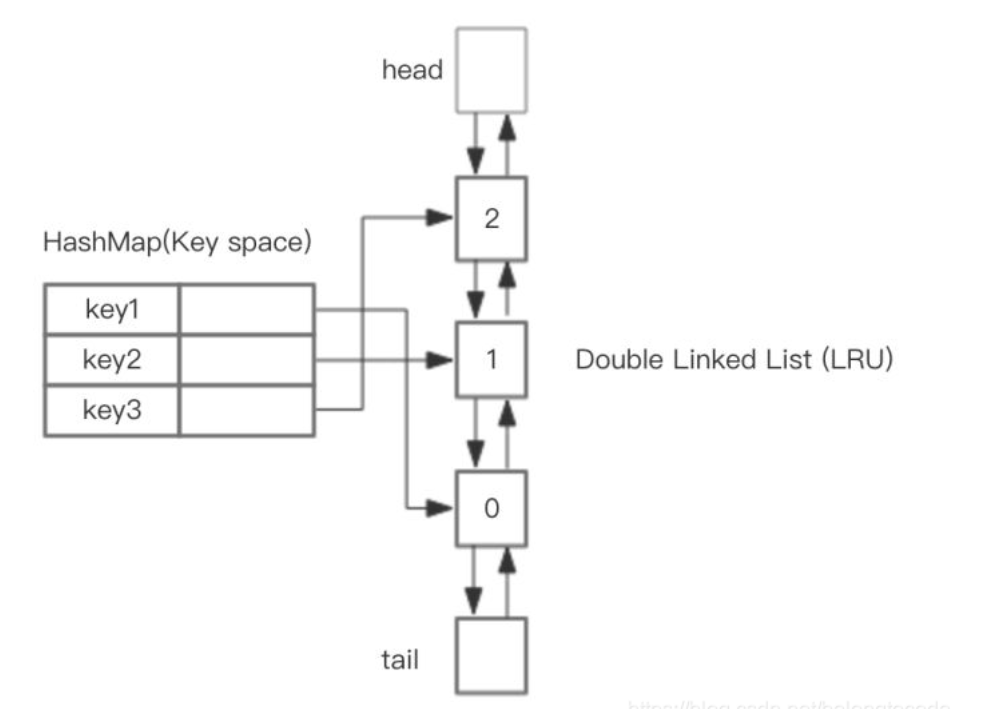
核心思想:使用自定义节点DLinkedNode模拟双向链表,并通过双向链表实现栈功能;
-
使用HashMap存储以页面号为key,value存储指向双向链表节点的指针
-
双向链表维护了页面的访问顺序,链表的头部(即栈顶)为最新访问的页面,底部为最久未使用的页面
-
put(key,value):首先在 HashMap 找到 Key 对应的节点,
- 如果节点存在,更新节点的值,并把这个节点移动栈顶。
- 如果不存在,需要构造新的节点,并且尝试把节点塞到栈顶 ,如果LRU空间不足,则通过 tail 淘汰掉栈底的节点,同时在 HashMap 中移除 Key。
1.3.2代码解读
- DLinkedNode
class DLinkedNode {String key;int value;DLinkedNode pre;DLinkedNode next;
}
- cache:使用HashTable代替HashMap,线程安全
private Hashtable<String, DLinkedNode> cache = new Hashtable<>();
- put流程:
public void put(String key, int value) {DLinkedNode node = cache.get(key);if(node == null){DLinkedNode newNode = new DLinkedNode();newNode.key = key;newNode.value = value;this.cache.put(key, newNode);this.addNode(newNode);++count;if(count > capacity){// 淘汰栈底元素DLinkedNode tail = this.popTail();this.cache.remove(tail.key);--count;}}else{//该元素已经存在//将该元素移动到栈顶node.value = value;this.moveToHead(node);}
}
- 移动栈中的元素到栈顶:
- 首先先删除该节点 (解除引用)
- 再添加该节点到栈顶
//将该节点移动到头节点
private void moveToHead(DLinkedNode node){this.removeNode(node);this.addNode(node);
}
//删除该节点(跳过该节点)
private void removeNode(DLinkedNode node){DLinkedNode pre = node.pre;DLinkedNode next = node.next;pre.next = next;next.pre = pre;
}
//添加节点到栈顶
private void addNode(DLinkedNode node){node.pre = head;node.next = head.next;head.next.pre = node; //头部节点的上一个节点为新节点head.next = node;
}
1.3.3全部代码
class DLinkedNode {String key;int value;DLinkedNode pre;DLinkedNode next;
}public class LRUCache {private Hashtable<String, DLinkedNode> cache = new Hashtable<>();private int count;private int capacity;private DLinkedNode head, tail;public LRUCache(int capacity) {this.count = 0;this.capacity = capacity;head = new DLinkedNode();head.pre = null;tail = new DLinkedNode();tail.next = null;head.next = tail;tail.pre = head;}public void put(String key, int value) {DLinkedNode node = cache.get(key);if(node == null){DLinkedNode newNode = new DLinkedNode();newNode.key = key;newNode.value = value;this.cache.put(key, newNode);this.addNode(newNode);++count;if(count > capacity){// 淘汰栈底元素DLinkedNode tail = this.popTail();this.cache.remove(tail.key);--count;}}else{//该元素已经存在//将该元素移动到栈顶node.value = value;this.moveToHead(node);}}//添加节点private void addNode(DLinkedNode node){node.pre = head;node.next = head.next;head.next.pre = node;head.next = node;}//删除该节点(跳过该节点)private void removeNode(DLinkedNode node){DLinkedNode pre = node.pre;DLinkedNode next = node.next;pre.next = next;next.pre = pre;}//将该节点移动到头节点private void moveToHead(DLinkedNode node){this.removeNode(node);this.addNode(node);}//淘汰栈底元素private DLinkedNode popTail(){DLinkedNode res = tail.pre;this.removeNode(res);return res;}@Overridepublic String toString() {StringBuilder sbu = new StringBuilder();DLinkedNode cur = head.next;sbu.append("{");while (cur != tail) {if (cur.next != tail) {sbu.append(cur.key).append("=").append(cur.value).append(", ");} else {sbu.append(cur.key).append("=").append(cur.value);}cur = cur.next;}sbu.append("}");return sbu.toString();}public static void main(String[] args) {LRUCache lruCache = new LRUCache(3);lruCache.put("1", 5);lruCache.put("2", 2);lruCache.put("3", 1);System.out.println(lruCache);System.out.println("使用后:");lruCache.put("2",2);System.out.println(lruCache);lruCache.put("2",2);System.out.println(lruCache);lruCache.put("4", 13);System.out.println("最不常用的被删除,新元素插到头部:");System.out.println(lruCache);}}
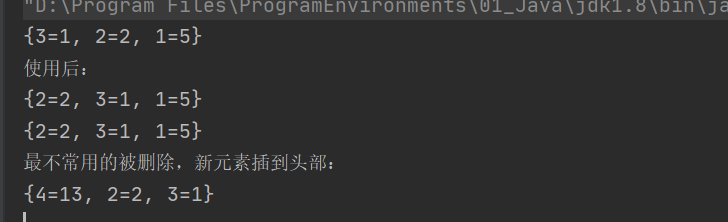
- 测试结果:

这篇关于【算法刷题】手撕LRU算法(原理、图解、核心思想)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







