本文主要是介绍【极速前进】20240422:预训练RHO-1、合成数据CodecLM、网页到HTML数据集、MLLM消融实验MM1、Branch-Train-Mix,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、RHO-1:不是所有的token都是必须的
论文地址:https://arxiv.org/pdf/2404.07965.pdf

1. 不是所有token均相等:token损失值的训练动态。
使用来自OpenWebMath的15B token来持续预训练Tinyllama-1B,每1B token保存一个checkpoint。对于每个checkpoint都评估token级别的loss。通过分析token级别loss,发现token的损失值有4种模式:持续高损失值(H->H)、损失值增加(L->H)、损失值下降(H->L)、持续低损失值(L->L)。其中,H->L的token占26%;L->L的token占51%;H->H的token占11%;L->H的token占12%。L->L和H->H的token损失值在训练中方差高,可视化后发现其中包含很多噪音。
综上,训练过程中token的损失值并不像总体损失值那边平滑减少,token损失值之间存在复杂动态。因此,训练过程中选择合适的token,可以稳定训练并提高训练效率。
2. 选择性语言建模
整体思路:a. 在高质量数据上训练reference模型;b. 使用该模型对预训练的token评估损失值;c. 选择性训练语言模型,专注在训练模型和reference模型之间高损失值的token。
reference建模。使用高质量数据训练reference模型(RM),训练方式采用标准的交叉熵。token x i x_i xi的损失值计算为:
L ref ( x i ) = − log P ( x i ∣ x < i ) \mathcal{L}_{\text{ref}}(x_i)=-\log P(x_i|x_{<i}) \\ Lref(xi)=−logP(xi∣x<i)
通过损失值可以使语言模型专注在更具影响力的token上。
选择性预训练。自回归语言模型训练的损失函数为:
L CLM ( θ ) = − 1 N ∑ i = 1 N log P ( x i ∣ x < i ; θ ) \mathcal{L}_{\text{CLM}}(\theta)=-\frac{1}{N}\sum_{i=1}^N\log P(x_i|x_{<i};\theta) \\ LCLM(θ)=−N1i=1∑NlogP(xi∣x<i;θ)
其中 θ \theta θ是模型参数, N N N是序列长度, x i x_i xi是序列中第i个token, x < i x_{<i} x<i表示第i个token前的所有token。选择性语言建模重点关注那些与reference模型相比具有高损失值的token。超额损失值 L Δ \mathcal{L}_{\Delta} LΔ的定义为:
L Δ ( x i ) = L θ ( x i ) − L ref ( x i ) \mathcal{L}_{\Delta}(x_i)=\mathcal{L}_{\theta}(x_i)-\mathcal{L}_{\text{ref}}(x_i) \\ LΔ(xi)=Lθ(xi)−Lref(xi)
这里引入一个选择比例k%,用于根据超额损失值来确定包含token的比例。选择性token的交叉熵损失值为:
L SLM ( θ ) = − 1 N × k % ∑ i = 1 N I k % ( x i ) ⋅ log P ( x i ∣ x < i ; θ ) \mathcal{L}_{\text{SLM}}(\theta)=-\frac{1}{N\times k\%}\sum_{i=1}^N I_{k\%}(x_i)\cdot\log P(x_i|x_{<i};\theta) \\ LSLM(θ)=−N×k%1i=1∑NIk%(xi)⋅logP(xi∣x<i;θ)
其中 N × k % N\times k\% N×k%表示超额损失值落在前k%的token数量。指示函数 I k % ( x i ) I_{k\%}(x_i) Ik%(xi)定义为
I k % ( x i ) = { 1 若 x i 的 L Δ 位于前 k % 0 否则 I_{k\%}(x_i)=\begin{cases} 1&若x_i的\mathcal{L}_{\Delta}位于前k\% \\ 0&否则\\ \end{cases} \\ Ik%(xi)={10若xi的LΔ位于前k%否则
这可以确定语言建模更多关注最有用的token。
3. 实验结果
Few-shot CoT推理结果。相比直接继续预训练,RHO-1-Math在1B和7B模型上实现16.5%和10.4%的平均few-shot准确率改善。多训练几个epoch能够持续增加few-shot准确率。DeepSeekMath-7B在500Btoken上预训练和RHO-1-7B在15Btoken上的效果相当。
工具集成推理结果。RHO-1-1B和RHO-1-7B在MATH数据集实现了SOTA。
通用预训练结果。相比于直接继续预训练,选择性语言建模(SLM)在15个基准上平均改善幅度为6.8%,这种改善在代码和数学中尤其明显。
二、CodecLM:使用定制合成数据对齐LM
论文地址:https://arxiv.org/pdf/2404.05875.pdf
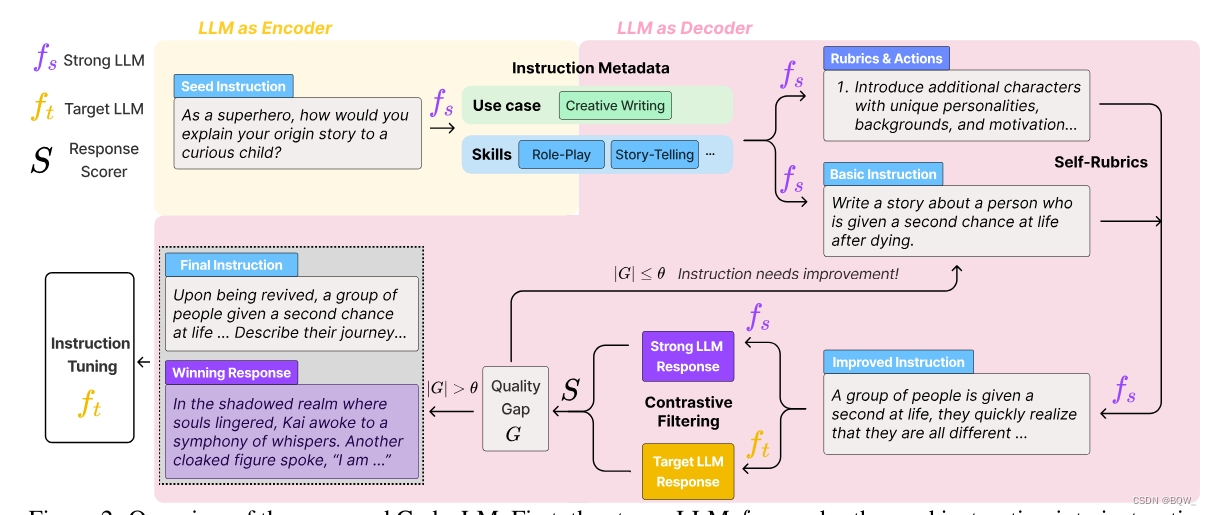
1. LLM用作指令编解码器
LLM作为指令元数据编码器。这里编码器的作用是将种子指令 D s = { I i } i = 1 n \mathcal{D}_s=\{I_i\}_{i=1}^n Ds={Ii}i=1n编码为指令元数据。具体来说,元数据包含两个关键因素:用例(use case)和技能(skills)。用例描述了预期的任务(例如:问答或者创意写作),技能则是LLM成功回答指令所需要的知识。通常,每个指令包含单个用例和多个技能。对于每个指令 I i I_i Ii,使用LLM编码器 f s f_s fs抽取对应的用例 u i u_i ui和一组技能 s i s_i si,这样就能拥有一组元数据 M = { ( u i , s i ) } i = 1 n \mathcal{M}=\{(u_i,\textbf{s}_i)\}_{i=1}^n M={(ui,si)}i=1n。
LLM作为指令生成解码器。给定元数据 M \mathcal{M} M,通过一种生成和合成范式将其解码为合成指令。
2. 通过Self-Rubrics进行指令合成
研究表明更复杂的指令能够改善对齐效果。常用的方法是人类专家来撰写复杂指令的指导信息,例如添加推理步骤或约束。但是,这种方式无法满足多样化指令的要求,需要为不同的任务量身定制指导信息。
Self-Rubrics指导LLM生成用于评估指令复杂度的元评价准则,然后基于这些准则生成一组增强复杂度的动作。对于元数据 ( u i , s i ) (u_i,\textbf{s}_i) (ui,si),对应的生成动作集合为 a i \textbf{a}_i ai。例如,当用例是"商业计划制定"且技能是"市场研究和规划",通用准则"添加推理步骤"就有些不合适。Self-Rubrics则会生成类似于"添加SWOT分析"和"包含市场竞争对手的比较"这样的动作。
在获得动作 { a i } i = 1 n \{\textbf{a}_i\}_{i=1}^n {ai}i=1n后,就可以利用 f s f_s fs将指令复杂化。
3. 通过对比过滤进行指令选择
对比过滤的目标是为LLM f t f_t ft选择更有效的指令。设 N \mathcal{N} N是所有自然语言序列的空间,强LLM为 f s : N → N f_s:\mathcal{N}\rightarrow\mathcal{N} fs:N→N,目标LLM为 f t : N → N f_t:\mathcal{N}\rightarrow\mathcal{N} ft:N→N,评估函数为 S : N → R S:\mathcal{N}\rightarrow\mathbb{R} S:N→R。评估函数使用 f s f_s fs来实现。
给定一个指令 I ∈ N I\in\mathcal{N} I∈N,获得两个LLM的响应 f s ( I ) f_s(I) fs(I)和 f t ( I ) f_t(I) ft(I),定义质量差距为 G ( I ) = S ( f s ( I ) ) − S ( f t ( I ) ) G(I)=S(f_s(I))-S(f_t(I)) G(I)=S(fs(I))−S(ft(I))。当 ∣ G ( I ) ∣ > θ |G(I)|>\theta ∣G(I)∣>θ时,要么 f s f_s fs生成的质量高,则将 ( I , f s ( I ) ) (I,f_s(I)) (I,fs(I))添加至最终数据集 D g \mathcal{D}_g Dg;要么 f t f_t ft生成的质量高,则将 ( I , f t ( I ) ) (I,f_t(I)) (I,ft(I))添加至 D g \mathcal{D}_g Dg。若 ∣ G ( I ) ∣ < θ |G(I)|<\theta ∣G(I)∣<θ,则不使用该数据。
4.实验结果

三、WebSight数据集:网页截图到HTML转换
论文地址:https://arxiv.org/pdf/2403.09029.pdf
1. 目标
构建一个网页截图到HTML代码的数据集,从而提高VLM将图片转换为网页源代码的能力。
2. 构造过程
(1) 生成多样化的网站概念:利用Mistral-7B-Instruct生成数百万个唯一的网站概念和设计。
(2) 使用Tailwind CSS而不是传统CSS。
(3) 使用代码LLM生成HTML代码:利用Deepseek-Coder-33b-instruct来生成HTML代码。此外,为了解决HTML代码中没有图片的问题,使用了一种基于关键词生成图片的api。经过过滤后,大约留下2百万网页。
(4) 截图捕获:使用Playwright来可视化和捕获生成的HTML网页。
3. 使用WebSight微调基础VLM
将网页截图转换为HTML代码的模型需要的能力包括:(1) 描述图像中文本的OCR能力;(2) 对网页中元素排列的空间理解能力;(3) 目标检测能。
模型使用基于Mistral-7B和SigLIP-SO400M构造的基础模型。
4.结果
对于简单的网页转换来说效果还可以并且有一定的泛化能力。
但是,在处理复杂网页布局、过多文本内容或者设计与训练数据有很大不同时,效果会比较差。这也表明该模型并没有完全掌握HTML+Tailwind CSS语法。
四、MM1:来自多模态LLM预训练的方法、分析和洞见
论文地址:https://arxiv.org/pdf/2403.09611.pdf
本文的目标是探索模型架构、数据和训练过程对于多模态LLM(MLLM)的影响。通过对不同组件的消融来验证效果,包括:图像编码器、视觉-语言连接器、预训练数据和语言模型。使用zero-shot和few-shot在各种captioning和VQA任务上进行测试。
1. 模型架构消融
图像编码器消融。
大多数MLLM使用CLIP的图像编码器,也有一些工作使用纯视觉自监督模型,例如DINOv2。总的来说,视觉编码器的选择对下游的结果有显著的影响。这里主要是对图像分辨率和图像编码器目标函数进行消融。
视觉编码器的消融结果:图像分辨率影响最大,其次才是模型尺寸和训练数据。此外,对比损失函数的效果往往高于重构的损失函数。
视觉-语言连接器。该组件的目标是将视觉表示转换至LLM空间,消融的组件包括:Average Pooling、Attention Pooling和Convolutional Mapping。
视觉-语言连接器的消融结果:视觉token的数量和图像分辨率最重要,VL连接器类型几乎没有影响。
2. 预训练数据消融
有两种类型的数据常用于训练MLLM:一种是成对文本和图像的captioning数据,另一种是来自于网络的交错图像文本数据。captioning数据中的文本往往与图像高度相关,而交错数据更长但相关度低。
消融结果1:交错数据能改善few-shot和纯文本的能力,captioning数据有益于zero-shot的能力。
消融结果2:纯文本数据有助于few-shot和纯文本的效果。
消融结果3:仔细混合图像和文本数据能够产生最佳的多模态效果且保持文本的性能。
消融结果4:合成数据有助于few-shot的学习。
3. 最终模型
图像编码器:由于分辨率的重要性,使用分辨率为378*378的ViT-H。
视觉-语言连接器:使用144个token的连接器,实际架构选择了C-Abstractor。
数据:45%的交叉图文数据、45%的成对图文数据、10%的纯文本数据。
4. 监督微调
SFT数据遵循LLaVA-1.5和LLaVA-NeXT,并从各个数据集收集了1.45M的SFT样本。
为了支持更高的分辨率,使用了两种方法:(1) 位置插值;(2) 子图分解。
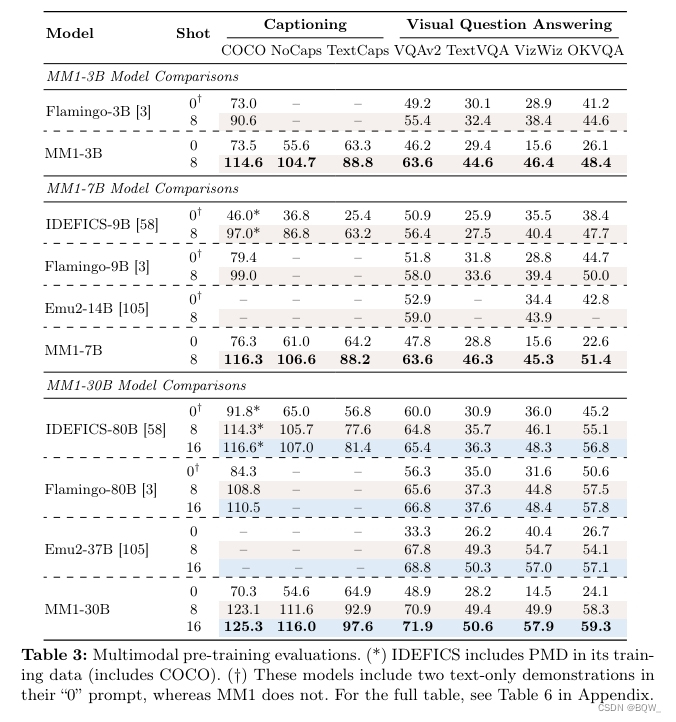
与SOTA相比。MM1-3B-Chat和MM1-7B-Chat超越了所有同尺寸模型。MoE模型都比稠密模型效果好。MM1-30B-Chat在一些任务上优于Emu2-Chat-37B和CogVLM-30B。全面优于LLaVA-NeXT。
分辨率的影响。提升分辨率能够提高效果。
预训练的影响。预训练可以显著改善效果。
SFT后few-shot CoT推理。归功于交错数据,MM1具有few-shot的能力。
五、Branch-Train-MiX
论文地址:https://arxiv.org/pdf/2403.07816.pdf
给定现有的LLM M \mathcal{M} M,目标是提高其在 N N N个专业领域的表现。具体的方式是通过在N个不同的数据集上进行继续预训练 D : = { D 1 , … , D N } \mathcal{D}:=\{D_1,\dots,D_N\} D:={D1,…,DN}。
1. Branch&Train:并行专家训练
使用种子模型 M \mathcal{M} M进行训练,得到N个专家LLM { M 1 , … , M N } \{\mathcal{M}_1,\dots,\mathcal{M}_N\} {M1,…,MN},每个模型 M i \mathcal{M}_i Mi都在对应数据集 D i D_i Di上用相同方法进行预训练。因此,每个专家都是独立于其他专家进行训练的,所以可以进行N路并行训练。
早期的Branch-Train-Merge方法在推理时通过确定领域来选择专家,通常多个专家被选择且最终的输出分布是next token的简单平均。本文的BTX方法会将领域专家合并为单个LLM,然后进一步微调。
2. Mix:将独立专家合并为MoE
这里利用MoE的方法合并领域专家模型 M i \mathcal{M}_i Mi。然而,相比于经典方法来混合 M i \mathcal{M}_i Mi的最终输出,这里对Transformer每层都进行一个细粒度的混合。令 FF i l ( x ) \text{FF}_i^l(x) FFil(x)表示第i个专家 M i \mathcal{M}_i Mi的第l层的前馈子层,那么合并后MoE层的计算为:
FF MoE l ( x ) = ∑ i = 1 N g i ( W l x ) FF i l ( x ) \text{FF}_{\text{MoE}}^l(x)=\sum_{i=1}^Ng_i(W_lx)\text{FF}_i^l(x) \\ FFMoEl(x)=i=1∑Ngi(Wlx)FFil(x)
W l W_l Wl是线性变换层, g g g是路由函数,其通常是稀疏输出并仅连通部分专家。若对应的路由输出为0,可以跳过 FF i l ( x ) \text{FF}_i^l(x) FFil(x)的计算,因此 FF MoE l ( x ) \text{FF}_{\text{MoE}}^l(x) FFMoEl(x)计算要比计算所有领域专家效率高。在本文中,使用Top-K路由,即 g ( W l x ) = SoftMax ( TopK ( W l x ) ) g(W_lx)=\text{SoftMax}(\text{TopK}(W_lx)) g(Wlx)=SoftMax(TopK(Wlx))。
对于自注意力子层,通过简单平均权重来合并不同的专业。这种做的原因是自注意力层相比FFN层更不专业化。对于embedding层等也使用权重平均的方式。
这里引入的新参数仅包括路由变换参数 W l W_l Wl,其在整个网络中可以忽略不计。但是,这些参数需要微调。
3. 变体
负载均衡。MoE模型常见的问题是dead experts,即路由永远不激活该专家。这里通过一个额外的损失项来鼓励平等利用。具体来说,
L LB = α N ∑ i = 1 N u i p i 其中 u i = 1 ∣ β ∣ ∑ x ∈ β g i ( W l x ) 且 p i = 1 ∣ β ∣ ∑ x ∈ β Softmax i ( W l x ) \mathcal{L}_{\text{LB}}=\alpha N\sum_{i=1}^N u_i p_i\quad其中u_i=\frac{1}{|\beta|}\sum_{x\in\beta}g_i(W_lx)且p_i=\frac{1}{|\beta|}\sum_{x\in\beta}\text{Softmax}_i(W_lx) \\ LLB=αNi=1∑Nuipi其中ui=∣β∣1x∈β∑gi(Wlx)且pi=∣β∣1x∈β∑Softmaxi(Wlx)
其中 β \beta β是当前数据的batch, α \alpha α是超参数。
路由方法。Switch、Soft routing、Sample Top-1。
拆分专家。MoE层的模块数量与训练的领域数量相当,每个模块对于一个领域。通过简单的将每个领域的FF子层划分为更多的块就能增加专家的数量。给定 N N N个领域,FF的激活尺寸为 d FF d_{\text{FF}} dFF,将FF层划分为 C C C块,每块的维度 d FF / C d_{\text{FF}}/C dFF/C。这样,最终MoE层将有MC个模块。
4. 实验结果
领域专家在特定任务上表现卓越。在代码和数学领域表现明显,其数学专家也能够帮助提升代码能力。但在其他任务上效果下降。
BTX改进了专家擅长的所有任务。BTX训练的模型在所有专家领域都有所改进,且对其他领域效果没有影响。
划分为 C C C块,每块的维度 d FF / C d_{\text{FF}}/C dFF/C。这样,最终MoE层将有MC个模块。
4. 实验结果
领域专家在特定任务上表现卓越。在代码和数学领域表现明显,其数学专家也能够帮助提升代码能力。但在其他任务上效果下降。
BTX改进了专家擅长的所有任务。BTX训练的模型在所有专家领域都有所改进,且对其他领域效果没有影响。
这篇关于【极速前进】20240422:预训练RHO-1、合成数据CodecLM、网页到HTML数据集、MLLM消融实验MM1、Branch-Train-Mix的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




