本文主要是介绍学习笔记Day21:转录组差异分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
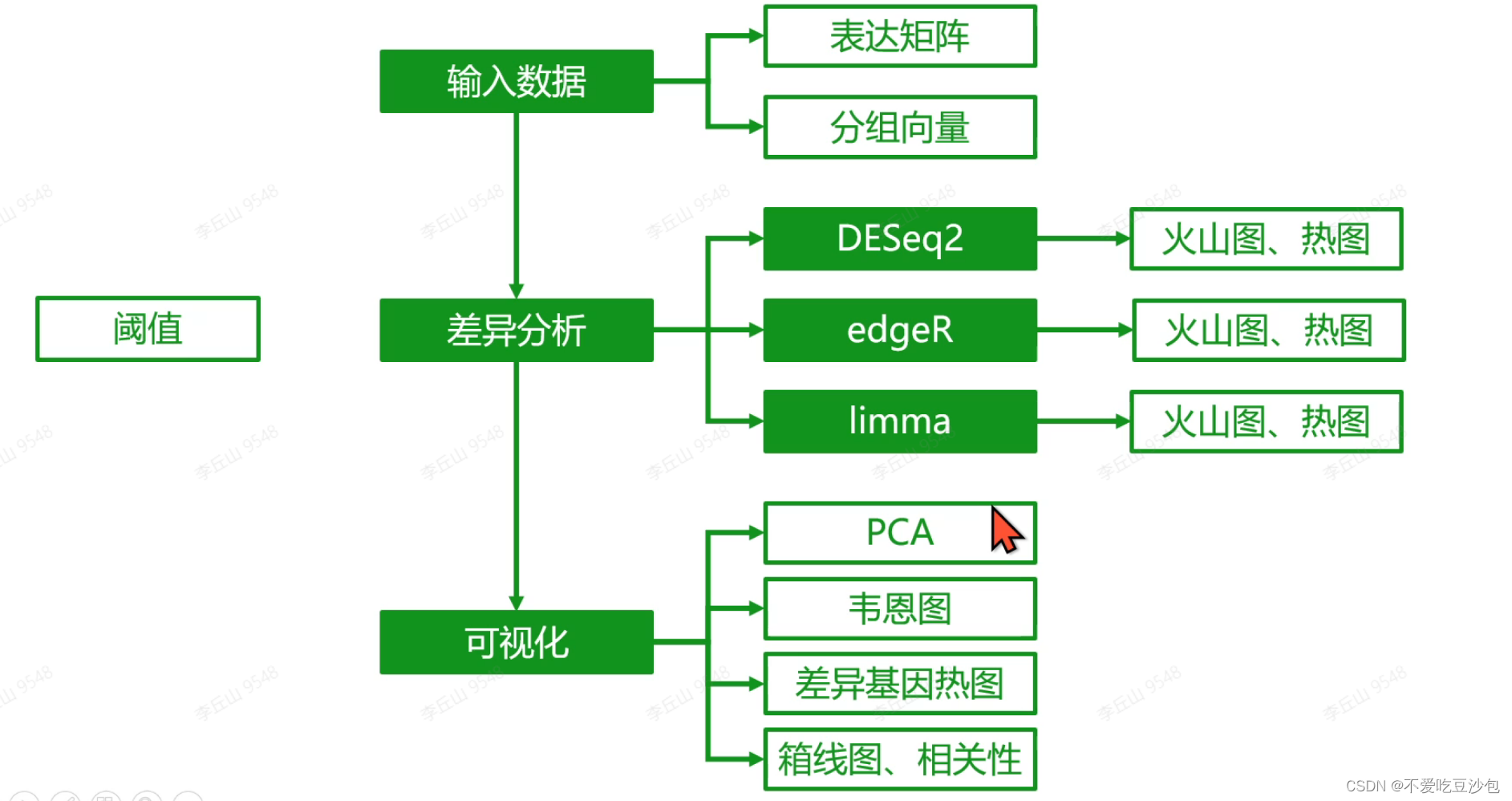
转录组差异分析
差异分析难点在于将数据处理成需要的格式
表达矩阵
数值型矩阵-count
行名是symbol
低表达量的基因需要过滤
分组信息
因子,对照组在level第一位
与表达矩阵的列一一对应
项目名称
字符串(不要有特殊字符)
TCGA-XXX
非TCGA数据特殊无要求
-
拿不到count数据如何做差异分析?
-
自行做上游分析得到count
-
tpm:取log,用limma做差异分析
-
fpkm、rpkm:转换为tpm,取log,用limma做差异分析
-
- 不同类型转录组数据的应用

差异分析数据整理
差异分析的前提:count数据
项目取名字
TCGA的数据,统一叫TCGA-xxxx,非TCGA的数据随意起名,不要有特殊字符即可。
proj = "TCGA-CHOL"
表达矩阵
dat = read.table("TCGA-CHOL.htseq_counts.tsv.gz",check.names = F,row.names = 1,header = T)
range(dat)
#> [1] 0.0000 24.1811
#逆转log,发现需要逆转,才逆转
dat = as.matrix(2^dat - 1)
dat[1:4,1:4]
#> TCGA-ZD-A8I3-01A TCGA-W5-AA2U-11A TCGA-W5-AA30-01A
#> ENSG00000000003.13 5254 2476 5132
#> ENSG00000000005.5 1 1 0
#> ENSG00000000419.11 1212 655 1644
#> ENSG00000000457.12 753 346 2652
#> TCGA-W5-AA38-01A
#> ENSG00000000003.13 8249
#> ENSG00000000005.5 1
#> ENSG00000000419.11 1696
#> ENSG00000000457.12 519
# 深坑一个
dat[97,9]
#> [1] 876
as.character(dat[97,9]) #眼见不一定为实吧。
#> [1] "875.999999999999"# 转换为整数矩阵
exp = round(dat)
# 检查
as.character(exp[97,9])
#> [1] "876"
临床信息
clinical = read.delim("TCGA-CHOL.GDC_phenotype.tsv.gz")
clinical[1:4,1:4]
#> submitter_id.samples age_at_initial_pathologic_diagnosis
#> 1 TCGA-ZH-A8Y2-01A 59
#> 2 TCGA-ZH-A8Y7-01A 59
#> 3 TCGA-W7-A93O-01A NA
#> 4 TCGA-W7-A93O-11A NA
#> albumin_result_lower_limit albumin_result_specified_value
#> 1 NA NA
#> 2 3.5 2.4
#> 3 NA NA
#> 4 NA NA
表达矩阵行名ID转换
library(tinyarray)
exp = trans_exp_new(exp)
#> Warning in AnnoProbe::annoGene(rownames(exp), ID_type = "ENSEMBL", species =
#> species): 6.54% of input IDs are fail to annotate...
exp[1:4,1:4]
#> TCGA-ZD-A8I3-01A TCGA-W5-AA2U-11A TCGA-W5-AA30-01A TCGA-W5-AA38-01A
#> DDX11L1 0 0 0 1
#> WASH7P 81 10 146 55
#> MIR6859-1 1 0 11 1
#> MIR1302-2HG 0 0 0 0
基因过滤
需要过滤一下那些在很多样本里表达量都为0或者表达量很低的基因。过滤标准不唯一。
过滤之前基因数量:
nrow(exp)
#> [1] 56514
- 常用过滤标准1
仅去除在所有样本里表达量都为零的基因
exp1 = exp[rowSums(exp)>0,]
nrow(exp1)
#> [1] 48057
- 常用过滤标准2
仅保留在一半以上样本里表达的基因
exp = exp[apply(exp, 1, function(x) sum(x > 0) > 0.5*ncol(exp)), ]
nrow(exp)
#> [1] 28434
分组信息获取
TCGA的数据,直接用make_tcga_group给样本分组(tumor和normal),其他地方的数据分组方式参考芯片数据pipeline/02_group_ids.R
library(tinyarray)
Group = make_tcga_group(exp)
table(Group)
#> Group
#> normal tumor
#> 9 36
保存数据
save(exp,Group,proj,clinical,file = paste0(proj,".Rdata"))
玩转GEO的实用工具
library(tinyarray)
get_count_txt('GSE204753')
##获得超级标准的表达矩阵!!
引用自生信技能树课程,又是爱小洁老师的一天!!
这篇关于学习笔记Day21:转录组差异分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







