本文主要是介绍揭开ChatGPT面纱(4):单轮及多轮文本生成任务实践(completions接口),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、completions接口解析
- 1.参数说明
- 2.prompt
- 三、实践
- 1.单次对话
- 2.多轮对话
openai版本==1.6.1
本系列博客源码仓库:gitlab,本博客对应文件夹04
在前面的博客中介绍过了OpenAI一共有11个接口,其中completions接口常用于文本生成类任务。下面来对completions接口的参数、使用进行一些介绍。
一、completions接口解析
1.参数说明
- completions接口可以传入很多个参数,但这里只介绍常用的几个参数:
model: 要使用的模型的ID。参数中列出了多个预定义的模型常量。
prompt: 一个提供给OpenAI模型的提示,可以是字符串、字符串列表、整数列表或整数数组列表。
max_tokens: 生成的回答可以包含的最大token数。
n: 每个提示生成的回答数量。
temperature: 采样时使用的温度值,影响输出的随机性。取值从0~1.0值越大随机性越强。
2.prompt
在OpenAI的上下文中,prompt 是指用户输入以激发语言模型(如DALL-E、GPT-3等)产生特定输出的文本。这个概念在与OpenAI的API交互时非常重要,因为它直接影响到模型的响应和生成的内容。可以这样理解,prompt就是用户提供给大语言模型的指令。因此提供准确清晰的prompt对于大语言模型生成准确的回答至关重要。
下面通过几个小案例来演示如何使用completions接口完成文本生成相关的任务。
三、实践
1.单次对话
- 在这个案例中,我们让OpenAI扮演一个律师的角色,然后向它提出法律问题咨询。
from openai import OpenAI
import json
import httpx# 读取配置,在上传gitlab时配置文件ignore了
with open('../config/openai.json') as config_file:config = json.load(config_file)client = OpenAI(base_url=config['base_url'],api_key=config['key'],http_client=httpx.Client(base_url=config['base_url'],follow_redirects=True,),
)# 指定模型
MODEL = "gpt-3.5-turbo"# 指定预定义prompt,用于提示模型生成满足要求的文本
prompt = '请你站在一个律师的角度分析用户的提问,并给出专业的回答,以下是用户的提问:'# 实现具体的问答方法
def get_case(question):completions = client.completions.create(model=MODEL,prompt=prompt + question, # 将用户的提问与预定义的prompt前缀拼接起来传入n=1)output = completions.choices[0].message['content']return output# 调用方法,通过终端输入的方式进行提问
user_input = input("请输入法律咨询问题:")
answer = get_case(user_input)
print(f"\n咨询结果:{answer}")- 然后,我向它提出了问题:我最近收到了一张交通罚单,但我确信我当时并没有超速。我应该如何提出异议?
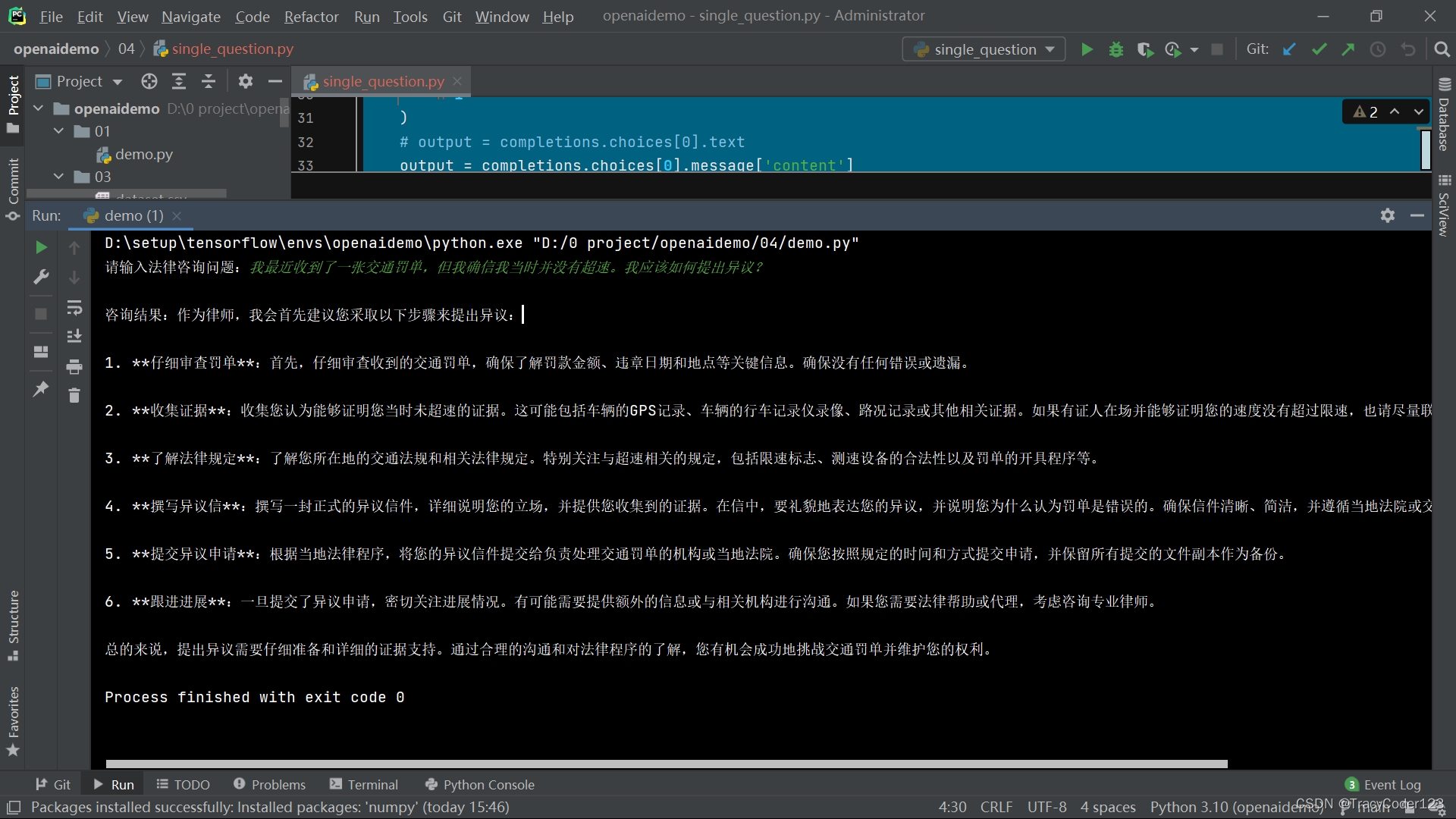
它确实站在律师的角度上给了比较详细的回答。
2.多轮对话
在上一个案例中,我们只能向OpenAI提出一个问题,无法继续进行补充提问。在这一个案例中,我们尝试通过不断拼接prompt的方式来进行多轮对话。
from openai import OpenAI
import json
import httpx# 读取配置,在上传gitlab时配置文件ignore了
with open('../config/openai.json') as config_file:config = json.load(config_file)client = OpenAI(base_url=config['base_url'],api_key=config['key'],http_client=httpx.Client(base_url=config['base_url'],follow_redirects=True,),
)# 指定模型
MODEL = "gpt-3.5-turbo"# 指定预定义prompt,用于提示模型生成满足要求的文本
prompt = '请你站在一个律师的角度分析用户的提问,并给出专业的回答,以下是问答过程:\n'# 实现单次问答的方法
def get_case(question):completions = client.completions.create(model=MODEL,prompt=question,n=1)output = completions.choices[0].message['content']return output# 调用方法,通过终端输入的方式进行提问,不断拼接prompt来让OpenAI模型记住上下文
print('您好,我是一个AI法律咨询机器人,现在开始您的提问吧,您可以通过输入【exit】来结束对话:')
while True:user_input = input("Q:")if user_input.lower() == 'exit':print('bye~')breakprompt = prompt + user_input + '\n'answer = get_case(prompt)prompt = prompt + 'A:' + answer + '\n'print(f"A:{answer}")- 问答过程:
D:\setup\tensorflow\envs\openaidemo\python.exe "D:/0 project/openaidemo/04/multi_turn.py"
您好,我是一个AI法律咨询机器人,现在开始您的提问吧,您可以通过输入【exit】来结束对话:
Q:我最近在工作时受伤了,但我的雇主拒绝承认这是工伤。我需要提供什么证据来申请工伤赔偿?
A:作为律师,首先我会建议您尽快收集和保留与受伤事件相关的所有证据。这些证据可能包括但不限于:1. **医疗记录和诊断报告:** 您应该尽快就医并确保医疗记录详尽记录了您受伤的情况、诊断结果以及治疗过程。医生的诊断对于证明受伤是否与工作相关至关重要。2. **证人证言:** 如果有其他人目击了受伤事件,他们的证言可能对您的案件有帮助。确保尽可能多地收集证人的联系方式,并在必要时寻求他们的证言或证词。3. **工作记录:** 如果您的工作需要您执行某些危险或重体力劳动,您可以提供相关的工作记录来证明受伤可能与工作相关。4. **通知雇主的证据:** 如果您已经向雇主报告了受伤事件,您可能需要提供相关的书面通知或通讯记录作为证据。5. **安全记录和监控录像:** 如果您受伤的地点有安全摄像头或监控设备,相关的录像可能作为证据来证明受伤的情况。6. **就业合同和政策文件:** 您的就业合同或公司政策文件可能包含有关工伤赔偿的条款和程序。确保您理解并遵守这些规定。7. **其他相关证据:** 任何其他与受伤事件相关的证据,如照片、报告或其他文件,也应该被收集和保留。根据您提供的证据,律师可以帮助您评估您的案件并提供相关的法律建议。在提起工伤赔偿申请之前,确保您有足够的证据来支持您的主张是至关重要的。
Q:录音可以吗
A:当然,录音也可以作为证据之一,特别是如果录音能够清晰地表明了受伤事件的发生以及与雇主之间的相关对话或交流。录音可以提供额外的支持,有助于证明您的受伤事件以及雇主对此事件的态度或反应。然而,在录音之前,请确保您了解您所在地区的法律规定,以确保您的录音行为合法,并且不违反任何相关的法律。此外,与律师讨论您计划录音的细节和用途也是一个明智的做法,因为他们可以为您提供针对性的建议,以确保您的权益得到充分保护。
Q:家人可以作为证人吗
A:是的,家人可以作为证人,特别是如果他们目击了您受伤事件的发生或者与您就受伤事件进行了相关的讨论或交流。他们可以提供关于事件经过的描述、您受伤后的情况以及您可能遇到的困难的证言。然而,需要注意的是,家人的证言可能会被视为有偏见的,因为他们与您有亲属关系。在使用家人作为证人时,很可能需要额外的证据来支持他们的证言,以增加其可信度。同时,确保您的律师了解您计划提供的证人,并为您提供相关的建议和指导。
Q:exit
bye~Process finished with exit code 0可以看到,模型明显记住了上下文。
这篇关于揭开ChatGPT面纱(4):单轮及多轮文本生成任务实践(completions接口)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






