本文主要是介绍用户的流失预测分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
项目背景
- 随着电信行业的持续发展,运营商们开始更加关注如何扩大他们的客户群体。研究表明,获取新客户所需的成本要远高于保留现有客户的成本。因此,在激烈的竞争中,保留现有客户成为了一个巨大的挑战。在电信行业中,可以通过数据挖掘等方法分析可能影响客户决策的各种因素,以预测他们是否会流失(停用服务或转投其他运营商)。
数据集
- 数据集一共提供了7000余条用户样本,每条样本包含21列,由多个维度的客户信息以及用户是否最终流失的标签组成,客户信息具体如下:
- 在21列原始属性中,除了最后一列Churn表示该数据集的目标变量(即标签列)外,其余20列按照原始数据集中的排列顺序刚好可以分为三类特征群:客户的基本信息、开通业务信息、签署的合约信息。列说明如下:
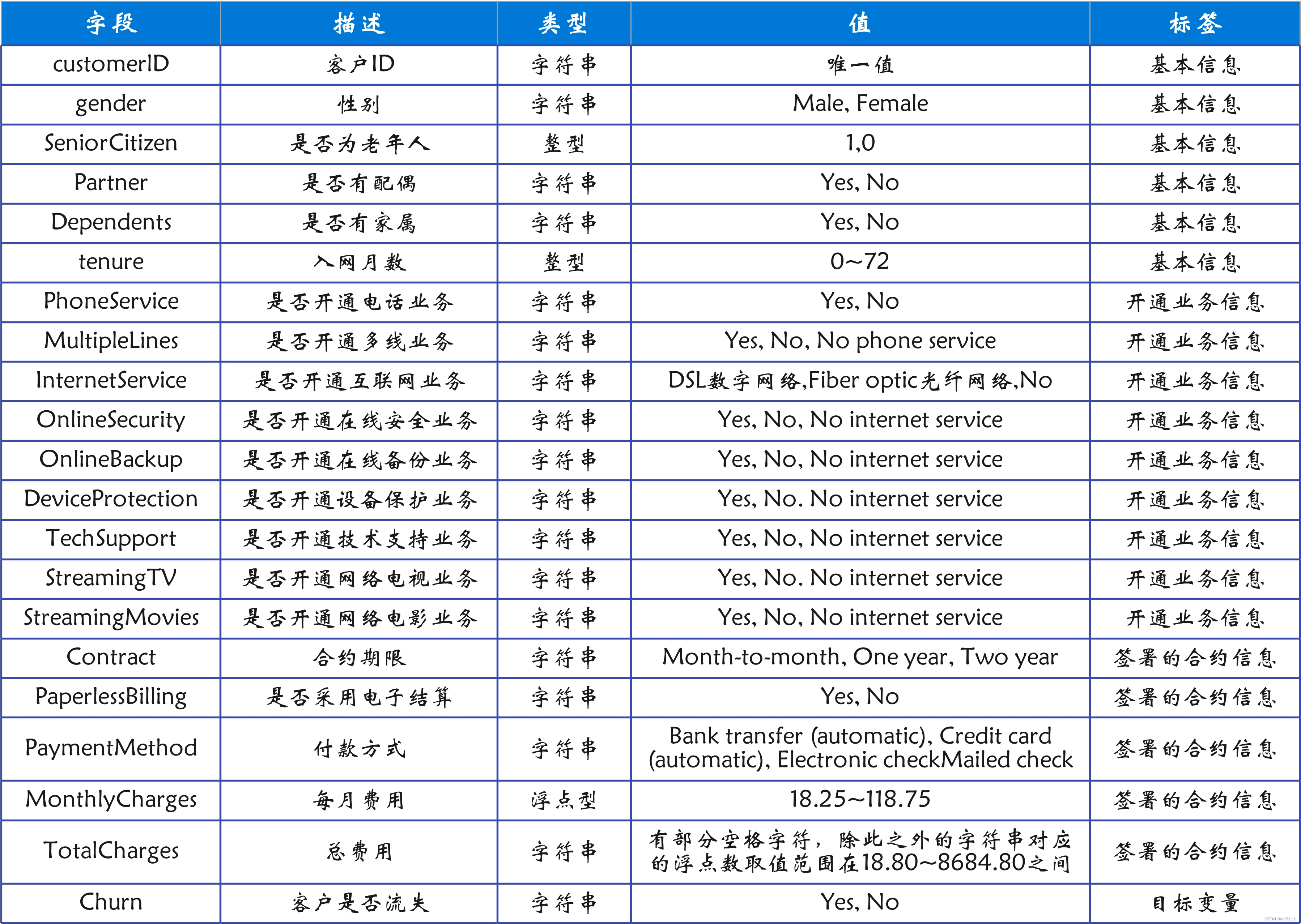
- 注意:
- 电信用户流失预测中,运营商最为关心的是客户的召回率,即在真正流失的样本中,我们预测到多少条样本。其策略是宁可把未流失的客户预测为流失客户而进行多余的留客行为,也不漏掉任何一名真正流失的客户。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore') #忽略弹出的warnings信息
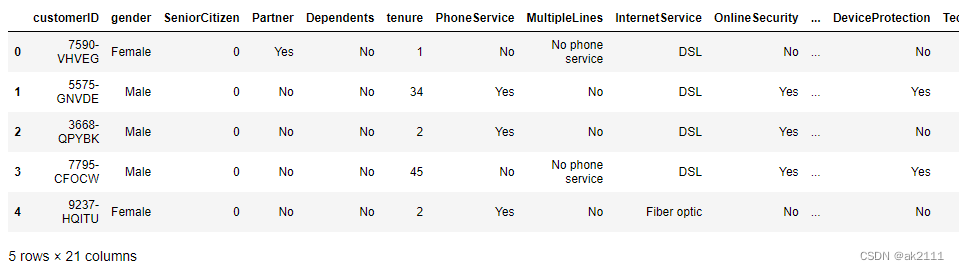
data = pd.read_csv('./user.csv')
data.head()
#是否用重复的行数据
data.duplicated().sum()#0表示不存在重复的行数据
0
#TotalCharges总费用,原始的数据类型是字符串,将其转换成浮点型。
data['TotalCharges'].astype('float')
ValueError: could not convert string to float: ‘’
#根据提示,存在空格,查找后得知,该列中存在11个空格的字符串,导致无法将其转换成浮点型数据
(data['TotalCharges'] == ' ').sum()
11
#将data['TotalCharges']列中对应的' '数据对应的行数据进行删除
drop_indexs = data.loc[data['TotalCharges'] == ' '].index
data.drop(index=drop_indexs,inplace=True)
#进行数据类型的转换
data['TotalCharges'] = data['TotalCharges'].astype('float')
data.info()

#列中是否存在缺失数据
data.isnull().any(axis=0)

对数值型的列进行异常数据的探索
#对SeniorCitizen是否为老年人进行异常数据的探索
data['SeniorCitizen'].value_counts()
0 5890
1 1142
Name: SeniorCitizen, dtype: int64
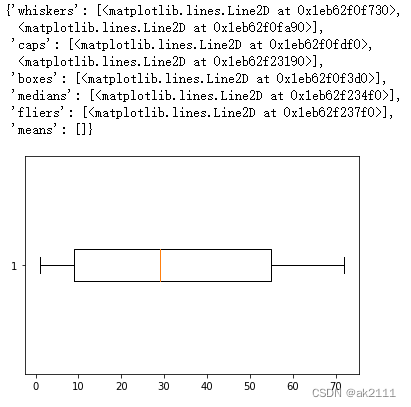
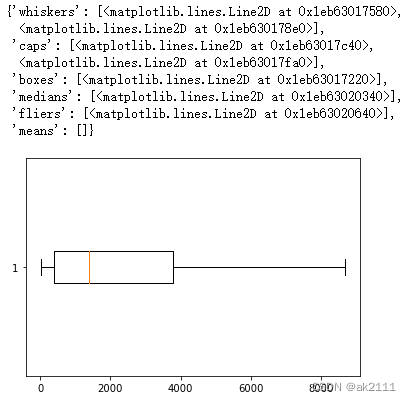
#对入网月数tenure进行箱型图的绘制
plt.boxplot(data['tenure'],vert=False)
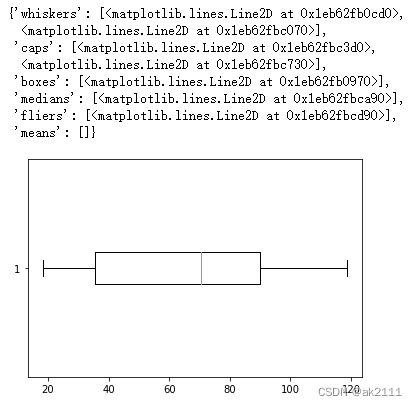
#对MonthlyCharges每月费用进行箱型图的绘制
plt.boxplot(data['MonthlyCharges'],vert=False)
#对总费用TotalCharges进行箱型图的绘制
plt.boxplot(data['TotalCharges'],vert=False)
特征工程
特征抽取
- 在特征介绍图中观察如下几列特征的组成元素:
- ‘MultipleLines’,‘OnlineSecurity’, ‘OnlineBackup’, ‘DeviceProtection’, ‘TechSupport’, ‘StreamingTV’, ‘StreamingMovies’
- 发现MultipleLines特征组成元素为:yes,no和No phone service
- 剩下几列特征的组成元素为:yes,no和No internet service,那么No phone service就表示no,所以可以将其修改为no,从而减少特征组成元素的数量,方便后期进行特征值化。
data['MultipleLines'].replace('No phone service','No',inplace=True)internetCols = ['OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies']for col in internetCols:data[col].replace('No internet service','No',inplace=True)#将特征元素为Yes和No组成的特征进行特征值化操作:map映射
cols = ['Partner','Dependents','PhoneService','MultipleLines','OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies','PaperlessBilling']
for col in cols:data[col] = data[col].map({'Yes':1,'No':0})#对性别gender进行特征值化:map映射
data['gender'] = data['gender'].map({'Male':1,'Female':0})#将剩下的非数值型特征(组成元素大于两个)进行特征值化
cols_name = ['InternetService','Contract','PaymentMethod']
ret = pd.get_dummies(data[cols_name])
data = pd.concat((data,ret),axis=1).drop(columns=cols_name)
data.head()
#将标签数据Churn也转换成数值型数据
data['Churn'] = data['Churn'].map({'Yes':1,'No':0})
特征选择
- 方差过滤
- 相关系数
- PCA降维
- 在项目中,大部分的数据都是非数值型数据,然后经过了特征值化后,特征数据大部分变为了0-1分布。因此无法使用方差过滤、pca和相关系数进行特征选择。
通过可视化分析探测不重要的特征,进行特征选择
- 基本特征对客户流失影响
- 性别、是否老年人、是否有配偶、是否有家属特征对客户流失的影响(占比情况:例如在性别特征中,统计女性流失占不流失的比例and男性)
- ‘gender’, ‘SeniorCitizen’, ‘Partner’, ‘Dependents’
- 这些特征的组成元素只有【是和否】
- 入网月数特征对客户流失的影响
- ‘tenure’
- 该特征的组成元素有多个
- 性别、是否老年人、是否有配偶、是否有家属特征对客户流失的影响(占比情况:例如在性别特征中,统计女性流失占不流失的比例and男性)
#以性别为列,观察不同性别对用户的流失是否会造成影响
#计算出来不同的性别对应的流失用户数量和未流失用户数量
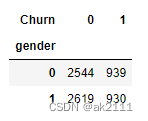
ret = pd.crosstab(data['gender'],data['Churn'])
ret
#计算出男性和女性的流失用户占未流失用的占比
female_p = ret.iloc[0,1] / ret.iloc[0,0]
male_p = ret.iloc[1,1] / ret.iloc[1,0]
female_p,male_p
(0.36910377358490565, 0.3550973654066438)
#批量证实如下几列特征对用户流失是否会造成影响
baseCols = ['SeniorCitizen', 'Partner', 'Dependents']
for col in baseCols:col_df = pd.crosstab(data[col],data['Churn'])p_a = col_df.iloc[0,1] / col_df.iloc[0,0]p_b = col_df.iloc[1,1] / col_df.iloc[1,0]print(col,':',p_a,p_b)
SeniorCitizen : 0.3097620635979542 0.7147147147147147
Partner : 0.4920049200492005 0.24559471365638766
Dependents : 0.4551622418879056 0.18386914833615342
由数据可知:性别对客户流失基本没有影响;年龄对客户流失有影响;是否有配偶对客户流失有影响;是否有家属对客户流失有影响。
- 观察流失率和入网月数之间的关系
- 计算不同入网月数对应的流失率(不同入网月数的流失客户占总客户的比例)
#不同入网月数对应的流失用户的数量
s1 = data.groupby(by='tenure')['Churn'].sum()
#不同入网月数对应的用户总量
s2 = data.groupby(by='tenure')['Churn'].count()#计算流失率
p = s1 / s2plt.plot(p)
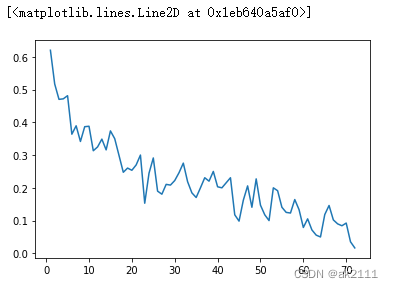
- 随着入网月数的增加流失率呈现下降的趋势!
- 连续性特征的话使用分箱进行离散化后,探索和流失之间的关系。
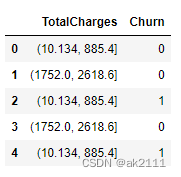
#探究总费用TotalCharges流失率情况,先对TotalCharges进行分箱操作
bin = pd.cut(data['TotalCharges'],bins=10)#将分箱结果和流失结果Churn汇总到一个df中显示
ret = pd.DataFrame((bin,data['Churn'])).T
ret.head()
#计算每一个箱子对应的流失率
s1 = ret.groupby(by='TotalCharges')['Churn'].sum()
s2 = ret.groupby(by='TotalCharges')['Churn'].count()p = s1 / s2p.plot(x = p.values,y=[1,2,3,4,5,6,7,8,9,10])
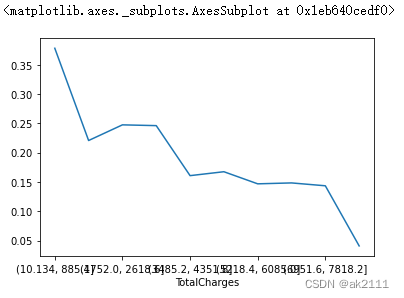
随着总费用的增加,流失率是下降的趋势
- 剩下的合约类型特征、业务类型特征同上进行分析即可,最终发现如下特征对目标标签没有影响,可以将其删除
- ‘gender’、‘PhoneService’、‘StreamingTV’ 和 ‘StreamingMovies’
data.drop(labels=['gender','PhoneService','StreamingTV','StreamingMovies'],axis=1,inplace=True)
观察每月费用和总费用是否会存在较高的相关性
df_p = data[['TotalCharges','MonthlyCharges']]
df_p.corr()
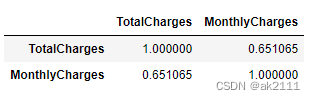
其中 ‘TotalCharges’ 与MonthlyCharges特征的相关系数均大于0.6,即存在较强相关性,因此可以考虑删除该列
data.drop(columns='MonthlyCharges',inplace=True)
#用户id无用可以删除
data.drop(columns='customerID',inplace=True)
#目前保留下来的样本特征大部分都是0-1分布的(map映射和one-hot操作后的),因此没有必要再进行相关的无量纲化了
类别不平衡问题处理
- 不同样本类别数量统计
data['Churn'].value_counts() #样本类别分布不均衡

#提取样本数据
feature = data.loc[:,data.columns != 'Churn']
target = data['Churn']
#使用过抽样处理样本类别分布不均衡的问题
from imblearn.over_sampling import SMOTE
tool = SMOTE(k_neighbors=5)
t_feature,t_target = tool.fit_resample(feature,target)t_target.value_counts()

模型选择&评估
- 召回率代表的意义则是:在真正流失的样本中,我们预测到多少条样本。召回率是运营商们关心的指标,即宁可把未流失的客户预测为流失客户而进行多余的留客行为,也不漏掉任何一名真正流失的客户。
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.naive_bayes import MultinomialNBfrom sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score
使用没有进行样本类别分布不均衡处理后的样本进行建模
x_train,x_test,y_train,y_test = train_test_split(feature,target,test_size=0.2,random_state=2020)
knn = KNeighborsClassifier()
lg = LogisticRegression()
svm = SVC()
mut = MultinomialNB()models = {'knn':knn,'lg':lg,'svm':svm,'mut':mut}
for model_name,model in models.items():model.fit(x_train,y_train)score = f1_score(y_test,model.predict(x_test))print('%s:%f'%(model_name,score))
knn:0.469291
lg:0.591252
svm:0.000000
mut:0.617371
使用进行样本类别分布不均衡处理后的样本进行建模
x_train,x_test,y_train,y_test = train_test_split(t_feature,t_target,test_size=0.2,random_state=2020)
knn = KNeighborsClassifier()
lg = LogisticRegression()
svm = SVC()
mut = MultinomialNB()models = {'knn':knn,'lg':lg,'svm':svm,'mut':mut}
for model_name,model in models.items():model.fit(x_train,y_train)score = f1_score(y_test,model.predict(x_test))print('%s:%f'%(model_name,score))
knn:0.783431
lg:0.815238
svm:0.601643
mut:0.779445
进行了样本类别分布不均衡处理后,相关模型表现的效果综合提升了,其中逻辑回归表现最好。
内容来自大数据分析课程。
这篇关于用户的流失预测分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





