本文主要是介绍图像分割任务中的评价指标简析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
在图像分割领域中,我们需要使用特定的指标来评估实验效果。

上图源自《Fully Convolutional Networks for Semantic Segmentation》
整个评价体系中,被广泛应用的几个评价指标有:
- Precision
- Recall
- Accuracy
- IoU
- F1-Score
- Mean Accuracy / Frequency Weighted Accuracy / Mean IoU / Frequency Weighted IoU等衍生指标
在此对上述用到的指标做出简要分析。这一切还需要从分类任务中的TP/FP/FN/TN的概念说起。

评估指标
TP/FP/FN/TN
在二分类场景(记为类别0和类别1)中,有四种分类结果,即:
- 本该是0被分为0
- 本该是0被分为1
- 本该是1被分为0
- 本该是1被分为1
若以类别1为正例(positive),类别0为负例(negative)。则分类结果可以如下图所示:

则上述四种分类结果分别可以概括为:
- 本该是0被分为0 (True negative,TN,真阴)
- 本该是0被分为1 (False positive,FP,假阳)
- 本该是1被分为0 (False negative,FN,假阴)
- 本该是1被分为1 (True positive,TP,真阳)
上图中,selected elements表示在本次分类任务中被分类为positives的元素,包括TPs和NPs。relevant elements表示在本次分类任务中本应是positives的元素,包括TPs和FNs。
注:TPs是所有TP的意思,类同。
Precision和Recall
指标Precision和Recall是基于对正例分类正确率的评估而建立的。
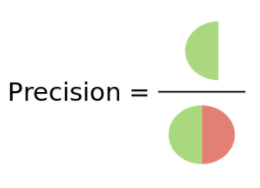
其中Precision是要评估在所有被分类为positives的元素中实际分类正确的概率,即:
P r e c i s i o n = T P s T P s + F P s Precision = \frac {TPs}{TPs+FPs} Precision=TPs+FPsTPs
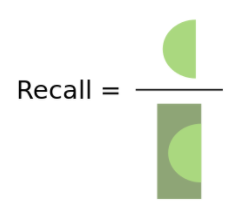
而Recall则是要评估正例分类正确占本应是positives的所有元素的概率,即:
R e c a l l = T P s T P s + F N s Recall = \frac {TPs}{TPs+FNs} Recall=TPs+FNsTPs
简而言之,Precision和Recall的分子都是TPs,都是要评估正例分类正确的水平。
不同的是分母,Precision是以被分类的所有样本为分母,分母可随每次采样元素变化而变化。Precision的意义在于衡量是否有误判,希望误判越少越好。
而Recall则是以原本所有的positives元素为分母,分母不随采样元素变化而变化。Recall的意义在于衡量是否有遗漏,希望遗漏越少越好。
Accuracy
说到Accuracy,很容易和Precision搞混,实际上二者不一样。Accuracy实际上衡量范围更广,相比于Precision只将TP作为考虑范围,Accuracy则是将TP和TN都纳入评估范围。
A c c u r a c y = T P s + T N s T P s + F P s + T N s + F N s = T P s + T N s T o t a l s \begin{aligned}Accuracy &= \frac {TPs+TNs}{TPs+FPs+TNs+FNs}\\ &=\frac {TPs+TNs}{Totals}\end{aligned} Accuracy=TPs+FPs+TNs+FNsTPs+TNs=TotalsTPs+TNs
IoU
IoU和Precision/Recall比较相近,同样是对正例分类正确的水平进行衡量,不同的是IoU的分母是Precision和Recall分母的并集。正如其全名Intersection over Union(交并比),即selected elements和relevant elements的交集比上两者的并集,实际上就是:
I o U = T P s T P s + F P s + F N s IoU = \frac {TPs}{TPs+FPs+FNs} IoU=TPs+FPs+FNsTPs
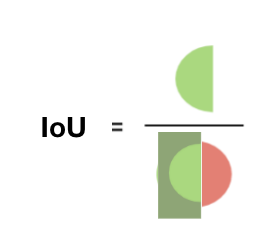
F1-Score
F1-Score是Precision和Recall的调和平均数。
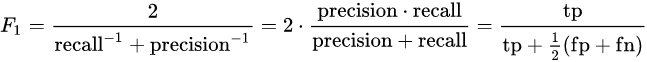
在上面说到Precision和Recall,提到Precision是以被分类的所有样本为分母,Recall则是以原本所有的positives元素为分母。二者之间并没有建立直接联系,如果一个分类器,Precision很高但是Recall很低,或者Recall很高但是Precision很低,这两种分类器都是不好的,都是我们不希望的。所以我们采用F1-Score来建立Precision和Recall的联系。
在数学中,我们知道调和平均数是永远小于等于算术均值平均数的,当用于求两个数的平均数时,如果直接用算术平均作为结果,那么两数之间的差异将被大的值削平,而调和平均数则不会极大削平这种大的差异,得到的结果更倾向于小的值。
例如,1和9的平均,算术平均数为5,而调和平均数约为2。
采用F1-Score能够更好的同时衡量Precision和Recall,也就是希望在遗漏少的前提下误判也少,这样得到的F1-Score才会高。
Mean / Frequency Weighted 衍生
用于多分类任务中,其中Mean IoU表示计算每一类的IoU后求均值,Frequency Weighted IoU表示根据每一类出现的频率对各个类的IoU进行加权求和。Mean Accuracy和Frequency Weighted Accuracy类同。
Python实现
对于上述评估指标,一般由混淆矩阵计算后处理得到。

对于猫狗二分类问题,分类结果如下:
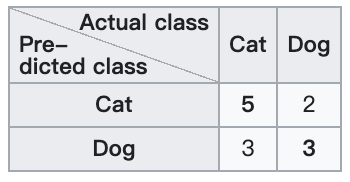
若以猫为正类,则混淆矩阵如下:

计算混淆矩阵
import numpy as npclass Metric(object):def __init__(self, n_classes):self.n_classes = n_classesself.confusion_matrix = np.zeros((n_classes, n_classes))def _fast_hist(self, label_true, label_pred, n_class):mask = (label_true >= 0) & (label_true < n_class)hist = np.bincount(n_class * label_true[mask].astype(int) + label_pred[mask], minlength=n_class ** 2).reshape(n_class, n_class)return histdef update(self, label_trues, label_preds):for lt, lp in zip(label_trues, label_preds):self.confusion_matrix += self._fast_hist(lt.flatten(), lp.flatten(), self.n_classes)
根据混淆矩阵计算评价指标
# For multi-classes
def get_scores(self):"""Returns accuracy score evaluation result.- Overall accuracy- Mean accuracy- Frequency Weighted acc- Mean IoU- Overall F1"""hist = self.confusion_matrixFP = hist.sum(axis=0) - np.diag(hist)FN = hist.sum(axis=1) - np.diag(hist)TP = np.diag(hist)precision = TP / (TP+FP)recall = TP / (TP+FN)f1 = (2 * (precision*recall) / (precision + recall)).mean()acc = np.diag(hist).sum() / hist.sum()acc_cls = np.diag(hist) / hist.sum(axis=1)acc_cls = np.nanmean(acc_cls)iou = np.diag(hist) / (hist.sum(axis=1) +hist.sum(axis=0) - np.diag(hist))mean_iou = np.nanmean(iou)freq = hist.sum(axis=1) / hist.sum()fwavacc = (freq[freq > 0] * iou[freq > 0]).sum()cls_iou = dict(zip(range(self.n_classes), iou))return ({"Overall Acc: \t": acc,"Mean Acc : \t": acc_cls,"FreqW Acc : \t": fwavacc,"Mean IoU : \t": mean_iou,"Overall F1: \t": f1},cls_iou,)
完整代码
import numpy as npclass Metric(object):def __init__(self, n_classes):self.n_classes = n_classesself.confusion_matrix = np.zeros((n_classes, n_classes))def _fast_hist(self, label_true, label_pred, n_class):mask = (label_true >= 0) & (label_true < n_class)hist = np.bincount(n_class * label_true[mask].astype(int) + label_pred[mask], minlength=n_class ** 2).reshape(n_class, n_class)return histdef update(self, label_trues, label_preds):for lt, lp in zip(label_trues, label_preds):self.confusion_matrix += self._fast_hist(lt.flatten(), lp.flatten(), self.n_classes)# For multi-classesdef get_scores(self):"""Returns accuracy score evaluation result.- Overall accuracy- Mean accuracy- Frequency Weighted acc- Mean IoU- Overall F1"""hist = self.confusion_matrixFP = hist.sum(axis=0) - np.diag(hist)FN = hist.sum(axis=1) - np.diag(hist)TP = np.diag(hist)precision = TP / (TP+FP)recall = TP / (TP+FN)f1 = (2 * (precision*recall) / (precision + recall)).mean()acc = np.diag(hist).sum() / hist.sum()acc_cls = np.diag(hist) / hist.sum(axis=1)acc_cls = np.nanmean(acc_cls)iou = np.diag(hist) / (hist.sum(axis=1) +hist.sum(axis=0) - np.diag(hist))mean_iou = np.nanmean(iou)freq = hist.sum(axis=1) / hist.sum()fwavacc = (freq[freq > 0] * iou[freq > 0]).sum()cls_iou = dict(zip(range(self.n_classes), iou))return ({"Overall Acc: \t": acc,"Mean Acc : \t": acc_cls,"FreqW Acc : \t": fwavacc,"Mean IoU : \t": mean_iou,"Overall F1: \t": f1},cls_iou,)def reset(self):self.confusion_matrix = np.zeros((self.n_classes, self.n_classes))

参考资料
[1] Fully Convolutional Networks for Semantic Segmentation
[2] F-score - Wikipedia
[3] 语义分割之评价指标 - 知乎
[4] 机器学习中的F1度量,为什么定义为precision和recall的调和平均,而不是算术平均? - 知乎
[5] 评估指标中IoU/precision/recall/tp/fp/fn/tn的个人理解_TracelessLe的专栏-CSDN博客
[6] Confusion matrix - Wikipedia
[7] FaceParsing.PyTorch/metrics.py at master · TracelessLe/FaceParsing.PyTorch
[8] python实现混淆矩阵 - 知乎
[9] 混淆矩阵 - 维基百科,自由的百科全书
这篇关于图像分割任务中的评价指标简析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





