本文主要是介绍《走近大数据之Hive进阶》学习笔记(2),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
建议:请先看一下鄙人另一篇学习笔记《走近大数据之Hive入门》,再看这个进阶的效果更好!
http://blog.csdn.net/to_Baidu/article/details/52432217
第一章 课程简介
1-1 课程简介
Hive不支持传统数据库中insert插入操作,可通过load语句和sqoop进行数据的导入。
学习目标:
1. hive的数据导入;
2. hive的数据查询;
3. hive的java客户端和自定义函数。
学习的必备基础:
- hive的体系结构和基本操作
- java编程
- Linux的基本操作
第二章 Hive数据的导入
2-1 使用load语句执行数据的导入
使用load语句
-语法:load data [local] inpath ‘filepath’ [overwrite] into table tablename [partition (partcol1=val1, partcol2=val2,“`)]
例如:
–将student01.txt导入t2:
Load data local inpath ‘/root/data/student01.txt’ into table t2;
上面的这种方式一次只能导入一个文件,下面可实现多文件导入。
例如:
–将/root/data下的所有数据文件导入t3表中,并且覆盖原来的数据:
load data local inpath ‘/root/data/’ overwrite into table t3;
目录只要写到相关目录即可,不必具体指定到某个文件。
–将HDFS中/input/student01.txt导入到t3,此时不需要加local关键字:
load data inpath ‘/input/student01.txt’ overwrite into table t3;
–将data1.txt导入partition_table
load data local inpath ‘/root/data/data1.txt’ into table partition_table partition (gender=’M’);
2-2 使用sqoop进行数据的导入
Sqoop是apache下的一个框架,专门做数据的导入和导出。
Sqoop要先安装:下载,tar包安装,再设置两个环境变量即可。
Linux解压tar包的命令 :tar –zxvf 包名
#export HADOOP_COMMON_HOME-~hadoop的安装目录
#export HADOOP_MAPRED_HOME-~hadoop的安装目录
① 使用sqoop导入oracle数据到HDFS中,sqoop语句中的‘–’表示变量
./sqoop import –connect jdbc:oracle:thin:@192.168.56.101:1521:orcl –username scott –password tiger –table emp –columns ‘empno,ename,job,sal’ -m 1 –target-dir ‘/sqoop/emp’
注释:-m表示mapreduce的进程数,如次数进程数是一个
②使用sqoop导入oracle数据到hive中
./sqoop import –hive-import –connect jdbc:oracle:thin:@192.168.56.101:1521:orcl –username scott –password tiger –table emp –m 1 –columns ‘empno,ename,job,sal’
③使用sqoop导入oracle数据到hive中,并且指定表名
./sqoop import –hive-import –connect jdbc:oracle:thin:@192.168.56.101:1521:o**重点内容**rcl –username scott –password tiger –table emp –m 1 –columns ‘empno,ename,job,sal’ –hive-table emp1
④ 使用sqoop导入oracle数据到hive中,并使用where条件
./sqoop import –hive-import –connect jdbc:oracle:thin:@192.168.56.101:1521:orcl –username scott –password tiger –table emp –m 1 –columns ‘empno,ename,job,sal’ –hive-table emp2 –where ‘DEPTNO=10’
⑤ 使用sqoop导入oracle数据到hive中,并使用查询语句
./sqoop import –hive-import –connect jdbc:oracle:thin:@192.168.56.101:1521:orcl –username scott –password tiger –m 1 –query ‘select * from emp where SAL<2000 AND $CONDITIONS’ –target-dir ‘/sqoop/emp5’ –hive-table emp5
注意:必须有AND $CONDITIONS,固定格式
⑥ 使用sqoop将hive中的数据导出到oracle中。
./sqoop export –connect jdbc:oracle:thin:@192.168.56.101:1521:orcl –username scott –password tiger -m 1 –table myemp –export-dir **
注意:需要oracle数据库中先有myemp这个表,并且格式跟*中的一样。
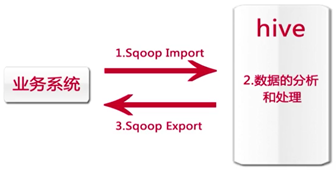
正真的企业级环境数据迁移如下图:
第三章 Hive的数据查询
3-1简单查询和fetch task
Hive中很多查询会转换成mapreduce的作业来执行,但有少量的查询语句不用转换成MapReduce作业。如select * from student。
为什么当在hive中执行比较简单的查询语句时,有时速度比传统的oracle速度还要慢?
因为:1、跟自己机器的配置有关系;2、使用hive要操作数据仓库,当仓库中的数据比较多时,使用hive的速度会比较快。
查询表达式中可以进行一些算术操作,并且可以用hive中的内置函数nvl()将值为null的字段转换成0。
例如:
-查询员工信息:员工号,姓名,月薪,年薪。奖金,年收入
select empno,ename,sal,sal*12,comm,sal*12+nvl(comm,0) from emp;
-查询奖金为null的员工:
select * from emp where comm=null ×错误 应该是:select * from emp where comm is null
distinct:去重,并且作用后面的所有列(组合起来的重复)
简单查询的fetch task功能
- 从hive0.10.0版本开始支持
这篇关于《走近大数据之Hive进阶》学习笔记(2)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





