本文主要是介绍1.搜索引擎的历史,搜索引擎起步,发展,繁荣,搜索引擎的原理,搜索技术用途,信息检索过程,倒排索引,什么是Lucene,Lucene快速入门,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一:
1 搜索引擎的历史
萌芽:Archie、Gopher
Archie:搜索FTP服务器上的文件
Gopher:索引网页
2 起步:Robot(网络机器人)的出现与spider(网络爬虫)
Robot基于网络的,可以执行特定任务的程序
Spider:特殊的机器人,网络爬虫,爬取互联网上的信息(可以是文件,网络)----网络自动下载程序
3 发展阶段:excite,galaxy,yahoo这些公司做搜索
4 繁荣:infoseek,AltaVista,Google和百度
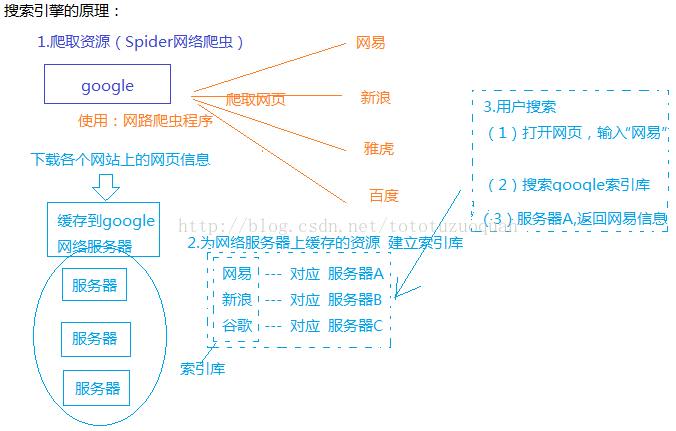
5 搜索引擎的原理:
有三步
A 爬取资源
B 建立索引
C 用户索引
二 搜索技术能用来做什么?
案例:
A 使用word中Ctrl+F进行检索:原理:从文档自上而下搜索
B 从windows的资源管理器中看搜索:搜索每个文件夹,检索需要的文件
C MyEclipse中的help contents:原理:站内搜索
D Baidu和Google提供互联网中各种资源的搜索:原理:垂直搜索
三:信息检索的过程
A 构建文本库
B 建立索引
C 进行搜索
D 对结果进行排序
四:倒排索引
倒排搜索区别于传统查找,传统线性查找,按照信息从前到后,依次查找(效率),倒排搜索,记录信息出现的位置,通过索引内容快速找到关键信息,类似书记的目录!
五:什么是Lucene(全文检索框架,apache提供)
A Lucene是一套用于全文检索和搜寻的开源程式接口,能够做全文索引和搜寻,在Java开发环境里Lucene是一个成熟的免费开发源代码工具
B Lucene是提供了一个简单却强大的应用程式接口,能够做全文检索索引和搜寻,在Java开发环境里Lucene是一个成熟的免费的开放源代码工具。
全文检索:对数据建立全文索引,根据全文索引搜索信息
solr 是高性能搜索服务器,基于Lucene
Lucene并不是现成的搜索引擎产品,但可以用来制作搜索引擎产品
Lucene是搜索引擎的开发技术,Lucene并不是一个现成的产品
官网:http://lucene.apache.org
六 什么是全文件检索
全文检索:对需要查找数据的每一个单词建立索引
七:Lucene快速入门(5个步骤)
A 下载Lucene的卡发包,Lucene-3.6.2.zip
B 导入jar包到工程Lucene-core-3.6.2.jar
C 将数据转换成为文档对象Document
D 建立索引Index
E 查询索引获取数据
这篇关于1.搜索引擎的历史,搜索引擎起步,发展,繁荣,搜索引擎的原理,搜索技术用途,信息检索过程,倒排索引,什么是Lucene,Lucene快速入门的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









