本文主要是介绍基于少样本学习EEG/SEEG数据癫痫预警和脑电识别,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近的三篇文章都中了。因此有时间来整理之前的工作;
立体脑电数据包含了大脑癫痫电信号,具有高信噪比,高采样率,可以进行病灶定位等特点。因此对立体脑电进行数据分析和数据挖掘具有很大的医学研究价值。但是目前基于立体脑电信号数据挖掘工作还较少,尤其是基于深度学习等方法的工作。立体脑电采集成本较高,受试者较少,所以需要大量训练数据的传统的神经网络分类模型并不能很好解决立体脑电分类任务。同时,立体脑电数据的电极位置不固定,头皮脑电的数据预处理方法不适用于立体脑电数据。因此从立体脑电数据出发,如何进行的数据预处理,利用立体脑电多信道信息,构建出泛化能力较好的深度学习网络对立体脑电癫痫信号识别是一大挑战。
在实验中我们会经常发现,在训练集上效果较好的模型在新的病人身上的性能并不好。这是因为脑电信号带有很明显的个体差异;这种差异会干扰模型的判别。少样本学习是很好的一个途径去解决量较少的情况。少样本学习通过构造众多的数据集,可以提高模型的泛化能力。
少样本学习的核心思想是学习多个任务的先验知识,使模型适用于有监督的已知少量样本标签的新任务。Vinyals等人采用了基于深度神经网络的度量学习的思想(Matching networks),将一个标记好的数据集映射到未标记的数据集上实现模型的快速拟合。Snell等人学习到一个度量空间(Prototypical networks),通过计算每个类的原型的表示距离从而对其分类。Sung等人则构建一个端到端的关系网络(Relation Network),它是基于深度学习的度量网络,关系网络可以通过计算查询样本与每一个新的类别样本之间的关系得分来对新的类别进行分类,从而无需整体地更新整个网络。Finn 等人提出了一种模型无关的少样本学习方法(Meta Learning),该方法目标是针对于各种学习任务来训练模型,通过二次的梯度更新策略,通过少量已知标签样本就可以适应于新的学习任务。
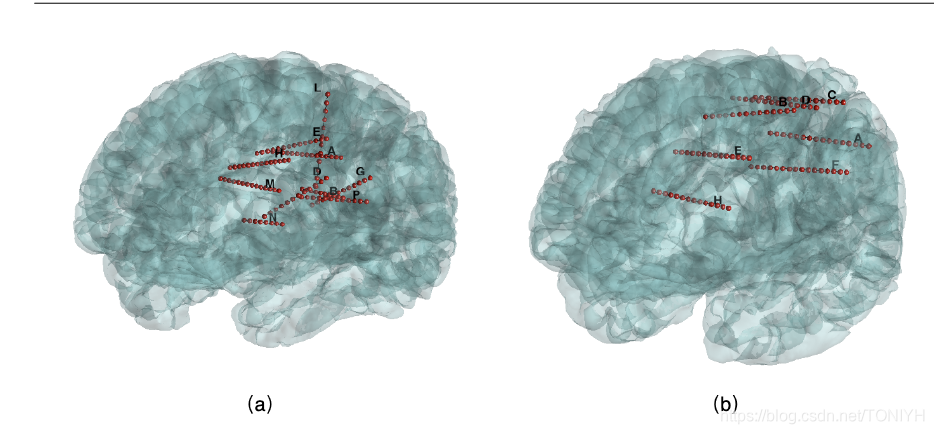
如下是两个人不同的SEEG数据信道分布图;之后我会介绍如何合理的处理这种信道数据图。
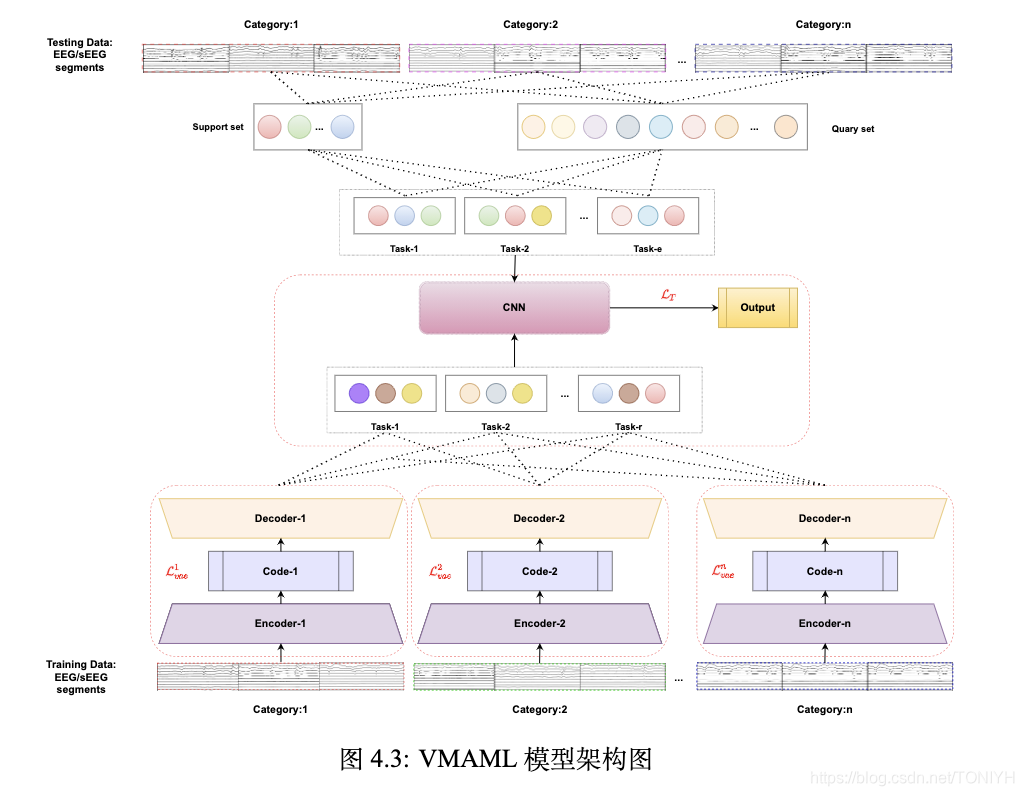
我们通过特定的方法来排列信道构成矩阵,然后通过切割矩阵来获得数据片段。这个数据片段就是模型的输入,首先对于每一类的数据可以通过VAE编解码,这样能够提取到每一类的脑电数据的特征,然后通过水机采样的方法来构建任务集。再结合MAML(Model Agnostic Meat Lrarning)来实现模型的分类,这样做的好处能够借助于变分自编码器和少样本学习提高模型的泛化能力。
具体的结构图如下;
具体的算法如下:

数据集
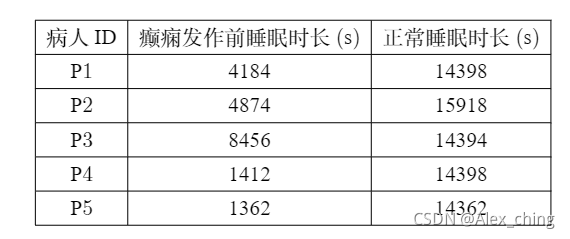
实验的数据如下,我们采集了5位病人的数据,采用留一法进行验证;
实验的结果如下,可以看到我们的模型取得了最好的结果。
 对提取的特征分成5类进行聚类分析并且可视化如下:
对提取的特征分成5类进行聚类分析并且可视化如下:
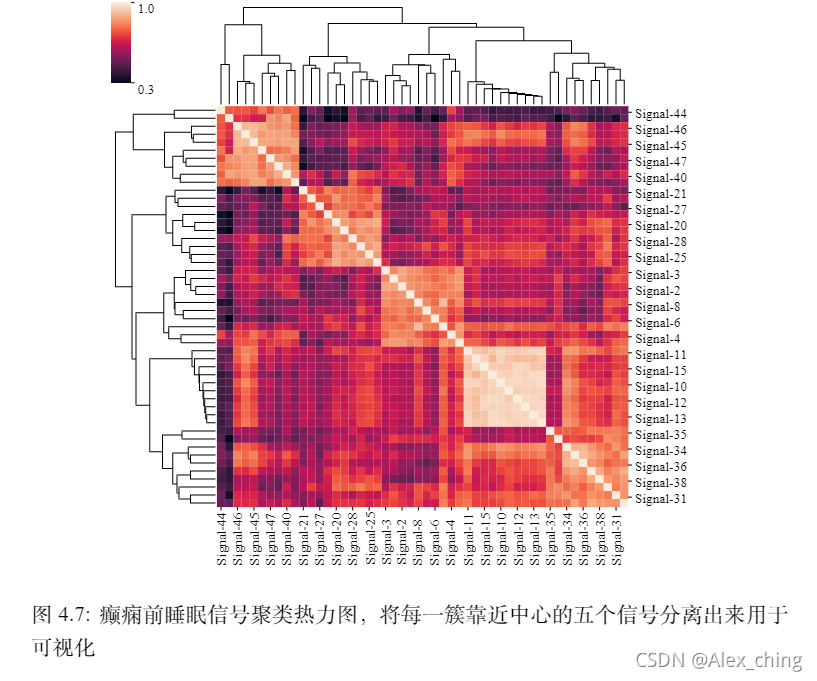
我们在特征分析中发现了模型的性能和某种特征密度相关,如下所示。

以上就是我论文的内容,改论文已经被American Medical Informatics Association: AMIA录用,论文题目为:Characterizing Brain Signals for Epileptic Pre-ictal Signal Classification。等见刊了大家可以看看论文细节。
这篇关于基于少样本学习EEG/SEEG数据癫痫预警和脑电识别的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




