本文主要是介绍存内计算对大语言模型推理的加速,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本篇文章集中讨论了存内计算技术在加速大语言模型推理方面的潜力,从大语言模型的背景知识出发,探讨目前其面临的挑战,进而剖析两篇经典的文献以彰显存内计算有望解决目前大语言模型在推理加速方面存在的问题,最后围绕大语言模型与存内计算的结合展开构想。
- 大语言模型的背景知识及其面临的挑战
(一)大语言模型的基础概念
通俗来说,大语言模型(Large Language Model,LLM)是基于海量文本数据训练的、包含百亿级别(或更多)参数的深度学习模型。它不仅能够生成自然语言文本,还能够深入理解文本含义,处理各种自然语言任务,如文本摘要、问答、翻译等。
大语言模型的表现往往遵循扩展法则,但是对于某些能力,只有当语言模型规模达到某一程度才会显现,这些能力被称为“涌现能力”,代表性的涌现能力包括三点:其一是具备上下文学习能力,可以通过完成输入文本的词序列来生成测试实例的预期输出,而无需额外的训练或梯度更新;其二是具有指令遵循的行为,通过对指令格式化的多任务数据集的混合进行微调,LLM在微小的任务上表现良好;其三是拥有循序渐进的推理特点,通过思维链推理策略,LLM可以通过利用涉及中间推理步骤的prompt机制来解决此类任务得出最终答案。
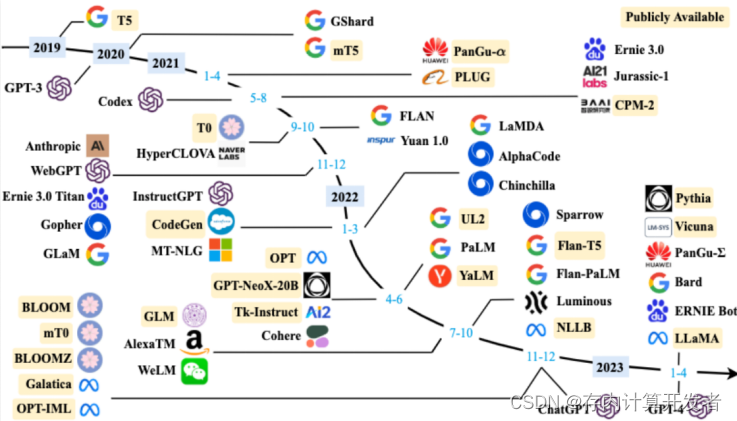
图1 LLM的发展时间线
目前具有代表性的LLM有GPT-4、LLaMA、PaLM等(如图1),它们在各种自然语言处理任务,如机器翻译、文本摘要、对话系统、问答系统等应用中展现出了强大的能力。此外,LLM通过提供增强的数据分析、模式识别和预测建模功能,在推动医疗保健、金融和教育等各个领域的创新方面发挥了重要作用。这种变革性的影响凸显了探索和理解这些模型的基础以及它们在不同领域广泛应用的影响的重要性。
(二)大语言模型面临的挑战
在传统计算架构中执行LLM推理时,主要面临计算延迟、能源消耗和数据传输瓶颈这几个挑战。随着模型如GPT和BERT等的参数规模达到数十亿甚至更多,这些模型在推理过程中需要进行大量的计算,特别是矩阵运算和激活函数处理。这种高密度的计算需求导致显著的延迟,特别是在需要快速响应的应用场合,如实时语言翻译或交互式对话系统。
此外,随着模型大小的增加,所需的计算资源也相应增长,这不仅导致能源消耗大幅提升,也增加了运营成本和环境负担。在数据中心或云环境中运行这些大型模型需要消耗大量电力,高能耗也限制了这些模型在边缘设备上的应用。数据传输瓶颈是另一个关键问题。因为LLM的参数量巨大,无法全部装入处理器的高速缓存中,这就需要频繁地从较慢的主存中调入数据,增加了推理延迟并进一步提高了能源消耗。
存内计算技术(Compute-In-Memory,CIM)通过在内存芯片中直接进行数据处理,有效地减少了数据在传统计算架构中从存储器到处理器之间的传输需求。这种减少数据移动的方式能显著降低能源消耗,并减少推理任务的延迟,使得模型响应更为迅速和高效。考虑到目前LLM面临的挑战,存内计算或许是解决这一问题的有效方法。
- 案例剖析一——X-Former:In-Memory Acceleration of Transformers
X-Former架构是为加速LLM如Transformers设计的CIM硬件平台。这一架构通过通过在存储单元内直接进行计算、优化参数管理、提升计算效率和硬件利用率,有效地克服了传统计算硬件在处理自然语言任务时的高能耗、高延迟、参数管理难度和扩展性限制等性能瓶颈。
X-Former的独特之处在于其集成了特定的硬件单元,如投影引擎和注意力引擎,它们分别针对模型的不同计算需求进行优化(图2)。投影引擎使用NVM来处理静态的、计算密集型的矩阵运算,而注意力引擎则利用CMOS技术优化频繁且动态变化的计算任务。这种设计使得X-Former能够在执行过程中几乎消除对外部内存的依赖,因为大部分数据处理都在内存阵列内完成。
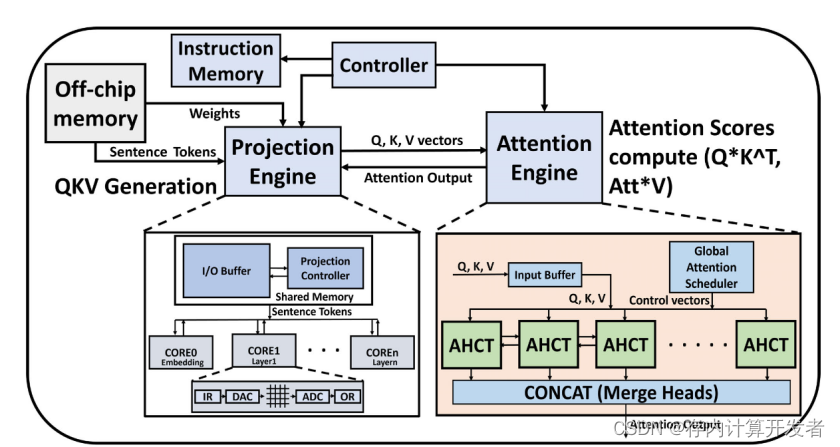
图2 X-Former硬件加速器由两种不同的计算引擎组成,投影引擎和注意力引擎
此外,通过采用层内序列阻塞数据流的方法,X-Former进一步优化了数据处理流程,这不仅减少了内存占用,而且通过并行处理提高了整体的计算速度。这种方法特别适合处理自注意力运算,因为它允许同时处理多个数据块,而不是按照传统顺序处理整个数据集。这样的设计使得X-Former在硬件利用率和内存需求方面都表现优异,尤其是在处理具有大量参数和复杂计算需求的模型时。
通过实际性能评估,X-Former在处理Transformer模型时显示出了显著的性能优势。与传统的GPU和其他基于NVM的加速器相比,X-Former在延迟和能耗上均有大幅改进。例如,与NVIDIA GeForce GTX 1060 GPU相比,在延迟和能耗上分别改善了69.8倍和13倍;与现有的最先进的NVM加速器相比,改善了24.1倍和7.95倍。这种显著的性能提升,证明了X-Former在自然语言处理领域特别是在处理复杂和参数庞大的模型如GPT-3和BERT时,硬件加速的巨大潜力。
- 案例剖析二——iMCAT:In-Memory Computing based Accelerator for Transformer Networks for Long Sequences
2021年由Laguna等人提出的iMCAT的存内计算架构使用交叉阵列(XBars)和内容可寻址存储器(CAMs)的组合来加速Transformer网络。其中XBars是一种可以实现高度并行的矩阵向量乘法(MVM)的电路,一般用于实现RNN或记忆增强神经网络。加入了SDP-MHA(Multi-head Self-Attention)的机制后,XBars被证实比目前常用的Transformer注意力机制更适应并行计算处理(图3)。然而,记忆项的数量会随着序列长度的变化而变化,且随着序列长度的增加,延时和能耗会急剧增加。iMCAT架构通过存内计算的方法直接在存储单元中进行数据处理,从根本上减少了处理器与内存之间的数据传输需求,弥补了XBars加速Transformer网络的缺陷。
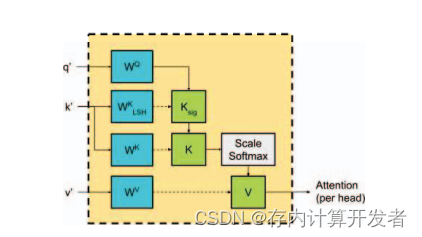
图3 LSH + SDP注意力MHA映射
CIM一大优势是其在执行复杂算法时的灵活性,可以在硬件的基础上使用高效算法简化计算或存储寻址。iMCAT通过集成局部敏感哈希(LSH)技术将输入元素映射到哈希表中,利用散列函数简化了键(K)与查询(Q)之间的匹配过程,iMCAT利用CAMs进行寻址,只在每个查询(Q)向量与其相似的键(K)向量之间计算Transformer模型的注意力得分,从而减少了需要计算的元素对数量。通过预筛选出与给定查询向量相关性较高的键向量,可以在不牺牲模型性能的前提下,显著提高注意力机制的计算效率。在处理包含大量序列元素的场景中,这种方法可以大大减少了计算量,有效降低了执行自注意力机制所需的时间和能量消耗。
另外,高度并行化的CIM硬件设计是iMCAT架构成功的另一个关键点。其中每个自注意力头部的计算都分配到独立的CIM单元上,每个CIM单元都包含专门的XBars分别处理不同的查询(Q)、键(K)和值(V)向量集。并行化处理不仅加速了自注意力的计算过程,还减轻了单一处理单元的计算负担,从而进一步提高了整体系统的性能和响应速度。通过这种方式,即使在处理极长的序列时,iMCAT也能保持高效的运算效率。
- 总结与展望
CIM这种高效的计算方式不仅提高了处理速度,还使得在计算资源受限的环境中部署复杂的语言模型成为可能,极大地扩展了其应用场景,尤其是在对实时性要求极高的任务中表现出巨大的潜力。尽管CIM技术在加速LLM推理中表现出许多优势,但目前仍存在一些技术和实际应用的局限。例如,CIM技术在实际部署时可能需要特定的硬件支持和优化,这可能增加系统的复杂性和成本。此外,现有的CIM实现可能还未完全适用于所有类型的计算任务,对于某些特定的模型或数据类型,其效能提升可能不如预期。
未来,随着硬件技术的持续进步和优化,CIM技术有望支持更为复杂的算法并进一步提升计算精度和能效,在推动智能设备更广泛的普及、增强边缘计算能力以及提高数据安全性方面发挥更加重要的作用。
参考资料
- 大语言模型综述——http://ai.ruc.edu.cn/research/science/20230605100.html
- 什么是LLM大语言模型?Large Language Model,从量变到质变——知乎(https://zhuanlan.zhihu.com/p/622518771)
- S. Sridharan, J. R. Stevens, K. Roy and A. Raghunathan, "X-Former: In-Memory Acceleration of Transformers," in IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 31, no. 8, pp. 1223-1233, Aug. 2023.
- A. F. Laguna, A. Kazemi, M. Niemier and X. S. Hu, "In-Memory Computing based Accelerator for Transformer Networks for Long Sequences," 2021 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 2021, pp. 1839-1844.
- N. Challapalle, et al. Farm: A flexible accelerator for recurrent and memory augmented neural networks. Journal of Signal Processing Systems, Jun 2020.
- A. Ranjan, et al. X-mann: A crossbar based architecture for memory augmented neural networks. pages 1–6, 06 2019.
- CHRISTOFOROS KACHRIS. A Survey on Hardware Accelerators for Large Language Models. arXiv:2401.09890 [cs.AR]
这篇关于存内计算对大语言模型推理的加速的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




