本文主要是介绍7年来Google首次更新transformer框架,性能提升50%,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Transformer模型回顾
"Attention is All You Need" 是一篇著名的深度学习论文,由 Ashish Vaswani 等人撰写。这篇论文首次提出了 Transformer 模型,该模型在自然语言处理领域取得了重大成功。该论文于 2017 年 6 月在第 31 届 AAAI 会议(Association for the Advancement of Artificial Intelligence)上公布,并于同年 11 月在 arXiv 上发表。

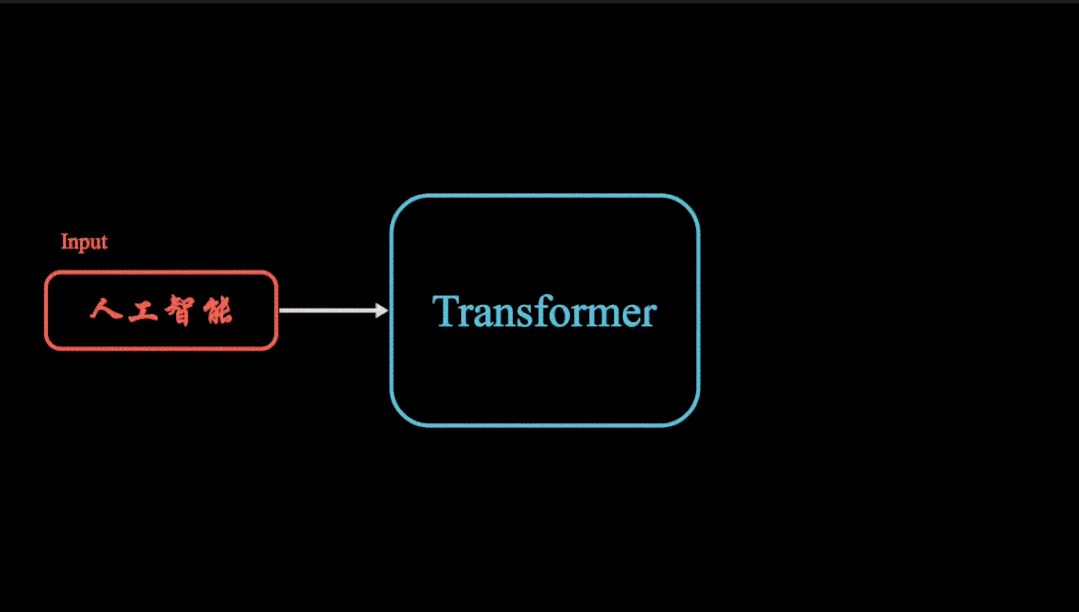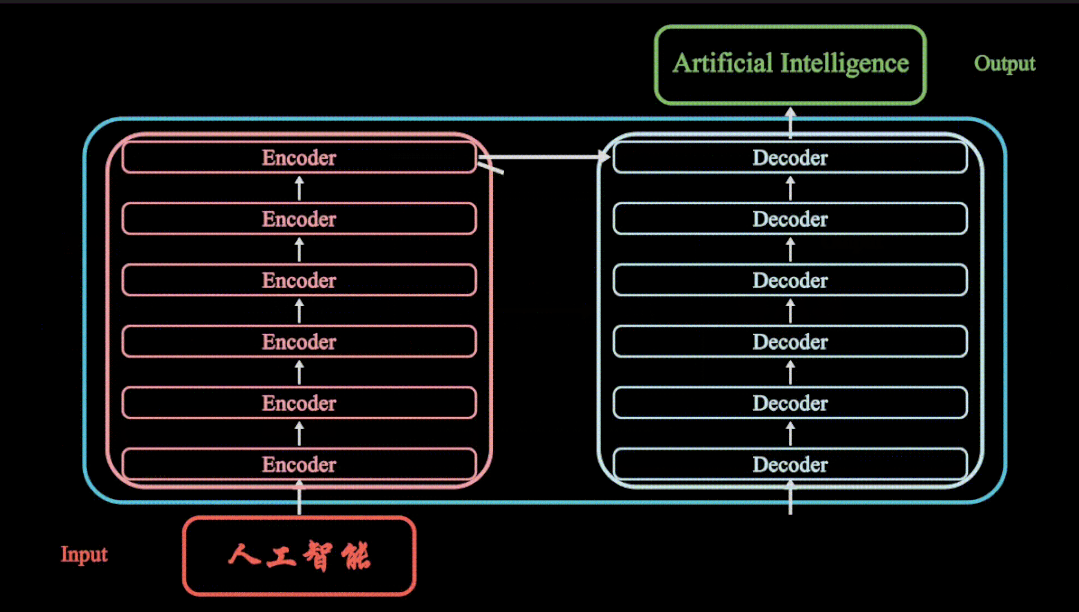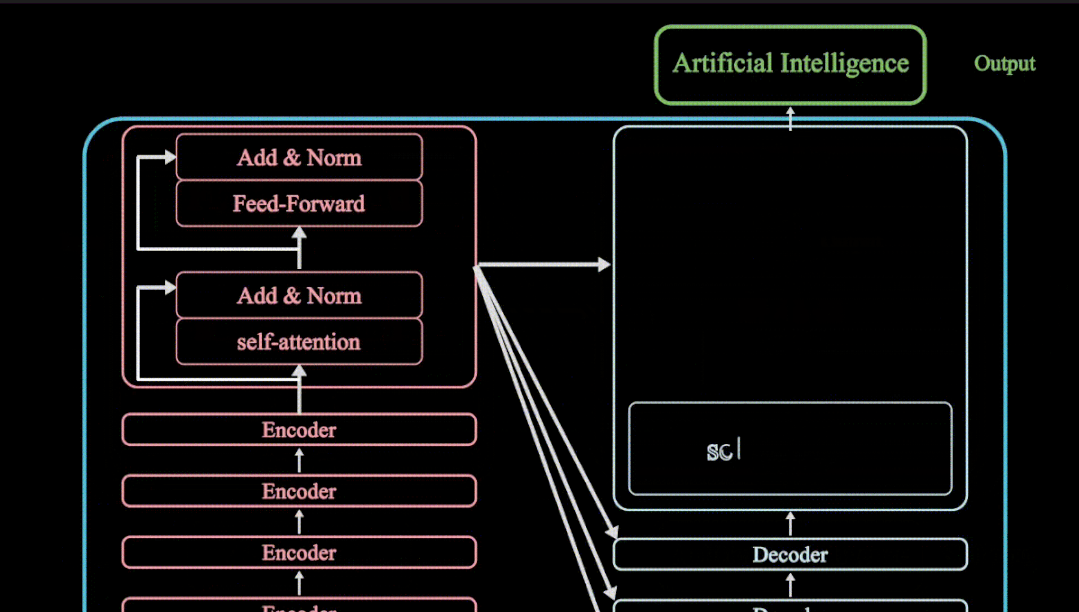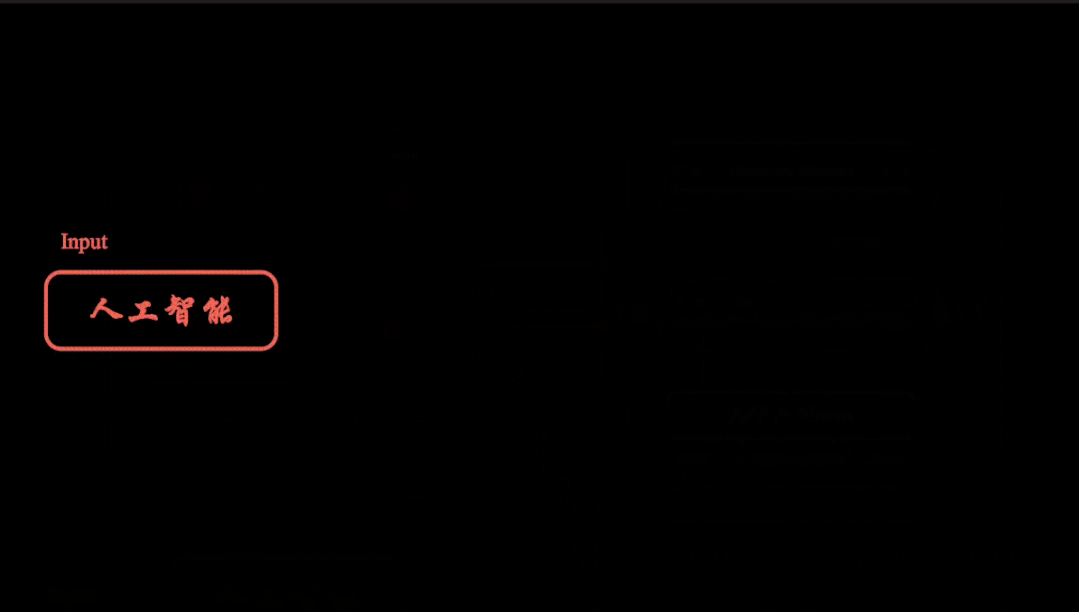
transformer模型框架
虽然很多人对transformer模型并不太熟悉,但是要是提起ChatGPT,Sora文生视频,Google Gemini等大语言模型,也许会有很多人了解。岂不知这些大模型的主干都是由transformer模型框架构成,而transformer模型最核心的便是注意力机制了。
transformer模型框架的注意力机制是一种全局注意力机制,虽然注意力机制被大模型使用。但是考虑到资源分配以及提升计算性能上,很多模型并没有完全使用transformer模型的标准框架,而是进行了一系列魔改。比如GPT系列模型仅仅使用了transformer模型的解码器部分,而VIT视觉模型仅仅使用了transformer模型的编码器部分,同样使用在视觉模型的Swin模型更是为了降低计算复杂度使用了窗口注意力机制。

VIT模型框架
尽管大模型都对transformer模型进行了或多或少的修改,都是为了降低计算复杂度,提高性能。但是其注意力机制的计算逻辑并没有改变,其模型的核心计算单元都是注意力机制的计算。只是在注意力机制的基础上增加了不同的网络设计,不同的逻辑。但是随着模型深度的不断加深,其计算资源也是相当的大,如何改善transformer模型的计算性能的问题一直是大家感兴趣的问题。
MoE混合专家模型
随着 Mixtral 8x7B的推出,一种称为混合专家模型 (Mixed Expert Models,简称 MoEs) 的 Transformer 模型在开源人工智能社区引起了广泛关注。

混合专家模型
MoE混合专家模型是一种基于 Transformer 架构的模型,混合专家模型主要由两个关键部分组成:
稀疏 MoE 层: 这些层代替了传统 Transformer 模型中的前馈网络 (FFN) 层。MoE 层包含若干“专家”(例如 8 个),每个专家本身是一个独立的神经网络。在实际应用中,这些专家通常是前馈网络 (FFN),但它们也可以是更复杂的网络结构,甚至可以是 MoE 层本身,从而形成层级式的 MoE 结构。

混合专家模型
门控网络或路由: 这个部分用于决定哪些token 被发送到哪个专家。例如,在下图中,“More”这个令牌可能被发送到第二个专家,而“Parameters”这个令牌被发送到第一个专家。有时,一个令牌甚至可以被发送到多个专家。

混合专家模型门控网络
据统计,transformer模型中最浪费计算资源的并不是注意力机制层,而是前馈神经网络。因此混合专家模型便取代了前馈神经网络层。在混合专家模型 (MoE) 中,将传统 Transformer 模型中的每个前馈神经网络 (FFN) 层替换为 MoE 层,其中 MoE 层由两个核心部分组成: 一个门控网络和若干数量的专家。因此就大大降低了计算复杂度的问题。而Google更新的transformer模型框架也是基于MoE框架进行了扩展,称之为MoD模型。
Mixture-of-Depths:动态分配Transformer模型中的计算资源
Google发布的文章称之为MoD模型,其实质也是一种transformer模型,但是提出了动态分配计算资源的问题,大大提升了50%的计算性能。传统的基于 Transformer 的语言模型在输入序列中均匀地分配 FLOPs(浮点运算次数)。MoD模型证明了 Transformer 可以学习动态地将 FLOPs分配到序列中的特定位置,并在模型的不同层级中优化序列的分配。MoD方法通过限制在给定层中可以参与自注意力和 MLP 计算的 token 数量来强制执行总计算预算。

Mixture-of-Depths Transformer
与混合专家 (MoE) Transformer 一样,MoD使用路由器在潜在的计算路径中进行选择。但与 MoE Transformer 不同的是,由于一些 token 采用了第二种路径,因此与 vanilla 或 MoE Transformer 相比,混合深度 (MoD) Transformer 具有更小的总 FLOP计算。
MoD考虑了两种学习路由方案:token 选择和专家选择。在 token 选择路由中,路由器在计算路径上(例如,在 MoE Transformer 中的专家身份之间)生成每个 token 的概率分布。然后将 token 转移到它们喜欢的路径(即概率最高的路径),并且辅助损失确保所有 token 不会收敛到相同的路径。token 选择路由可能会出现负载平衡问题,因为不能保证 token 在可能的路径之间适当地分配自己。“专家选择路由”颠覆了这个过程:不是让 token 选择它们喜欢的路径,而是每条路径根据 token 的偏好选择前 k 个 token。这确保了完美的负载平衡,因为 k 个 token 被保证被转移到每条路径。

MoD学习路由方案
除了 vanilla Transformer 之外,MoD 技术还可以与 MoE 模型集成(共同构成 MoDE 模型)。而论文也是尝试了两种变体:在分阶段 MoDE 中,在自注意力步骤之前添加路由,这样能够允许token跳过注意力机制层,提高计算效率。
而在集成 MoDE 中,通过在常规 MLP 专家中集成 MoD 路由。大大简化了路由机制,也可以有效的提高计算性能。但是模型需要学习如何有效地进行路由选择,才能保证计算资源的合理分配和模型的性能。

Mixture-of-Depths-and-Experts (MoDE)
MoD 的核心思想:
- 设置静态计算预算: 通过限制参与每个 block(自注意力层和前馈网络层)计算的 token 数量来控制总计算量。
- 路由机制: 使用路由器为每个 token 生成一个权重,表示该 token 参与 block 计算的优先级。
- Top-k 选择: 选择权重最高的 k 个 token 参与 block 计算,保证计算图和张量大小保持静态。
MoD 的优势:
- 提高计算效率: 相比于传统 Transformer 模型,MoD 模型在每个前向传递中使用更少的计算量,从而提高了训练和推理速度。
- 保持或提升性能: 实验结果表明,在相同的计算预算下,MoD 模型可以达到与传统 Transformer 模型相当甚至更好的性能。
- 灵活的资源分配: MoD 模型可以根据上下文动态地将计算资源分配给更需要处理的 token,从而更好地理解输入序列。

attention is all you need原论文框图
目前来看,大模型依然是transformer模型的天下,其注意力机制仅仅有3个矩阵构成,其公式也是比较简单。就是这么简单的计算公式,却是如今大模型必不可缺的模型框架,GPT系列,Gemini系列,mistral AI系列,Claude 系列,trok Xai系列以及国内的大模型都离不开注意力机制的计算。可想transformer模型是如此的强大,而目前绝大模型的做法也是MoE混合模型,据说GPT4模型便是一个MoE混合模型。无论哪个模型,都是使用了transformer模型的注意力机制。
https://huggingface.co/blog/
https://arxiv.org/abs/2404.02258 Mixture-of-Depths: Dynamically allocating compute in transformer-based language models更多transformer,VIT,swin tranformer
参考头条号:人工智能研究所
v号:启示AI科技
微信中复制如下链接,打开,免费使用chatgpthttps://wx2.expostar.cn/qz/pages/manor/index?id=1137&share_from_id=79482&sid=24
动画详解transformer 教程在线
这篇关于7年来Google首次更新transformer框架,性能提升50%的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







