本文主要是介绍IPv4报头格式分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
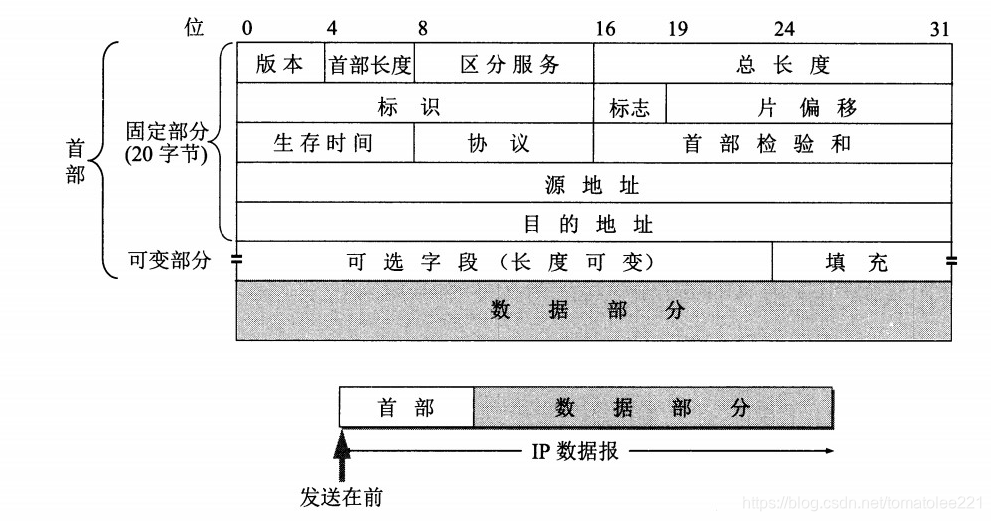
IPv4报头
抓包抓取到的ipv4详细信息:
下面详细描述ipv4报头中各个字段的含义:
·Version(版本): 该字段长度为4比特位。标识IP报头的版本和格式,ipv4数据包的该字段设置为:0100

·IHL( Internet报头长度): 该字段长度为4比特位。它标识报头的总长度,以32比特位为一个单位,在ipv4中头部被限制为最多15个32位字。有效报头的最小值为5。即0101
·Type of Service(服务类型): 该字段长度为8比特位。被分为俩个部分,前6位被称为区分服务字段—DS字段;后2位是显示拥塞通知字段—ECN字段,用于QS。
·Total Length(总长度): 该字段长度为16比特位。它标识数据报和数据包的总长度,单位为字节。所以ipv4的数据最大为65535。
·Identification(标识符): 该字段长度为16比特位。它标识分段所属的组,所属为同一组则标识符相同。在网络层中也可把流量区分开来,用于流量分片。
·Flags(标记位): 该字段长度为3比特位。它分为三分部分,保留位(reserved bit)为0;分片位(Don`t fragent)当为1时标识未分片,0则标识被分片;更多位(more fragments)为0标识最后分段,为1标识更多分段。
·Fragment Offset(分段偏移): 该字段长度为13位比特位。用来重排序,它标识分段在当前数据包的位置,单位为字节。
·Time to Live(存活时间): 该字段长度为8比特位。在网络中标识数据包最大存活时间,用来防止路由环路,每经过一台路由器则TTL字段减去1,直到为0,此数据包直接被丢弃。其值最大为255,单位为s。然而现在路由器转发数据包都是用跳数来作为衡量单位。
·Protocol(协议): 该字段长度为8比特位。它用来标识上层协议(0—255),上图为6标识为TCP协议号。
·Header Checksum(报头校验和): 该字段长度为16比特位。 这个16位字段只对首部查错,不包括数据部分。在每一跳,路由器都要重新计算出的首部检验和并与此字段进行比对,如果不一致,此报文将会被丢弃。重新计算的必要性是因为每一跳的一些首部字段(如TTL、Flag、Offset等)都有可能发生变化,不检查数据部分是为了减少工作量。数据区的错误留待上层协议处理——(UDP)和(TCP)都有检验和字段。此处的检验计算方法不使用CRC。
·Source address(源地址): 该字段长度为32比特位。它标识发送者的ip地址。
·Destination address(目的地址): 该字段长度为32比特位。它标识接受者的ip地址。
·options(ip选项): 该字段长度可变。该字段提供某些控制功能,但在大部分情况下不需要这些功能。里面包括机制有松散路由,严格路由,路由记录及时间戳。
·padding(填充): 通过options字段后面补充0来补齐32位比特位,padding的和位0或者是32的倍数。
这篇关于IPv4报头格式分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






