本文主要是介绍(CDA数据分析师学习笔记)第五章多维数据透视分析二,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- 主表提供数据范围,在一对多的对应关系下,使用单项筛选器进行汇总计算时,应遵循:“一表出维度字段是附表,多表出度量字段是主表,一表筛选多表”。
一对一:应当是逻辑上的一对一,而非当前数据是一对一。
多对多: 尽量避免。可能出现度量值重复计算的可能。
- 一对多(多对一):如果是单项筛选器,当一表筛选多表、一表出维度、多表出度量才能得到正确的结果。双向筛选器时,应尽量一表筛选多表,此时是类型一规则,先将维度字段下相同的维度项按照合并同类项的方式合并到一起,在按照计算规则将不同维度项下对应的所有度量值进行汇总计算,最后得到计算结果。
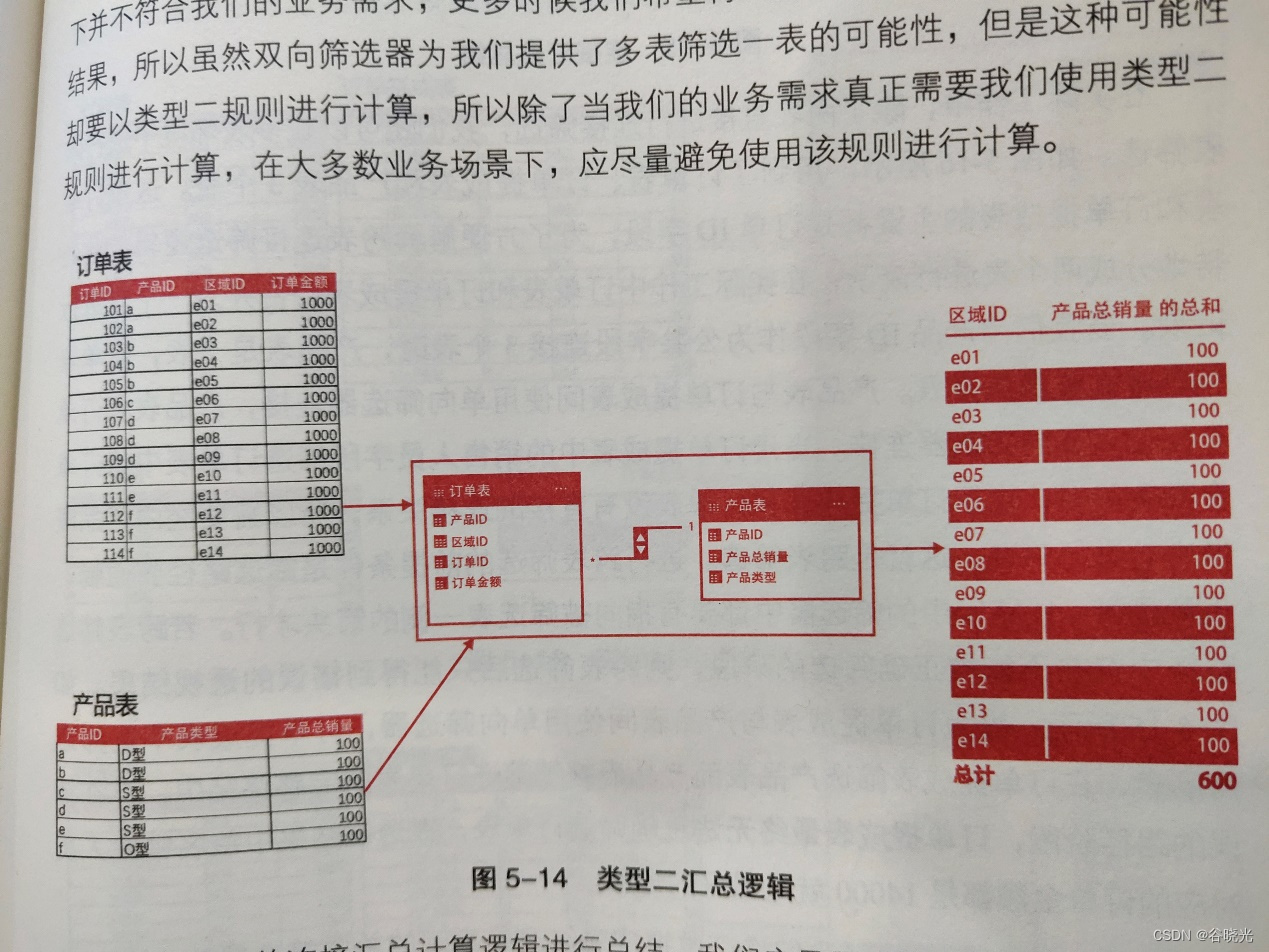
当多表筛选一表时,此时是类型二规则,先对维度字段下不同维度项进行合并同类项处理,再找出每个维度项下包含的公共字段,然后将每个不同公共字段作为汇总度量字段的维度使用,再按照指定的汇总规则去计算每个不同公共字段信息对应的度量值。类型二规则下,指定的维度字段不直接对度量字段进行筛选,而是找出不同维度下包含的不同公共字段,用这些公共字段对度量值字段进行筛选。
类型二:举例子
区域id是维度字段,产品总销量是度量。据图可知产品id是每个维度下的公共字段。
计算过程:先将每个区域id项包含的不同产品id找到,作为维度,将每一个产品id下对应的度量字段(产品总销量)加总得出最终结果。
总结:尽量使用一对多,且“一表出维度,多表出度量,一表筛选多表”。

- 跨表筛选:前提是路径通畅,无论各个表间对应关系如何,都将按照类型二规则进行汇总。

图中5-16无法正常完成筛选,每个销售人员的订单金额都是14000。
- 在多表环境下,不相邻的两个表间往往可以形成多条不同的筛选路径,两表间包含多条筛选路径的情况称为交叉连接。但是真正影响筛选结果的往往只有一条,称为有效路径,其他不参与筛选的路径称为无效路径。在powerBI工具中有效路径用实线表示,无效路径用虚线表示。
- 出维度字段的是维度表,出度量字段的是事实表,维度字段筛选度量字段,维度表筛选事实表。多表连接环境下,维度表与事实表可以构成3种不同的连接模型,分别是星型、雪花型、星座型。
星型模型:一个事实表与多个维度表连接。
雪花模型:维度表与其他维度表连接再与事实表连接后构成的连接模型。
星座模型:多个事实表与某些维度表连接后构成的连接模型。
这篇关于(CDA数据分析师学习笔记)第五章多维数据透视分析二的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






