本文主要是介绍带头节点单向非循环链表的基本操作(c语言实现),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
头节点
头节点是数据结构中的一个概念,特别是在链表结构中。
它通常被设置为链表的第一个节点之前的一个节点,其数据域一般不存储链表中的实际数据,而它的指针域则存储指向链表中第一个实际节点的指针。
头节点的主要作用如下:
- 使得对链表的操作更加统一和方便,特别是在链表为空或者需要在链表头部进行插入、删除操作时,头节点的存在可以避免一些特殊情况的处理,从而简化代码并减少出错的可能性。
- 当链表为空时,头指针会指向头节点,从而避免头指针为空的情况,这在某种程度上增强了链表结构的健壮性。
需要注意的是,头节点并不是链表所必需的,它主要是为了操作方便而引入的。而头指针则是链表所必需的,它总是指向链表的第一个节点(无论是否存在头节点)
带头节点单向不循环链表
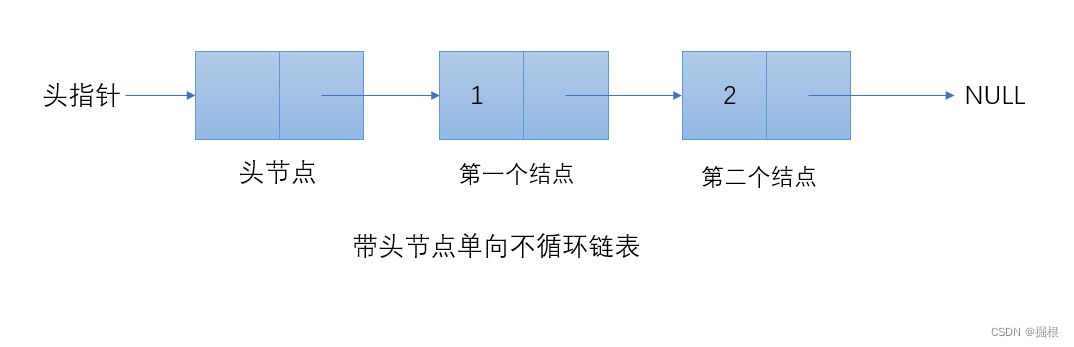
我们也是借用结构体来表示一个单链表的定义
typedef int SLTDatatype;typedef struct SListNode
{
SLTDataType data;
struct SListNode*next;
}SLTNode;SLTNode是“Singly Linked List Node”的缩写,它表示单链表中的结点。
在“SLTNode”这个缩写中,中间的“T”通常代表“Type”或者“Node”的缩写。在这里,“T”更是为了强调这是一个特定的类型(Type)或者是一个结点(Node)的表示。
链表的基本操作
带头节点单向不循环链表的基本操作包括:
- 创建链表:首先需要定义一个链表结构体,其中每个结点包含一个数据域和一个指向下一个结点的指针。然后,通过动态内存分配(如使用malloc函数)来创建链表的各个结点,并将它们按照顺序连接起来。头结点作为链表的起始点,其指针域指向第一个实际的数据结点。
- 清空链表:遍历链表,逐个释放每个结点的内存空间,直到链表为空。注意,需要确保正确处理头结点,避免内存泄漏。
- 销毁链表:在清空链表后,还需要释放头结点的内存空间,以完全销毁整个链表。
- 头插法:在链表的头部插入新结点。具体操作为:创建一个新结点,将其数据域设置为要插入的数据,然后将其指针域指向头结点的下一个结点,最后更新头结点的指针域,使其指向新结点。
- 尾插法:在链表的尾部插入新结点。这需要遍历链表找到最后一个结点,然后创建一个新结点,将其数据域设置为要插入的数据,并将最后一个结点的指针域指向新结点。
- 任意位置插入法:在链表的任意位置插入新结点。首先找到要插入位置的前一个结点,然后创建一个新结点,将其数据域设置为要插入的数据,并将其指针域指向要插入位置的原结点,最后更新前一个结点的指针域,使其指向新结点。
- 头删法:删除链表的头部结点。具体操作为:将头结点的下一个结点作为新的头结点,然后释放原头结点的内存空间。
- 尾删法:删除链表的尾部结点。这需要遍历链表找到倒数第二个结点,然后将其指针域设置为NULL,并释放原尾部结点的内存空间。
- 任意位置删除法:删除链表的任意位置结点。首先找到要删除结点的前一个结点,然后更新前一个结点的指针域,使其跳过要删除的结点,并指向要删除结点的下一个结点,最后释放要删除结点的内存空间。
- 查询链表中是否有想要的数据:遍历链表,逐个比较结点的数据域与要查询的数据是否相等,若相等则返回该结点的位置或数据,否则继续遍历直到链表结束。
这些基本操作构成了带头节点单向不循环链表的基本功能,可以根据具体需求进行组合和扩展。需要注意的是,在实际编程中,还需要考虑错误处理、边界条件以及内存管理的安全性等问题。
一,链表的初始化
带头节点单向非循环链表和不带头节点单向非循环链表的初始化操作不同,带头节点的需要先搞出头节点来,而另外一个不用
void SLTInit(SLTNode** pphead)
{*pphead = (SLTNode*)malloc(sizeof(SLTNode));//创建头节点if (*pphead == NULL){perror("malloc fail");return;}(*pphead)->next = NULL;//头结点的next置空(*pphead) -> data = 0;//仅仅是为了防止潜在的错误而设定的
}经过这个操作我们得注意一个点:*pphead代表的是头节点,而不是第一个元素。
第一个元素是(*pphead)->next
二,创建新结点
SLTNode* BuySLTNode(SLTDataType x)
{SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));//分配内存if (newnode == NULL)//如果内存分配失败{perror("malloc fail");return NULL;}
//给新结点赋值newnode->data = x;newnode->next = NULL;return newnode;
}三,指定结点的后插操作
//通常情况下,我们是按照*pos是头节点的标准来设计这个操作的
//在指定结点pos后面添加一个元素
// 在指定结点pos后面添加一个元素
void SLTInsertAfter(SLTNode* pos, SLTDataType x) { assert(pos != NULL && pos->next != NULL); // 确保pos不为空且pos不是链表的最后一个节点 SLTNode* newnode = BuySLTNode(x); newnode->next = pos->next; pos->next = newnode;
}四,指定结点的前插操作
// 在指定结点pos前添加一个元素
void SLTInsertFront(SLTNode** pphead, SLTNode* pos, SLTDataType x) {assert(pphead != NULL && *pphead != NULL && pos != NULL);if (*pphead == pos) {perror("头节点不能前插\n");exit(-1);}SLTNode* cur = *pphead;while (cur->next != pos) {if (cur->next == NULL) {perror("目标结点pos不在链表中\n");exit(-1);}cur = cur->next;}SLTNode* newnode = BuySLTNode(x);newnode->next = pos;cur->next = newnode;
}五,在链表头部插入新结点
// 在链表头部插入新结点
void ListInsertFront(SLTNode** pphead, SLTDataType data) {assert(pphead != NULL && *pphead != NULL);SLTNode* newnode = BuySLTNode(data);newnode->next = (*pphead)->next;(*pphead)->next = newnode;
}六,在链表尾部插入新结点
// 在链表尾部插入新结点
void InsertRear(SLTNode** pphead, SLTDataType data) {assert(pphead != NULL && *pphead != NULL);SLTNode* newnode = BuySLTNode(data);SLTNode* tail = *pphead;while (tail->next) {tail = tail->next;}tail->next = newnode;
}七,删除链表的第一个结点
// 删除链表的头部结点
void DeleteFront(SLTNode** pphead) {if ((*pphead)->next == NULL) {//我们要注意*pphead是头节点,不是第一个结点printf("List is empty!\n");return;}SLTNode* p = (*pphead)->next;(*pphead)->next = p->next; // 头结点指向原第二个结点 free(p); // 释放原第一个结点内存
}八,删除链表的最后一个结点
// 删除链表的尾部结点
void DeleteRear(SLTNode** pphead) {if ((*pphead)->next == NULL) {printf("List is empty!\n");return;}SLTNode* p = *pphead;SLTNode* q = NULL;while (p->next->next) { // 找到倒数第二个结点 q = p;p = p->next;}//p为倒数第二个//q为倒数第三个q->next = NULL; // 最后一个结点的前一个结点指向NULL free(p->next); // 释放原尾部结点内存
}九,释放链表
// 释放链表内存
void FreeList(SLTNode* head) {SLTNode* cur = head;while (cur) {SLTNode* next = cur->next;free(cur);cur = next;}
}十,打印链表
// 打印链表
void PrintList(SLTNode* head) {SLTNode* cur = head->next;while (cur) {printf("%d ", cur->data);cur = cur->next;}printf("\n");
}完整代码
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
typedef int SLTDataType;typedef struct SListNode
{SLTDataType data;struct SListNode* next;
}SLTNode;// 初始化链表
void SLTInit(SLTNode** pphead) {*pphead = (SLTNode*)malloc(sizeof(SLTNode));if (*pphead == NULL) {perror("malloc fail");exit(EXIT_FAILURE);}(*pphead)->data = 0; // 初始化头结点的data字段 (*pphead)->next = NULL;
}// 创建新结点
SLTNode* BuySLTNode(SLTDataType x) {SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));if (newnode == NULL) {perror("malloc fail");exit(EXIT_FAILURE);}newnode->data = x;newnode->next = NULL;return newnode;
}// 在指定结点pos后面添加一个元素
void SLTInsertAfter(SLTNode* pos, SLTDataType x) {assert(pos != NULL && pos->next != NULL); // 确保pos不为空且pos不是链表的最后一个节点 SLTNode* newnode = BuySLTNode(x);newnode->next = pos->next;pos->next = newnode;
}// 在指定结点pos前添加一个元素
void SLTInsertFront(SLTNode** pphead, SLTNode* pos, SLTDataType x) {assert(pphead != NULL && *pphead != NULL && pos != NULL);if (*pphead == pos) {perror("头节点不能前插\n");exit(-1);}SLTNode* cur = *pphead;while (cur->next != pos) {if (cur->next == NULL) {perror("目标结点pos不在链表中\n");exit(-1);}cur = cur->next;}SLTNode* newnode = BuySLTNode(x);newnode->next = pos;cur->next = newnode;
}// 在链表头部插入新结点
void ListInsertFront(SLTNode** pphead, SLTDataType data) {assert(pphead != NULL && *pphead != NULL);SLTNode* newnode = BuySLTNode(data);newnode->next = (*pphead)->next;(*pphead)->next = newnode;
}// 在链表尾部插入新结点
void InsertRear(SLTNode** pphead, SLTDataType data) {assert(pphead != NULL && *pphead != NULL);SLTNode* newnode = BuySLTNode(data);SLTNode* tail = *pphead;while (tail->next) {tail = tail->next;}tail->next = newnode;
}// 释放链表内存
void FreeList(SLTNode* head) {SLTNode* cur = head;while (cur) {SLTNode* next = cur->next;free(cur);cur = next;}
}// 打印链表
void PrintList(SLTNode* head) {SLTNode* cur = head->next;while (cur) {printf("%d ", cur->data);cur = cur->next;}printf("\n");
}
// 删除链表的头部结点
void DeleteFront(SLTNode** pphead) {if ((*pphead)->next == NULL) {//我们要注意*pphead是头节点,不是第一个结点printf("List is empty!\n");return;}SLTNode* p = (*pphead)->next;(*pphead)->next = p->next; // 头结点指向原第二个结点 free(p); // 释放原第一个结点内存
}// 删除链表的尾部结点
void DeleteRear(SLTNode** pphead) {if ((*pphead)->next == NULL) {printf("List is empty!\n");return;}SLTNode* p = *pphead;SLTNode* q = NULL;while (p->next->next) { // 找到倒数第二个结点 q = p;p = p->next;}//p为倒数第二个//q为倒数第三个q->next = NULL; // 最后一个结点的前一个结点指向NULL free(p->next); // 释放原尾部结点内存
}
// 测试代码
int main() {SLTNode* head = NULL;SLTInit(&head);ListInsertFront(&head, 1);ListInsertFront(&head, 2);InsertRear(&head, 3);SLTInsertAfter(head->next, 4); // 插入到第二个节点后 SLTInsertFront(&head, head->next->next, 5); // 插入到第三个节点前 PrintList(head);FreeList(head);return 0;
}
这篇关于带头节点单向非循环链表的基本操作(c语言实现)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




