本文主要是介绍深度学习学习日记4.14 数据增强 Unet网络部分,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据增强

transforms.Compose([:这表示创建一个转换组合,将多个数据转换操作串联在一起
transforms.RandomHorizontalFlip():这个操作是随机水平翻转图像,以增加数据的多样性。它以一定的概率随机地水平翻转输入的图像。
transforms.Resize(image_size):这个操作用于将图像调整为指定的大小。image_size 是所需的输出图像大小,可以是一个整数或一个 (height, width) 元组。
transforms.CenterCrop(image_size):这个操作用于从图像的中心裁剪出指定大小的区域。同样,image_size 可以是一个整数或一个 (height, width) 元组。
transforms.ToTensor():这个操作将图像转换为 PyTorch 张量格式。它会将 PIL 图像或 ndarray 转换为张量,并对像素值进行归一化到 [0, 1] 的范围内。
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]):这个操作用于对图像进行标准化。它对张量的每个通道进行归一化处理,使得每个通道的均值为 0.485、0.456、0.406,标准差为 0.229、0.224、0.225。
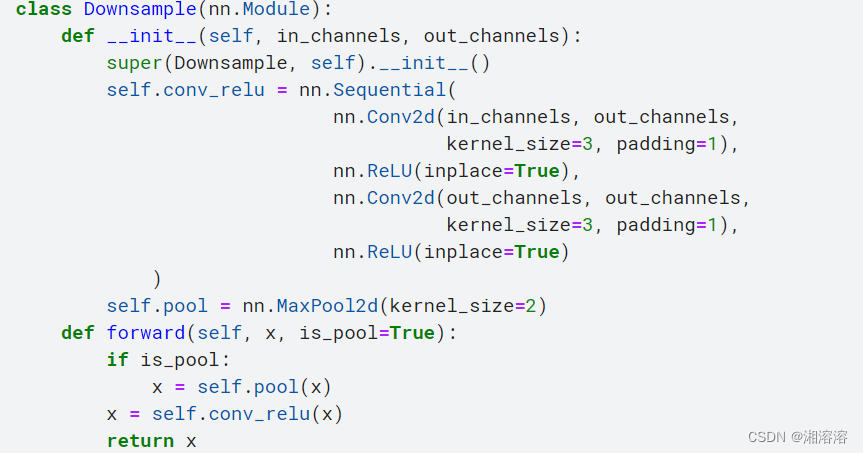
Unet下采样:两层的卷积+relu+maxpooling
1.继承nn.model
2.初始化参数,输入channel,输出channel
nn.sequential序列 中写 卷积,relu(inplce=True节省计算资源),卷积,Relu
最大池化层,缩减为1/2 长宽都减小一般
3.前向传播:需要有参数是否做maxpooling

Unet上采样:卷积、卷积 反卷积 不需要设置outchannel
1.继承nn.model
2.初始化参数,只需要输入通道数
nn.sequential序列中写 卷积(输入是输出的2倍(有contact操作))relu ,卷积,relu
反卷积的nn.sequential 输出通道数减半,保证图片的长宽是原来的2倍和relu函数
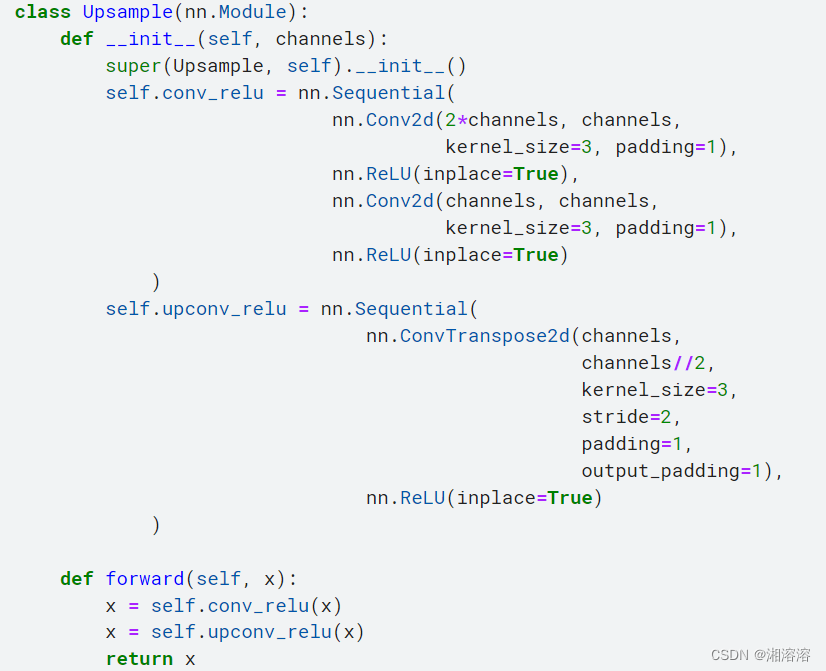
3.前向传播,卷积卷积 ,反卷积
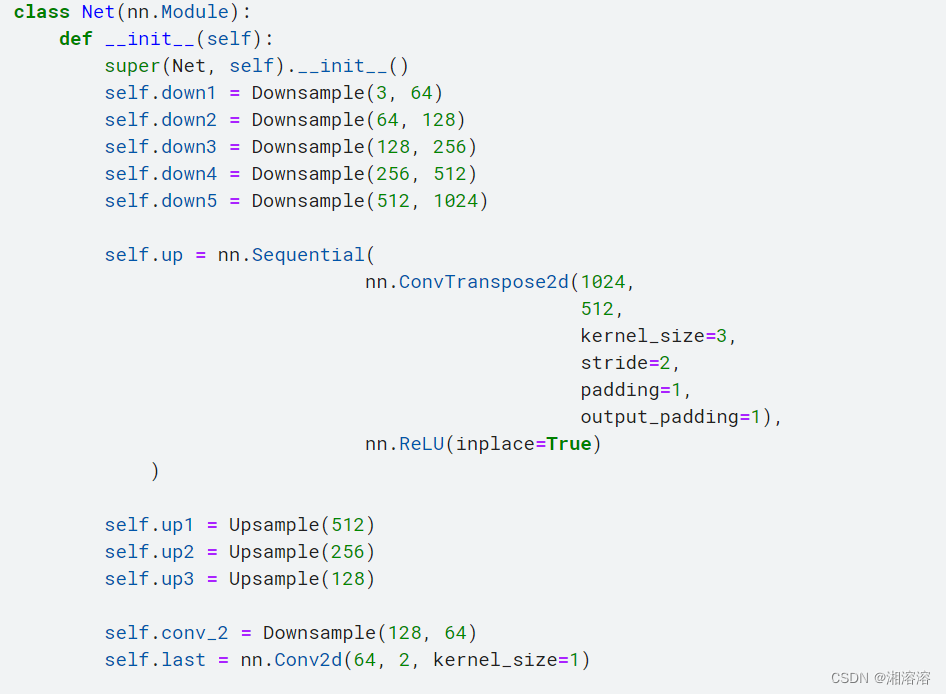
Unet的整体结构:
encoder:先池化后卷积
decoder:卷积卷积反卷积
需要把前面卷积的数据进行融合
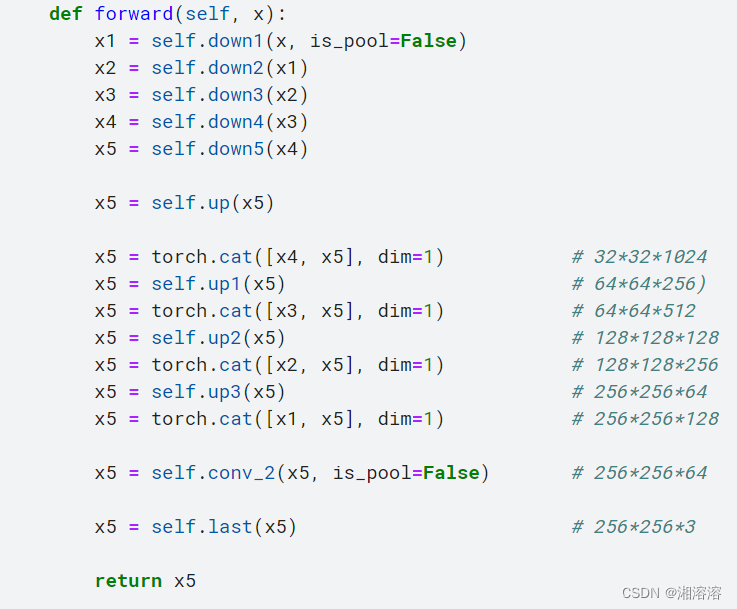
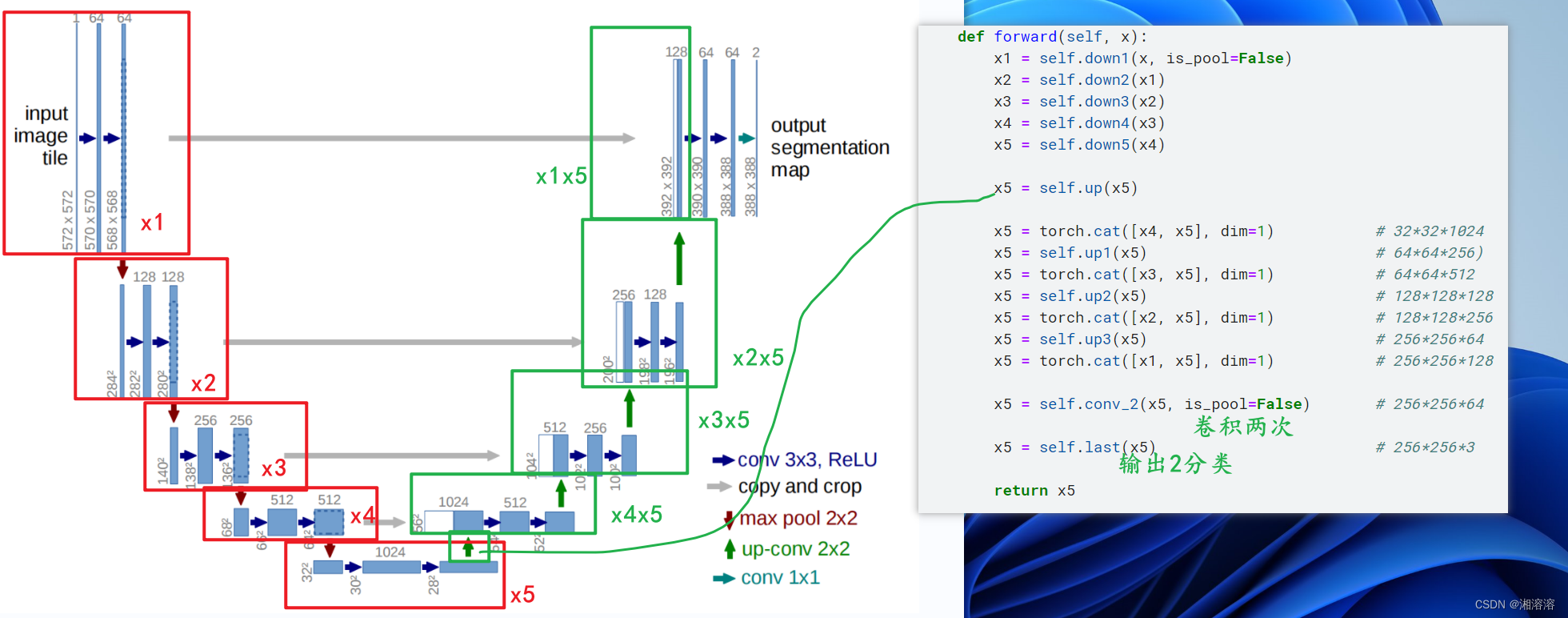
#网络
class Downsample(nn.Module):def __init__(self, in_channels, out_channels):super(Downsample, self).__init__()self.conv_relu = nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),nn.ReLU(inplace=True))self.pool = nn.MaxPool2d(kernel_size=2)def forward(self, x, is_pool=True):if is_pool:x = self.pool(x)x = self.conv_relu(x)return x
class Upsample(nn.Module):def __init__(self, channels):super(Upsample, self).__init__()self.conv_relu = nn.Sequential(nn.Conv2d(2*channels, channels, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(channels, channels, kernel_size=3, padding=1),nn.ReLU(inplace=True))self.upconv_relu = nn.Sequential(nn.ConvTranspose2d(channels, channels//2, kernel_size=3,stride=2,padding=1,output_padding=1),nn.ReLU(inplace=True))def forward(self, x):x = self.conv_relu(x)x = self.upconv_relu(x)return x
class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.down1 = Downsample(3, 64)self.down2 = Downsample(64, 128)self.down3 = Downsample(128, 256)self.down4 = Downsample(256, 512)self.down5 = Downsample(512, 1024)self.up = nn.Sequential(nn.ConvTranspose2d(1024, 512, kernel_size=3,stride=2,padding=1,output_padding=1),nn.ReLU(inplace=True))self.up1 = Upsample(512)self.up2 = Upsample(256)self.up3 = Upsample(128)self.conv_2 = Downsample(128, 64)self.last = nn.Conv2d(64, 2, kernel_size=1)def forward(self, x):x1 = self.down1(x, is_pool=False)x2 = self.down2(x1)x3 = self.down3(x2)x4 = self.down4(x3)x5 = self.down5(x4)x5 = self.up(x5)x5 = torch.cat([x4, x5], dim=1) # 32*32*1024x5 = self.up1(x5) # 64*64*256)x5 = torch.cat([x3, x5], dim=1) # 64*64*512 x5 = self.up2(x5) # 128*128*128x5 = torch.cat([x2, x5], dim=1) # 128*128*256x5 = self.up3(x5) # 256*256*64x5 = torch.cat([x1, x5], dim=1) # 256*256*128x5 = self.conv_2(x5, is_pool=False) # 256*256*64x5 = self.last(x5) # 256*256*3return x5
#测试模型
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model=Net().to(device)
# x = torch.rand([8,3,256,256])
# x=x.to(device)
# y=model(x)
# y.shape
这篇关于深度学习学习日记4.14 数据增强 Unet网络部分的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



