本文主要是介绍【C++庖丁解牛】底层为红黑树结构的关联式容器--哈希容器(unordered_map和unordered_set),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!


目录
- 1. unordered系列关联式容器
- 1.1 unordered_map
- 1.1.1 unordered_map的文档介绍
- 1.1.2 unordered_map的接口说明
- 1.2 unordered_set
- 1.2.1 unordered_set的构造
- 1.2.2 unordered_set的修改操作
- 1.2.3 unordered_set的查找操作
- 1.2.4 unordered_set的容量
- 1.2.5 unordered_set的迭代器
- 1.2.5 unordered_set的其他操作
- 2.set与unordered_set的区别
- 3. 比较set和unordered_set的性能差异
- 1.4.1 set和unordered_set的效率对比
- 4. unordered_map应用OJ题
- 4.1 leecode-961. 在长度 2N 的数组中找出重复 N 次的元素
- 4.2 leecode-349. 两个数组的交集
1. unordered系列关联式容器
在C++98中,STL提供了底层为红黑树结构的一系列关联式容器,在查询时效率可达到 l o g 2 N log_2 N log2N,即最差情况下需要比较红黑树的高度次,当树中的节点非常多时,查询效率也不理想。最好的查询是,进行很少的比较次数就能够将元素找到,因此在C++11中,STL又提供了4个unordered系列的关联式容器,这四个容器与红黑树结构的关联式容器使用方式基本类似,只是其底层结构不同。
nordered系列关联式容器是C++标准库中提供的一组无序容器,用于存储键值对。它们的特点是使用哈希函数来实现快速的查找、插入和删除操作,而不是使用传统的红黑树等数据结构。
unordered系列关联式容器包括以下几种:
- unordered_set:无序集合,存储唯一的键值,不允许重复。
- unordered_multiset:无序多重集合,存储键值,允许重复。
- unordered_map:无序映射,存储键值对,键唯一。
- unordered_multimap:无序多重映射,存储键值对,键可以重复。
这些容器的底层实现使用了哈希表,通过将键值映射到哈希桶中来实现快速的查找和插入操作。在哈希冲突时,采用链地址法解决冲突。
使用unordered系列关联式容器时,需要注意以下几点:
- 需要提供自定义的哈希函数和相等比较函数(或者使用默认的std::hash和std::equal_to)。
- 由于无序容器不会对元素进行排序,因此迭代器遍历元素的顺序是不确定的。
- 插入和查找操作的平均时间复杂度为O(1),但最坏情况下可能达到O(n)。
1.1 unordered_map
1.1.1 unordered_map的文档介绍

- unordered_map是存储<key, value>键值对的关联式容器,其允许通过keys快速的索引到与其对应的value。
- 在unordered_map中,键值通常用于惟一地标识元素,而映射值是一个对象,其内容与此键关联。键和映射值的类型可能不同。
- 在内部,unordered_map没有对<kye, value>按照任何特定的顺序排序, 为了能在常数范围内找到key所对应的value,unordered_map将相同哈希值的键值对放在相同的桶中。
- unordered_map容器通过key访问单个元素要比map快,但它通常在遍历元素子集的范围迭代方面效率较低。
- unordered_maps实现了直接访问操作符(operator[]),它允许使用key作为参数直接访问value。
- 它的迭代器至少是前向迭代器。
1.1.2 unordered_map的接口说明
- unordered_map的构造
| 函数声明 | 功能介绍 |
|---|---|
| unordered_map | 构造不同格式的unordered_map对象 |
- unordered_map的容量
| 函数声明 | 功能介绍 |
|---|---|
| bool empty() const | 检测unordered_map是否为空 |
| size_t size() const | 获取unordered_map的有效元素个数 |
- unordered_map的迭代器
| 函数声明 | 功能介绍 |
|---|---|
| begin | 返回unordered_map第一个元素的迭代器 |
| end | 返回unordered_map最后一个元素下一个位置的迭代器 |
| cbegin | 返回unordered_map第一个元素的const迭代器 |
| cend | 返回unordered_map最后一个元素下一个位置的const迭代器 |
- unordered_map的元素访问
| 函数声明 | 功能介绍 |
|---|---|
| operator[] | 返回与key对应的value,没有一个默认值 |
注意:该函数中实际调用哈希桶的插入操作,用参数key与V()构造一个默认值往底层哈希桶
中插入,如果key不在哈希桶中,插入成功,返回V(),插入失败,说明key已经在哈希桶中,
将key对应的value返回。
- unordered_map的查询
| 函数声明 | 功能介绍 |
|---|---|
| iterator find(const K& key) | 返回key在哈希桶中的位置 |
| size_t count(const K& key) | 返回哈希桶中关键码为key的键值对的个数 |
注意:unordered_map中key是不能重复的,因此count函数的返回值最大为1
- unordered_map的修改操作
| 函数声明 | 功能介绍 |
|---|---|
| insert | 向容器中插入键值对 |
| erase | 删除容器中的键值对 |
| void clear() | 清空容器中有效元素个数 |
| void swap(unordered_map&) | 交换两个容器中的元素 |
- unordered_map的桶操作
| 函数声明 | 功能介绍 |
|---|---|
| size_t bucket_count()const | 返回哈希桶中桶的总个数 |
| size_t bucket_size(size_t n)const | 返回n号桶中有效元素的总个数 |
| size_t bucket(const K& key) | 返回元素key所在的桶号 |
1.2 unordered_set
1.2.1 unordered_set的构造
| 函数声明 | 功能介绍 |
|---|---|
| 默认构造函数:unordered_set< T > set; | 创建一个空的unordered_set对象,其中T是元素的类型。 |
| 区间构造函数:unordered_set< T > set(first, last); | 创建一个unordered_set对象,并将[first, last)区间内的元素插入到集合中。 |
| 拷贝构造函数:unordered_set< T > set(other_set); | 创建一个unordered_set对象,并将另一个unordered_set对象other_set中的元素拷贝到新的集合中。 |
| 移动构造函数:unordered_set< T > set(std::move(other_set)); | 创建一个unordered_set对象,并从另一个unordered_set对象other_set中移动元素到新的集合中。 |
| 初始化列表构造函数:unordered_set< T > set = {val1, val2, …}; | 创建一个unordered_set对象,并将初始化列表中的元素插入到集合中。 |
1.2.2 unordered_set的修改操作
| 函数声明 | 功能介绍 |
|---|---|
| insert(val) | 将元素val插入到unordered_set中。 |
| insert(first, last) | 将[first, last)范围内的元素插入到unordered_set中。 |
| erase(val) | 删除unordered_set中值为val的元素。 |
| erase(iterator) | 删除迭代器指向的元素。 |
| erase(first, last) | 删除[first, last)范围内的元素。 |
1.2.3 unordered_set的查找操作
| 函数声明 | 功能介绍 |
|---|---|
| find(val) | 返回指向值为val的元素的迭代器,如果不存在则返回end()。 |
| count(val) | 返回值为val的元素在unordered_set中出现的次数,要么是0,要么是1。 |
1.2.4 unordered_set的容量
| 函数声明 | 功能介绍 |
|---|---|
| size() | 返回unordered_set中元素的个数。 |
| empty() | 判断unordered_set是否为空。 |
1.2.5 unordered_set的迭代器
| 函数声明 | 功能介绍 |
|---|---|
| begin() | 返回指向unordered_set第一个元素的迭代器。 |
| end() | 返回指向unordered_set末尾的迭代器。 |
1.2.5 unordered_set的其他操作
| 函数声明 | 功能介绍 |
|---|---|
| clear() | 清空unordered_set中的所有元素。 |
| swap(other) | 交换当前unordered_set和另一个unordered_set的内容。 |
2.set与unordered_set的区别
#include<iostream>
#include<unordered_map>
#include<map>
#include<unordered_set>
#include<set>
using namespace std;void test_set1()
{set<int> s;s.insert(3);s.insert(1);s.insert(5);s.insert(7);for (auto e : s){cout << e << " ";}cout << endl;unordered_set<int> us;us.insert(3);us.insert(1);us.insert(5);us.insert(7);for (auto e : us){cout << e << " ";}cout << endl;
}int main()
{test_set1();return 0;
}
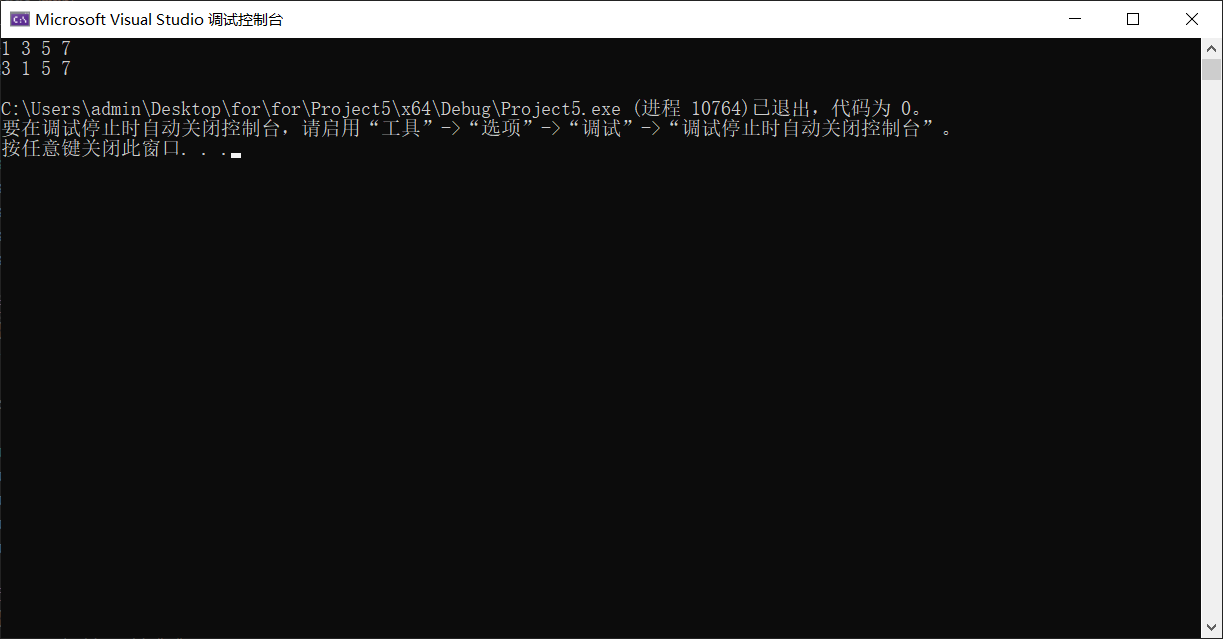
map是有序的,unordered_set是无序的
3. 比较set和unordered_set的性能差异
#include<iostream>
#include<unordered_map>
#include<map>
#include<unordered_set>
#include<set>
using namespace std;
int main()
{const size_t N = 100000;unordered_set<int> us;set<int> s;vector<int> v;v.reserve(N);srand(time(0));for (size_t i = 0; i < N; ++i){v.push_back(rand()); // N比较大时,重复值比较多 因为rand函数产生不重复的值最大上限只有30000多个,我们这里有十万个数据v.push_back(rand()+i); // 重复值相对少v.push_back(i); // 没有重复,有序}size_t begin1 = clock();for (auto e : v){s.insert(e);}size_t end1 = clock();cout << "set insert:" << end1 - begin1 << endl;size_t begin2 = clock();for (auto e : v){us.insert(e);}size_t end2 = clock();cout << "unordered_set insert:" << end2 - begin2 << endl;size_t begin3 = clock();for (auto e : v){s.find(e);}size_t end3 = clock();cout << "set find:" << end3 - begin3 << endl;size_t begin4 = clock();for (auto e : v){us.find(e);}size_t end4 = clock();cout << "unordered_set find:" << end4 - begin4 << endl << endl;cout <<"插入数据个数:"<< s.size() << endl;cout <<"插入数据个数:" << us.size() << endl << endl;size_t begin5 = clock();for (auto e : v){s.erase(e);}size_t end5 = clock();cout << "set erase:" << end5 - begin5 << endl;size_t begin6 = clock();for (auto e : v){us.erase(e);}size_t end6 = clock();cout << "unordered_set erase:" << end6 - begin6 << endl << endl;return 0;
}
1.4.1 set和unordered_set的效率对比
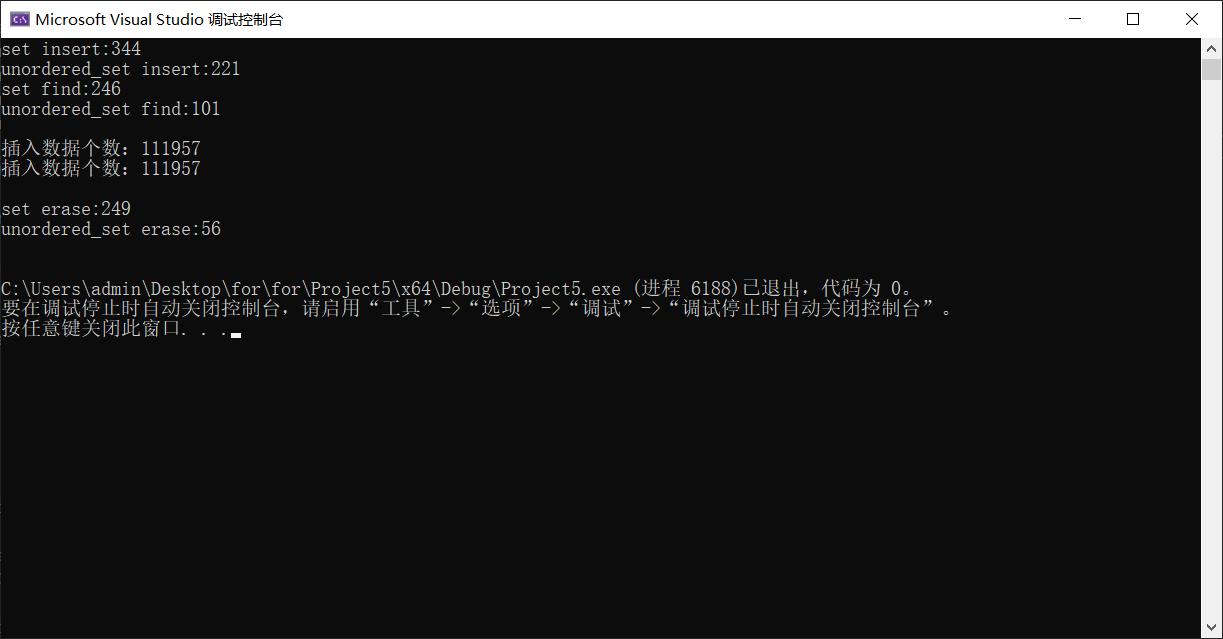
- Release版本(十万个数据)
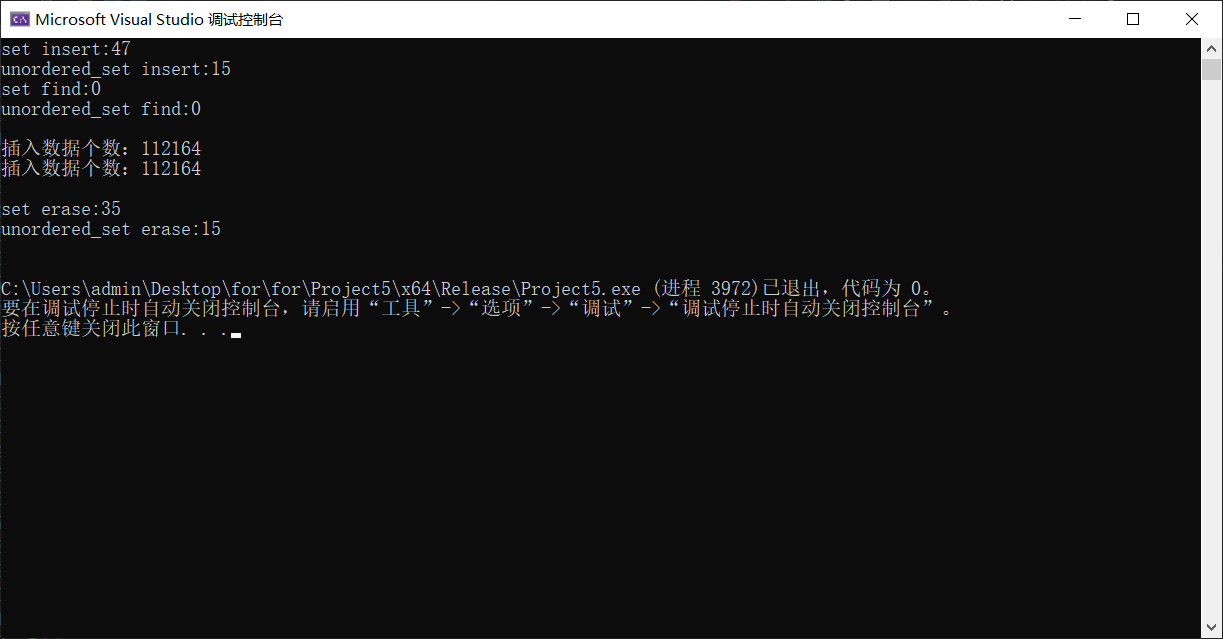
- Debug版本(十万个数据)
- Release版本(一百万个数据)
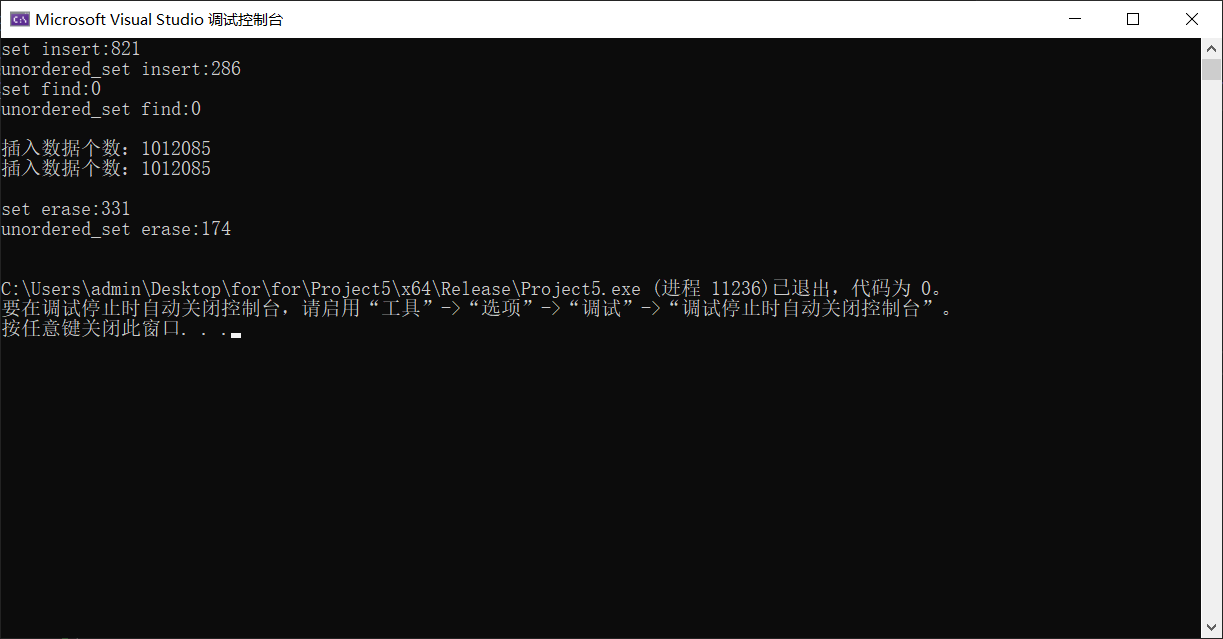
- Debug版本(一百万个数据)
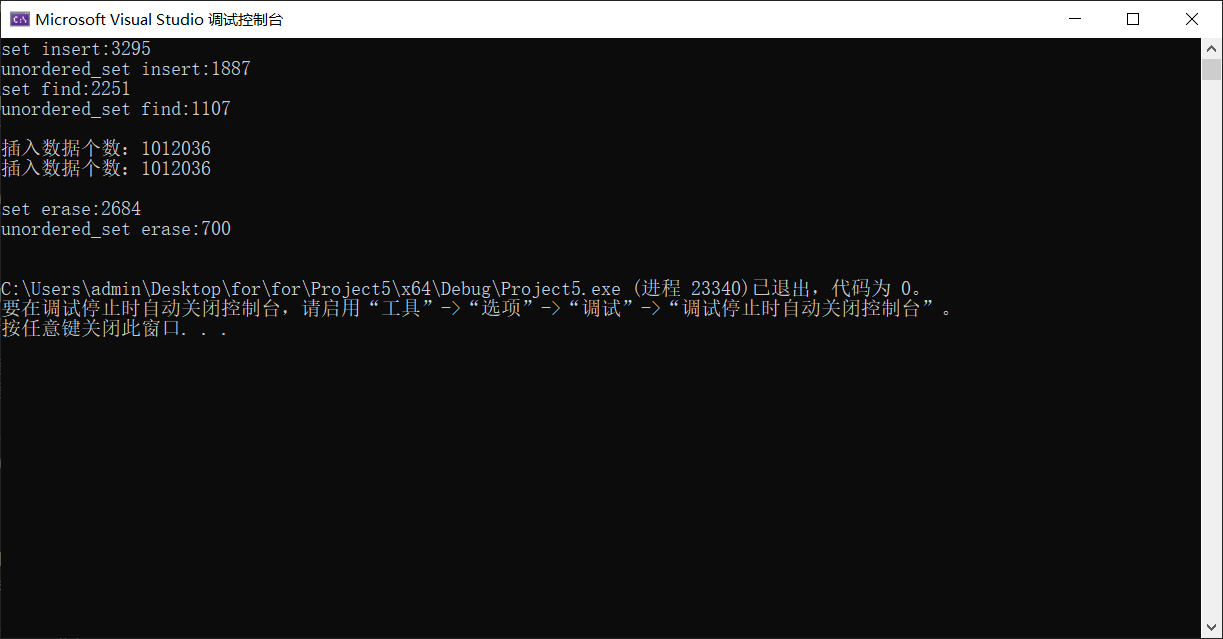
- 插入性能均是unordered_set更优,时间耗费更少
- 查找性能Release无区别,Debug版本是unordered_set更优,时间耗费更少
- 删除性能均是unordered_set更优,时间耗费更少
4. unordered_map应用OJ题
4.1 leecode-961. 在长度 2N 的数组中找出重复 N 次的元素
给你一个整数数组 nums ,该数组具有以下属性:
nums.length == 2 * n.
nums 包含 n + 1 个 不同的 元素
nums 中恰有一个元素重复 n 次
找出并返回重复了 n 次的那个元素。
示例 1:
输入:nums = [1,2,3,3]
输出:3
示例 2:
输入:nums = [2,1,2,5,3,2]
输出:2
示例 3:
输入:nums = [5,1,5,2,5,3,5,4]
输出:5
提示:
2 <= n <= 5000
nums.length == 2 * n
0 <= nums[i] <= 104
nums 由 n + 1 个 不同的 元素组成,且其中一个元素恰好重复 n 次
解题代码:
class Solution {
public:int repeatedNTimes(vector<int>& A) {size_t N = A.size() / 2;// 用unordered_map统计每个元素出现的次数unordered_map<int, int> m;for (auto e : A)m[e]++;// 找出出现次数为N的元素for (auto& e : m){if (e.second == N)return e.first;}//不可能的情况return -1;}
};
4.2 leecode-349. 两个数组的交集
给定两个数组 nums1 和 nums2 ,返回 它们的 交集 。输出结果中的每个元素一定是 唯一 的。我们可以 不考虑输出结果的顺序 。
示例 1:
输入:nums1 = [1,2,2,1], nums2 = [2,2]
输出:[2]
示例 2:
输入:nums1 = [4,9,5], nums2 = [9,4,9,8,4]
输出:[9,4]
解释:[4,9] 也是可通过的
提示:
1 <= nums1.length, nums2.length <= 1000
0 <= nums1[i], nums2[i] <= 1000
解题代码:
class Solution {
public:vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {// 用unordered_set对nums1中的元素去重unordered_set<int> s1;for (auto e : nums1)s1.insert(e);// 用unordered_set对nums2中的元素去重unordered_set<int> s2;for (auto e : nums2)s2.insert(e);// 遍历s1,如果s1中某个元素在s2中出现过,即为交集vector<int> vRet;for (auto e : s1){if (s2.find(e) != s2.end())vRet.push_back(e);}return vRet;}
};
这篇关于【C++庖丁解牛】底层为红黑树结构的关联式容器--哈希容器(unordered_map和unordered_set)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







