本文主要是介绍R数据分析:如何做数据的非线性关系,多项式回归的做法和解释,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
线性关系其实是最常见也是最有效,同时还是最好解释的,不过变量间复杂的关系我们用多项式回归做出来可能会更加的准确。刚好有位粉丝的数据需要用到多项式回归,今天就给大家写写。
要理解非线性关系,首先我们看看线性关系,假设情况如下:商品的价格为p,销售量为q,总价为y,那么qy之间就是线性关系:
p <- 0.5
q <- seq(0,100,1)
y <- p*q
plot(q,y,type='l',col='red',main='线性关系')
但是考虑现实中的情况:一个商品本来价格p是0.5,买的人多了价格会上涨,此时线性关系不成了哦:
y <- 450 + p*(q-10)^3
plot(q,y,type='l',col='navy',main='Nonlinear relationship',lwd=3)
如果你得数据确实不是线性关系,就得考虑数据转化或者拟合多项式回归。
数据模拟
为了更好地给大家演示,我们需要模拟一个数据集出来:
q <- seq(from=0, to=20, by=0.1)
y <- 500 + 0.4 * (q-10)^3
noise <- rnorm(length(q), mean=10, sd=80)
noisy.y <- y + noise上面的代码首先模拟200个销售量,和相应的总价y,同时还给y加了一点点噪声。
我们把模拟数据画出来瞅瞅:
plot(q,noisy.y,col='deepskyblue4',xlab='q',main='Observed data')
lines(q,y,col='firebrick1',lwd=3)
注意我们用lines这个方法给数据串了一条趋势线,可以很明显的看出来我们的数据不是线性关系。
多项式回归
那么对于我们的数据我可以做如下的多项式回归:
model <- lm(noisy.y ~ poly(q,3))
model <- lm(noisy.y ~ x + I(X^2) + I(X^3))上面两种方法都是一个道理,但是第一种可以很好的避免多重共线性问题,你想嘛,x的平方和x的三次方肯定高度相关啊。所以大家用第一种方法哦,输出结果如下:

上面的结果中没有系数的置信区间,我们可以:
confint(model, level=0.95)
我么还可以画出来模型的残差图:
plot(fitted(model),residuals(model))
总的来说,我们的模型的R方为0.77,q的一次项和3次项都是有统计学意义的,模型还不错。
是不是可以用这个模型做预测呢?
这又涉及到机器学习了,往下看:
我们可以用训练的这个模型来预测我们的原始数据:
predicted.intervals <- predict(model,data.frame(x=q),interval='confidence',level=0.99)你去查看predicted.intervals的值,你可以看到我们200个数据的预测值和置信区间。

最好还是给大家可视化一下,我们打算把原始的趋势线和我们的置信区间的上下限都画在同一个图上:
lines(q,predicted.intervals[,1],col='green',lwd=3)
lines(q,predicted.intervals[,2],col='black',lwd=1)
lines(q,predicted.intervals[,3],col='black',lwd=1)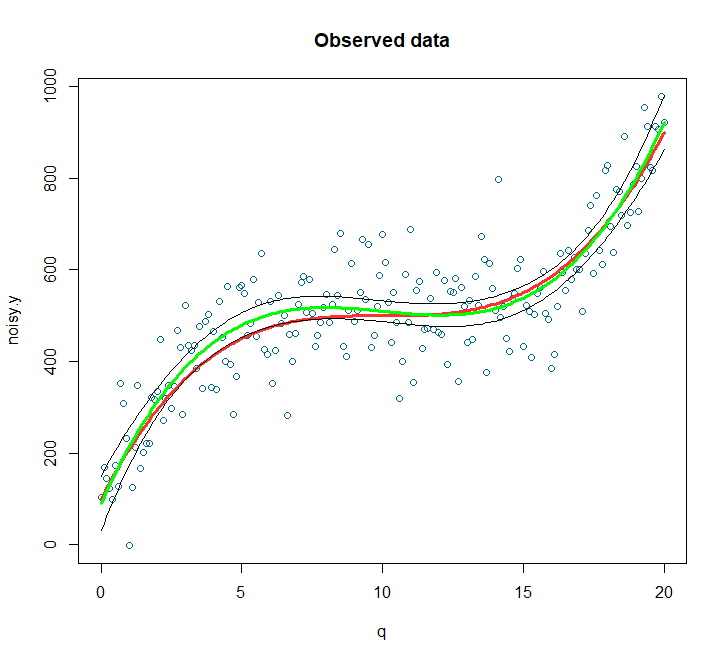
可以看到上图中,我们的砖红色的线基本都在置信区间的上下限范围内,证明了模型不错。
这篇关于R数据分析:如何做数据的非线性关系,多项式回归的做法和解释的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




