本文主要是介绍人工智能|机器学习——基于机器学习的信用卡办卡意愿模型预测项目,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、背景介绍
在金融领域,了解客户的信用卡办卡意愿对于银行和金融机构至关重要。借助机器学习技术,我们可以根据客户的历史数据和行为模式预测其是否有办理信用卡的倾向。本项目通过Python中的机器学习库,构建了两个常用的分类模型:随机森林和逻辑回归,来预测客户的信用卡办卡意愿,通过使用Django框架通过构架可视化的方式分析数据。
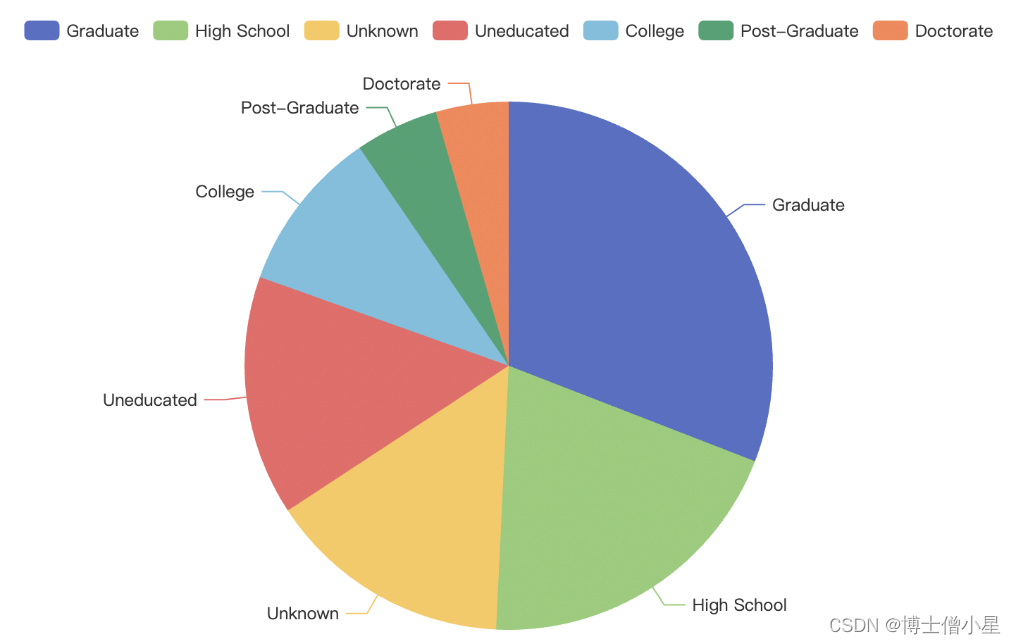
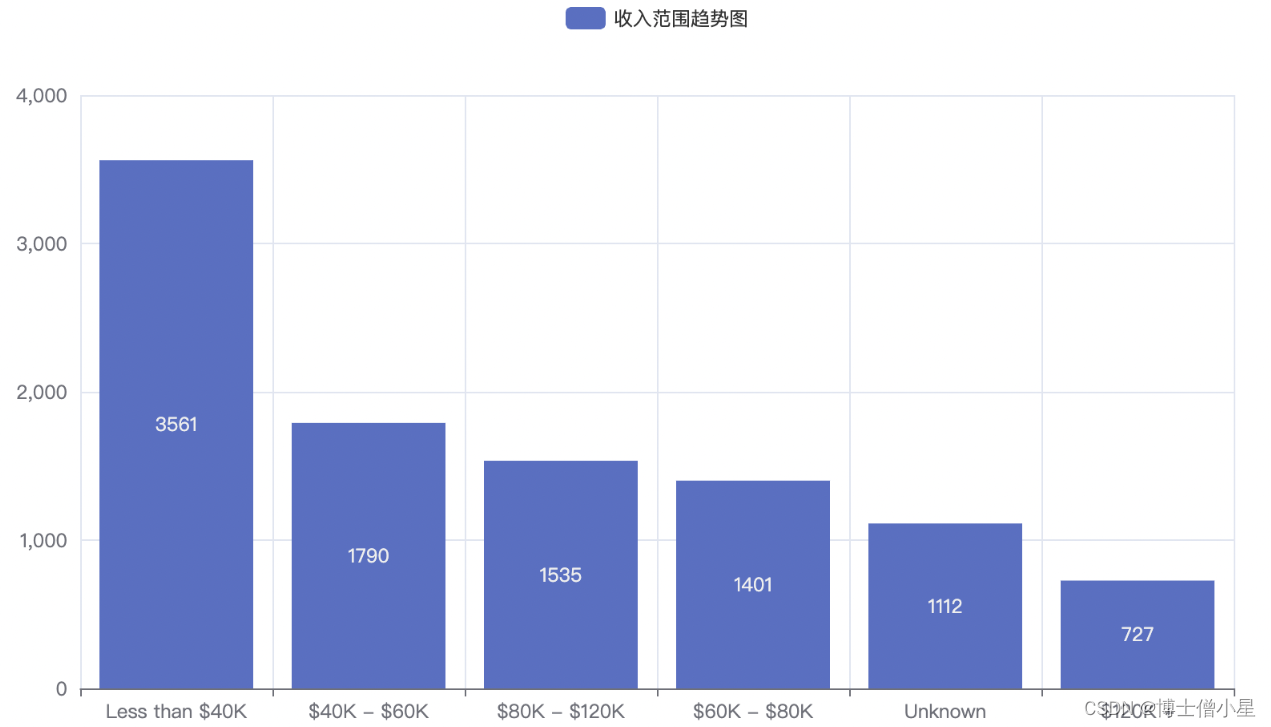

二、数据准备
首先,我们从MySQL数据库中获取处理后的客户数据。这些数据经过预处理和特征工程,包含了客户的各种特征信息,以及是否流失的标签。
# 数据库连接和数据获取
import pandas as pd
import pymysql
from data.mapper import host, user, password, database# 连接MySQL数据库
conn = pymysql.connect(host=host,user=user,password=password,database=database
)# 从MySQL数据库中读取处理后的数据
query = "SELECT * FROM processed_customer_data"
df = pd.read_sql(query, conn)# 关闭数据库连接
conn.close()
三、模型训练与评估
3.1 随机森林模型
随机森林是一种集成学习方法,通过构建多个决策树来进行分类或回归。我们使用随机森林模型对客户的信用卡办卡意愿进行预测,并评估模型性能。
# 随机森林模型训练与评估
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix# 特征与标签分割
X = df.drop(columns=['Attrition_Flag'])
y = df['Attrition_Flag']# 数据集划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=2)# 随机森林模型训练
rf_model = RandomForestClassifier()
rf_model.fit(X_train, y_train)# 模型预测
y_pred = rf_model.predict(X_test)# 模型评估
accuracy = accuracy_score(y_test, y_pred)
classification_rep = classification_report(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)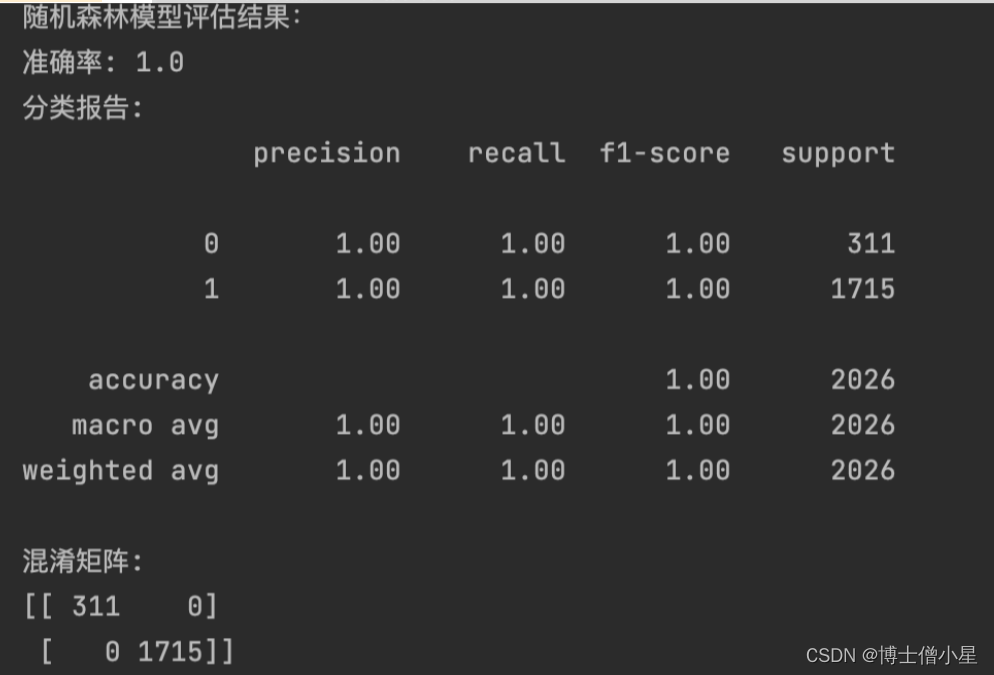
3.2 逻辑回归模型
逻辑回归是一种线性模型,常用于二分类问题。我们同样使用逻辑回归模型对客户的信用卡办卡意愿进行预测,并评估模型性能。
# 逻辑回归模型训练与评估
from sklearn.linear_model import LogisticRegression# 数据集划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 逻辑回归模型训练
logreg_model = LogisticRegression()
logreg_model.fit(X_train, y_train)# 模型预测
y_pred = logreg_model.predict(X_test)# 模型评估
accuracy = accuracy_score(y_test, y_pred)
classification_rep = classification_report(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)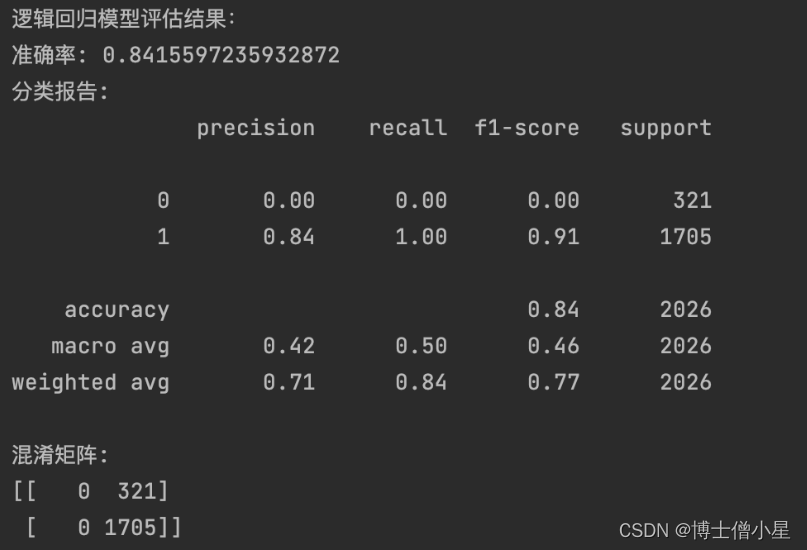
四、数据可视化
我们使用Django作为后端框架实现数据可视化,通过Pyecharts库创建多种图表,以更直观地展示数据分布和模型评估结果。
# Django视图函数中的数据可视化
from django.shortcuts import render
from pyecharts.charts import Bar, Pie, Line
from pyecharts import options as opts
from pyecharts.globals import CurrentConfig, ThemeTypefrom web.service.task_service import get_custormer_age, get_income_category, get_education_level, get_credit_limit, \get_months_inactive_12_mondef bar_chart(request):# 获取客户年龄分布数据x, y = get_custormer_age()line = (Line().add_xaxis([str(age) for age in x]).add_yaxis("Count", y).set_global_opts(title_opts=opts.TitleOpts(title="客户年龄分布图"),xaxis_opts=opts.AxisOpts(name="Age"),yaxis_opts=opts.AxisOpts(name="Count"),))# 获取客户信用卡额度分布数据x1, y1 = get_credit_limit()line1 = (Line().add_xaxis([str(age) for age in x1]).add_yaxis("Count", y1).set_global_opts(title_opts=opts.TitleOpts(title="客户信用卡额度top10分布图"),xaxis_opts=opts.AxisOpts(name="Age"),yaxis_opts=opts.AxisOpts(name="Count"),))# 获取客户非活跃月数分布数据bar1 = Bar()x1, y1 = get_months_inactive_12_mon()bar1.add_xaxis(x1)bar1.add_yaxis("客户去年非活跃月数分布", y1)# 获取客户收入范围趋势数据bar = Bar()x, y = get_income_category()bar.add_xaxis(x)bar.add_yaxis("收入范围趋势图", y)# 获取客户教育水平分布数据pie = Pie()tuple = get_education_level()pie.add("教育水平分布图", tuple)# 获取图表的JavaScript代码line_js = line.render_embed()bar_js = bar.render_embed()pie_js = pie.render_embed()bar1_js = bar1.render_embed()line1_js = line1.render_embed()return render(request, 'charts/bar_chart.html', {'line': line_js, 'bar': bar_js, 'pie': pie_js, 'line1': line1_js, 'bar1': bar1_js})
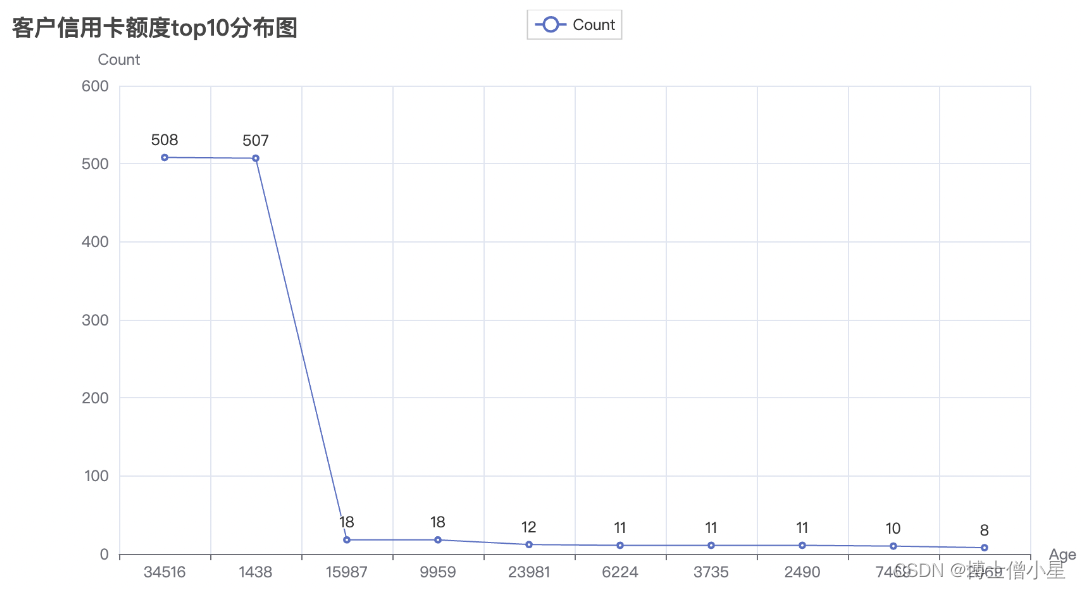

五、总结
通过本项目,我们使用了机器学习模型预测了客户的信用卡办卡意愿,并通过Django实现了数据的可视化展示。这使得银行和金融机构能够更好地理解客户行为模式,并做出相应的业务决策。
这篇关于人工智能|机器学习——基于机器学习的信用卡办卡意愿模型预测项目的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







