本文主要是介绍我们用Python分析了B站4万条数据评论,揭秘本山大叔《念诗之王》大热原因!...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

来源:恋习Python
本文约2000字,建议阅读10分钟。
我们通过Python大法通过获取B站:【春晚鬼畜】赵本山:我就是念诗之王!4万条数据评论,与大家一起看看其背后火起来的原因。

1990年本山老师首次登上中央电视台春节联欢晚会舞台,在春晚舞台给我们留下很多深入人心的作品如《相亲》,《我想有个家》,《昨天今天明天》,到2011年最后一次在春晚舞台表演小品,,22个年头陪我们度过了21个大年夜,每次都期待大叔的压轴出场伴随着零点的钟声一起跨年。

20年里本山老师的影响力是毋庸置疑的,但是小平不是单口相声更不是独角戏,他的成功也是离不开搭档的配合,大家最熟悉的搭档应该是范伟何高秀敏。三个人作为黄金搭档也是演绎了许多经典作品比如《卖拐》,《买车》,《功夫》等。

除了范伟和高秀敏,最令人印象深刻的搭档就是宋丹丹了,虽然合作的不是特别多但是二人合作的《昨天今天明天》和《小崔说事》太深入人心,白云黑土成了大家最喜爱的大叔大妈但宋丹丹多次说过上春晚太累,短期应该不会在合作了吧。

最近你有没有被“改革春风吹满地, 中国人民真争气”魔性的旋律所洗脑?这段视频一经发布,就迅速攻占“快手”“抖音”等各大短视频平台,近日临近春节,仿佛又开始爆发,俨然已经从2018年末火到了2019年初。
恐怕连赵本山本人也不敢相信,自己这么多年演的小品,被人剪辑改变成鬼畜神曲《念诗之王》后,这些经典台词焕发了第二春。《念诗之王》在B站播放量高达2400万,本山大叔,即便已经七八年没上春晚了,依然是毋庸置疑的高人气IP!
接下来,我们通过Python大法通过获取B站:【春晚鬼畜】赵本山:我就是念诗之王!(https://www.bilibili.com/video/av19390801/)4万条数据评论,与大家一起看看其背后火起来的原因。
一、数据获取
在获取视频评论之前,我们首要做的就是分析其网页结构,寻找目标数据(也就是我们要的评论数据在哪里,这点很重要)
最终发现,目标数据的url链接为:
https://api.bilibili.com/x/v2/reply?&type=1&oid=19390801&pn=1
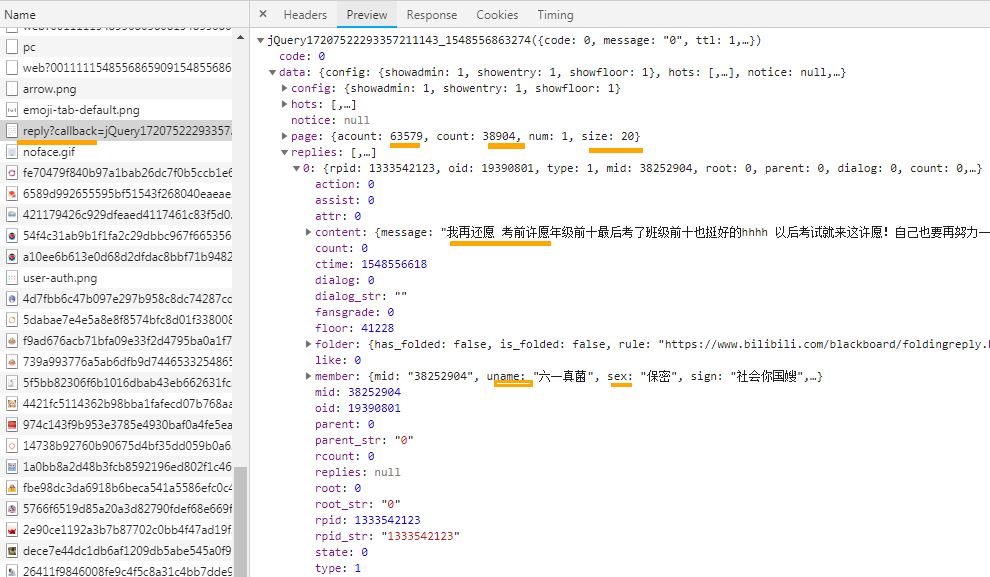
由上图可看出,其评论数据是以json数据形式存在于网页端的,可看出一共有1946页评论,每页评论20条,总评论63579条(楼层下面存在评论)。今天我们与大家一起主要是爬取楼层评论,共1940*20=38920条。
接下来,就爬取思路很明确,从一个JSON文件开始,爬完20条评论,更改路径后获取第二个JSON文件,以此类推,直到爬完所有的评论数据。
我们主要爬取的数据信息有8个维度,如下:

详细代码:
import requests
from fake_useragent import UserAgent
import json
import time
import pandas as pd
#下载网页评论数据
def get_page_json(url):
try:
ua = UserAgent(verify_ssl=False)
headers = {"User-Agent": ua.random}
json_comment = requests.get(url,headers=headers).text
return json_comment
except:
return None
#解析网页评论数据
def parse_page_json(json_comment):
try:
comments = json.loads(json_comment)
except:
return "error"
comments_list = []
#获取当页数据有多少条评论(一般情况下为20条)
num = len(comments['data']['replies'])
for i in range(num):
comment = comments['data']['replies'][i]
comment_list = []
floor = comment['floor']
ctime = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(comment['ctime']))#时间转换
likes = comment['like']
author = comment['member']['uname']
sex = comment['member']['sex']
level = comment['member']['level_info']['current_level']
content = comment['content']['message'].replace('\n','')#将评论内容中的换行符去掉
#print(content)
rcount = comment['rcount']
comment_list.append(floor)
comment_list.append(ctime)
comment_list.append(likes)
comment_list.append(author)
comment_list.append(sex)
comment_list.append(level)
comment_list.append(content)
comment_list.append(rcount)
comments_list.append(comment_list)
save_to_csv(comments_list)
def save_to_csv(comments_list):
data = pd.DataFrame(comments_list)
#注意存储文件的编码为utf_8_sig,不然会乱码,后期会单独深入讲讲为何为这样(如果为utf-8)
data.to_csv('春晚鬼畜_1.csv', mode='a', index=False, sep=',', header=False,encoding='utf_8_sig')
def main():
base_url = "https://api.bilibili.com/x/v2/reply?&type=1&oid=19390801&pn=1"
#通过首页获取评论总页数
pages = int(json.loads(get_page_json(base_url))['data']['page']['count'])//20
for page in range(pages):
url = "https://api.bilibili.com/x/v2/reply?&type=1&oid=19390801&pn="+str(page)
json_comment = get_page_json(url)
parse_page_json(json_comment)
print("正在保存第%d页" % int(page+1))
if page%20 == 0:
time.sleep(5)
main()
可左右滑动哦~
其中主要涉及到两个知识点:
1、通过fake_useragent生成随机UserAgent
不管是做开发还是做过网站的朋友们,应该对于User Agent一点都不陌生,User Agent 中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
通过UA来判断不同的设备或者浏览器是开发者最常用的方式方法,这个也是对于Python反爬的一种策略,但是有盾就有矛啊---我的矛就是让抓取行为和用户访问网站的真实行为尽量一致。
忽略ssl验证:
ua = UserAgent(verify_ssl=False)
2、Chrome控制台中Network的Preview的正确用法
Response:

Preview:

一般情况下我们看Network里面的Preview和Response的结果似乎一模一样。不管是请求页面,请求页面还是请求js还是请求css,二者的结果都一样。直到今天从服务器端向web前端发送一段json格式的数据,才发现Preview的特殊功效。在Preview(预览功能)中,控制台会把发送过来的json数据自动转换成javascript的对象格式。而且可以层层展开,方便前端工程师遍历调用(特别是在多维的情况下),也方便我们Python爬虫工程师解析JSON数据。
二、数据清洗预览
由于我们在解析数据时已经将数据处理过,因此下载存为的数据已经干净,没有杂乱信息。我们从中整理出Top10评论:

从上述评论中也可看出,第三、第四评论内容都是与春晚有关,也可以看出网友对本山大叔回归春晚的期待。看着视频,一句“改革春风吹满地”,回荡在脑海中几天都挥之不去。心里默念着:本山大叔要是能上春晚,该多好啊!
三、后记
在经过全民的参与和发酵过后,各种版本一应而出,尤其是英文版,押韵之余无人能敌!
我只想借这首鬼畜歌曲,回忆一下本山大叔曾经带给我们的欢乐,尤其是那些郎朗上口的台词。文章的最后我想用一句话总结一下,那就是——“我十分想念赵本山!”
你们期待有赵本山的春晚吗
点赞或评论告诉小编吧![]()


这篇关于我们用Python分析了B站4万条数据评论,揭秘本山大叔《念诗之王》大热原因!...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







