本文主要是介绍国内高校大数据教研机构调研报告,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

本篇报告由清华大学大数据研究中心独家支持(原清华-青岛数据科学研究院发起),清华大学新闻传播学院博士后何静(沈阳教授团队)发布,研究内容主要围绕国内高校大数据教研机构的发展现状、教育科研水平及其行业影响力、传播影响力的对比分析等方面。以下为报告部分内容节选:
1 高校大数据研究院发展概述
信息技术的高速发展,促进大数据应用开始融入各行各业,大数据人才需求猛增。在此背景下,大数据人才的培养机制应与产业发展高度结合,着重瞄准行业解决方案,面向计算和存储等领域,培养金融、政务、电商、媒体等方面的复合应用型人才。
我国高校最先开展的是大数据硕士研究生培养,而后才有本科专业招生。2012年,首都经济贸易大学与北京大学、中国科学院大学、中国人民大学和中央财经大学联合成立“大数据分析硕士培养协同创新平台”,在全国率先搭建了大数据硕士人才培养体系。2014年,首都经济贸易大学进一步开设了“统计学专业(大数据分析)”,包括信息管理与信息系统(大数据)和统计学(大数据分析)两个本科专业方向。
2015年9月,国务院印发《促进大数据发展行动纲要》,开始部署大数据相关工作,推进大数据产业的平稳发展。“十三五”规划中也明确提出实施国家大数据战略,实现数据资源共享。2016年2月16日,教育部发布《教育部关于公布2015年度普通高等学校本科专业备案和审批结果的通知》,在“新增审批本科专业名单”中公布新专业“数据科学与大数据技术”。
近日,教育部公布了2020年度普通高等学校本科专业备案和审批结果通知,名单显示,2021年新增数据科学与大数据技术专业共计62所。截至2021年3月1日,数据科学与大数据技术专业审批通过共计693所,大数据管理与应用专业审批通过共计142所,直接或间接与大数据相关的专业多达上千个,并且2016年-至今,相关专业的开设呈现上升趋势。
在此基础上,为了加快学科建设和人才输出,不少高校成立了大数据研究院,通过单独招生或者联合培养的方式,将短期重点聚焦于研究生的培养,以快速培养掌握大数据核心技术、具有创新能力的骨干人才。例如清华大学虽然没有开设大数据本科专业,但是成立了清华大学大数据研究中心,设立了大数据硕士项目和大数据能力提升项目。
由于大数据学院属于新开设的专业方向,因此在基础设施、师资力量、课程体系等方面仍然处于摸索试验阶段,在培养方案上没有形成独立、完善的体系。在大数据专业被独立划分之前,计算机科学与技术、软件工程、电子信息、自动化等多个专业均开设了数据处理、数据挖掘等基础课程,这种附属于某一学科的课程尽管具备了万金油的工具性属性,但失去了大数据作为专业设置的特殊性,导致大数据专业涉及研究方向、研究方法和研究问题的独特性大大减弱,最终成果常常和预期目标不符。例如在核心课程的设置上,大数据专业需要体现出交叉学科的特征,同时又不能“广撒网”式教学,仅仅只是简单地将数学、计算机、统计学课程杂糅在一起很可能变成“多而不精”。另一方面,高校大数据实验室的建设也有所不足。同时,鉴于大数据技术在产业应用上的迫切性和高度相关性,高校应当积极与企业合作,共享基础数据库,搭建大数据管理平台等,便于开展各项学术研究活动。
2 高校大数据研究机构影响力评估体系
2.1评估对象
本报告针对各高校大数据教研机构近年来的教学和科研成果进行汇总,制定了四级量化表,分别从教育影响力、科研影响力、社会影响力三个方面进行分析。
其中,教育影响力包括教学条件、人才培养两个维度,评测高校数据研究机构在教育教学方面的投入与水平,这是高校研究院区别于商业研究院的一大特点;科研影响力则包括科研规模、创新能力、科研成果转化能力及国内外交流情况,结合对国内外学界在大数据领域成果进展的数据调研,对比分析各高校大数据教研机构在学术研究领域的影响力;社会影响力关注各高校大数据教研机构的媒体指数,从高校大数据教研机构的传播内容、传播渠道、传播效果等维度进行数据的调研对比,分析其整体社会影响力。
2.2评估维度与指标
四级指数模型如下表所示,在权重设置上,设置教育影响力、科研影响力、社会影响力三部分所占权重相同。

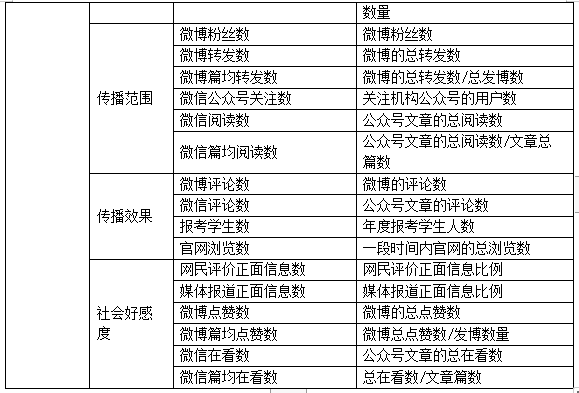
2.3评估方法
大数据的质量评估涉及了多个维度。部分学者基于不同的应用环境或不同视界,建立了大数据质量评价体系和评价模型。对于数据质量的特征,美国普查局[1]将数据质量归纳为如下几个方面:准确性、一致性、透明度、代表性、完整性、安全性、持续性;王力和周晓剑[2]认为,数据质量是由可得性、可用性、可靠性、相关性、外观质量5个维度构成的;刘金晶和曹文洁[3]则提出从完整性、一致性、准确性和及时性4个方面进行度量;丁小欧等[4]对不同数据质量性质进行归纳总结,将数据质量维度分为核心与外围,并对核心指标进行细化,同时对所有核心指标做相关分析,进而建立数据质量综合评价框架;基于数据生命周期,莫祖英[5]则将大数据质量划分为原始质量、过程质量和结果质量,并提出不同的测度指标,利用专家打分和问卷调查确定权重,进而建立大数据质量综合评价模型;黄永鑫[6]提出了“3As”模型,该模型利用上下文充分性、操作充分性和时间充足性这3个数据质量特征来评估大数据的使用质量水平;基于数据使用问题,李建中等[7]从大数据众多的质量评价指标中抽象出一致性、精确性、完整性、时效性、实体同一性这5个指标,认为其具有实际可行性。
因半结构化数据和非结构化数据在大数据中占比较大,不少研究人员针对此类数据进行研究。韩京宇和陈可佳[8]基于事实抽取评估数据的准确性和完整性,在 Web 上构建目标文档上下文;汤莉、宫秀军、何丽[9]提出基于 PAC-Bayes 理论的 Web 文档数据质量评估方法;余芳东[10]将数据质量保证框架分为数据源条件、元数据和数据3个维度,每个维度包括若干个质量要素;李森有等[11]提出基于质量标准度量的全数据质量评估方法,从而评估互联网平台中的大数据质量.....综上,现有大数据质量评估方法通常利用综合评价和聚类思想,其评估视角绝大多数基于数据质量表征和数据生命周期,重点研究社会各界极为关切的大数据使用质量。本研究以定量分析为基础,探索如何解决多源数据融合问题,并基于数据生命周期提出大数据质量评估方法,构建相应模型,使研究结果更具说服力和针对性。
1)教育影响力指数评估模型的构建。在借鉴已有指标模型构建的基础上,结合大数据研究院的自身特点,秉承客观性、公正性、可操作等原则,对获取数据进行价值提炼和技术处理,运用统计分析法和相关数学模型,构建起一个基于大数据,且开放、透明、不断更新迭代的教育影响力综合评估体系,多维度反映高校数据研究院的教育影响力。
2)科研影响力评估体系的构建。基于评估模型分析及质量评估结果,参考相关科研机构的研究案例和经典理论,深入探析大数据快速发展的背景下高校数据研究院提升科研影响力的实现路径。依托舆情大数据平台的广泛影响力和丰富技术经验,定期发布相关榜单和发展报告,实时解读高校数据研究院发展脉络。
3)社会影响力指数评估模型的构建。在借鉴已有指标模型构建的基础上&#x
这篇关于国内高校大数据教研机构调研报告的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




