本文主要是介绍【数据结构与算法】之8道顺序表与链表典型编程题心决!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
个人主页:秋风起,再归来~
数据结构与算法
个人格言:悟已往之不谏,知来者犹可追
克心守己,律己则安!

目录
1、顺序表
1.1 合并两个有序数组
1.2 原地移除数组中所有的元素val
2、链表
2.1 移除链表元素
2.2 反转链表
2.3 合并两个有序链表
2.4 链表的中间节点
2.5 环形链表的约瑟夫问题
2.6 分割链表
3、完结散花
1、顺序表
1.1 合并两个有序数组
题目描述:
给你两个按 非递减顺序 排列的整数数组
nums1和nums2,另有两个整数m和n,分别表示nums1和nums2中的元素数目。请你 合并
nums2到nums1中,使合并后的数组同样按 非递减顺序 排列。注意:最终,合并后数组不应由函数返回,而是存储在数组
nums1中。为了应对这种情况,nums1的初始长度为m + n,其中前m个元素表示应合并的元素,后n个元素为0,应忽略。nums2的长度为n。示例 1:
输入:nums1 = [1,2,3,0,0,0], m = 3, nums2 = [2,5,6], n = 3 输出:[1,2,2,3,5,6] 解释:需要合并 [1,2,3] 和 [2,5,6] 。 合并结果是 [1,2,2,3,5,6] ,其中斜体加粗标注的为 nums1 中的元素。示例 2:
输入:nums1 = [1], m = 1, nums2 = [], n = 0 输出:[1] 解释:需要合并 [1] 和 [] 。 合并结果是 [1] 。示例 3:
输入:nums1 = [0], m = 0, nums2 = [1], n = 1 输出:[1] 解释:需要合并的数组是 [] 和 [1] 。 合并结果是 [1] 。 注意,因为 m = 0 ,所以 nums1 中没有元素。nums1 中仅存的 0 仅仅是为了确保合并结果可以顺利存放到 nums1 中。提示:
nums1.length == m + nnums2.length == n0 <= m, n <= 2001 <= m + n <= 200-109 <= nums1[i], nums2[j] <= 109OJ链接:合并两个有序数组
解题代码:
void merge(int* nums1, int nums1Size, int m, int* nums2, int nums2Size, int n) {int tail=nums1Size-1;int p1=m-1;int p2=n-1;while(p1>=0&&p2>=0){if(nums1[p1]>nums2[p2]){nums1[tail--]=nums1[p1--];}else{nums1[tail--]=nums2[p2--];}}if(p1<0){while(p2>=0){nums1[tail--]=nums2[p2--];}}
}1.2 原地移除数组中所有的元素val
题目描述:
给你一个数组
nums和一个值val,你需要 原地 移除所有数值等于val的元素,并返回移除后数组的新长度。不要使用额外的数组空间,你必须仅使用
O(1)额外空间并 原地 修改输入数组。元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
说明:
为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以「引用」方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
// nums 是以“引用”方式传递的。也就是说,不对实参作任何拷贝 int len = removeElement(nums, val);// 在函数里修改输入数组对于调用者是可见的。 // 根据你的函数返回的长度, 它会打印出数组中 该长度范围内 的所有元素。 for (int i = 0; i < len; i++) {print(nums[i]); }示例 1:
输入:nums = [3,2,2,3], val = 3 输出:2, nums = [2,2] 解释:函数应该返回新的长度 2, 并且 nums 中的前两个元素均为 2。你不需要考虑数组中超出新长度后面的元素。例如,函数返回的新长度为 2 ,而 nums = [2,2,3,3] 或 nums = [2,2,0,0],也会被视作正确答案。示例 2:
输入:nums = [0,1,2,2,3,0,4,2], val = 2 输出:5, nums = [0,1,3,0,4] 解释:函数应该返回新的长度 5, 并且 nums 中的前五个元素为 0 1,3,0, 4。注意这五个元素可为任意顺序。你不需要考虑数组中超出新长度后面的元素。提示:
0 <= nums.length <= 1000 <= nums[i] <= 500 <= val <= 100OJ链接移除元素
解题代码:
int removeElement(int* nums, int numsSize, int val) {if(numsSize<=0||nums==NULL)return 0;int cur=0;//用cur去遍历原数组int newNums=0;while(numsSize--){if(nums[cur]==val){cur++;}else{nums[newNums++]=nums[cur++];}}return newNums;
}2、链表
2.1 移除链表元素
题目描述:
给你一个链表的头节点
head和一个整数val,请你删除链表中所有满足Node.val == val的节点,并返回 新的头节点 。示例 1:
输入:head = [1,2,6,3,4,5,6], val = 6 输出:[1,2,3,4,5]示例 2:
输入:head = [], val = 1 输出:[]示例 3:
输入:head = [7,7,7,7], val = 7 输出:[]提示:
- 列表中的节点数目在范围
[0, 104]内1 <= Node.val <= 500 <= val <= 50
OJ链接:移除链表元素

解题代码:
typedef struct ListNode ListNode;
struct ListNode* removeElements(struct ListNode* head, int val) {if(head==NULL)return NULL;ListNode* newHead=(ListNode*)malloc(sizeof(ListNode));//创建一个带哨兵卫的头结点ListNode* newTail=newHead;ListNode* cur=head;while(cur){if(cur->val==val){cur=cur->next;}else{newTail->next=cur;newTail=newTail->next;cur=cur->next;}}newTail->next=NULL;return newHead->next;
}2.2 反转链表
题目描述:
给你单链表的头节点
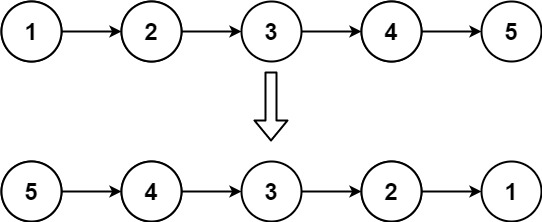
head,请你反转链表,并返回反转后的链表。示例 1:
输入:head = [1,2,3,4,5] 输出:[5,4,3,2,1]示例 2:
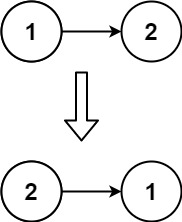
输入:head = [1,2] 输出:[2,1]示例 3:
输入:head = [] 输出:[]提示:
- 链表中节点的数目范围是
[0, 5000]-5000 <= Node.val <= 5000
题目链接:反转单链表
解题代码:
typedef struct ListNode ListNode;
struct ListNode* reverseList(struct ListNode* head) {if(head==NULL)return NULL;ListNode* n1,*n2,*n3;n1=NULL;n2=head;n3=head->next;while(n2){n2->next=n1;n1=n2;n2=n3;if(n3){n3=n3->next;}}return n1;
}2.3 合并两个有序链表
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例 1:
输入:l1 = [1,2,4], l2 = [1,3,4] 输出:[1,1,2,3,4,4]示例 2:
输入:l1 = [], l2 = [] 输出:[]示例 3:
输入:l1 = [], l2 = [0] 输出:[0]提示:
- 两个链表的节点数目范围是
[0, 50]-100 <= Node.val <= 100l1和l2均按 非递减顺序 排列OJ链接:合并两个有序链表

typedef struct ListNode ListNode;
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2) {ListNode* newHead,*newTail;newTail=newHead=(ListNode*)malloc(sizeof(ListNode));ListNode* l1=list1;ListNode* l2=list2;while(l1&&l2){if((l1->val)<(l2->val)){newTail->next=l1;l1=l1->next;}else{newTail->next=l2;l2=l2->next;}newTail=newTail->next;}if(l1){newTail->next=l1;}else{newTail->next=l2;}return newHead->next;
}2.4 链表的中间节点
给你单链表的头结点
head,请你找出并返回链表的中间结点。如果有两个中间结点,则返回第二个中间结点。
示例 1:
输入:head = [1,2,3,4,5] 输出:[3,4,5] 解释:链表只有一个中间结点,值为 3 。示例 2:
输入:head = [1,2,3,4,5,6] 输出:[4,5,6] 解释:该链表有两个中间结点,值分别为 3 和 4 ,返回第二个结点。提示:
- 链表的结点数范围是
[1, 100]1 <= Node.val <= 100
OJ链接链表的中间节点


typedef struct ListNode ListNode;
struct ListNode* middleNode(struct ListNode* head) {if(head==NULL)return NULL;ListNode* fast,*slow;fast=slow=head;while(fast&&fast->next){fast=fast->next->next;slow=slow->next;}return slow;
}2.5 环形链表的约瑟夫问题
编号为 1 到 n 的 n 个人围成一圈。从编号为 1 的人开始报数,报到 m 的人离开。
下一个人继续从 1 开始报数。
n-1 轮结束以后,只剩下一个人,问最后留下的这个人编号是多少?
数据范围: 1≤n,m≤10000
进阶:空间复杂度O(1),时间复杂度 O(n)
OJ链接:环形链表的约瑟夫问题
typedef struct ListNode ListNode;
ListNode* byNode(int x)
{ListNode* node=(ListNode*)malloc(sizeof(ListNode));if(node==NULL){exit(1);}node->val=x;return node;
}
ListNode* creatCircle(int x)
{ListNode* head=(ListNode*)malloc(sizeof(ListNode));//创建头结点if(head==NULL){exit(1);}ListNode* tail=head;for(int i=1;i<=x;i++){tail->next=byNode(i);tail=tail->next;}tail->next=head->next;return tail;
}int ysf(int n, int m ) {// write code here//创建循环链表并返回尾节点ListNode* prev=creatCircle(n);ListNode* cur=prev->next;int count=1;//报数while(cur!=cur->next){if(count==m){prev->next=cur->next;free(cur);cur=prev->next;count=1;//重置为1}else {prev=cur;cur=cur->next;count++;}}return cur->val;
}2.6 分割链表
给你一个链表的头节点
head和一个特定值x,请你对链表进行分隔,使得所有 小于x的节点都出现在 大于或等于x的节点之前。你不需要 保留 每个分区中各节点的初始相对位置。
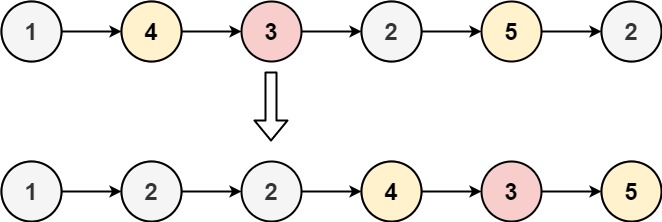
示例 1:
输入:head = [1,4,3,2,5,2], x = 3 输出:[1,2,2,4,3,5]示例 2:
输入:head = [2,1], x = 2 输出:[1,2]提示:
- 链表中节点的数目在范围
[0, 200]内-100 <= Node.val <= 100-200 <= x <= 200
OJ链接:分割链表
typedef struct ListNode ListNode;
struct ListNode* partition(struct ListNode* head, int x){if(head==NULL){return NULL;}//创建两个头结点ListNode* lessHead=(ListNode*)malloc(sizeof(ListNode));if(lessHead==NULL){exit(1);}ListNode* greaterHead=(ListNode*)malloc(sizeof(ListNode));if(greaterHead==NULL){exit(1);}ListNode* lessTail=lessHead;ListNode* greaterTail=greaterHead;lessHead->next=greaterHead->next=NULL;ListNode* cur=head;while(cur){if(cur->val<x){lessTail->next=cur;lessTail=lessTail->next;}else{greaterTail->next=cur;greaterTail=greaterTail->next;}cur=cur->next;}lessTail->next=greaterHead->next;greaterTail->next=NULL;return lessHead->next;
}
3、完结散花
好了,这期的分享到这里就结束了~
如果这篇博客对你有帮助的话,可以用你们的小手指点一个免费的赞并收藏起来哟~
如果期待博主下期内容的话,可以点点关注,避免找不到我了呢~
我们下期不见不散~~


这篇关于【数据结构与算法】之8道顺序表与链表典型编程题心决!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






