本文主要是介绍【Python特征工程系列】使用Boruta算法进行特征重要性分析(案例+源码),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这是我的第258篇原创文章。
一、引言
Boruta是一种基于随机森林算法的特征筛选方法。其核心是基于两个思想:随机生成的特征(shadow features)和 不断迭代(循环),它通过循环比较原始特征(real features)和随机生成的特征(shadow features)的重要性来确定哪些特征与因变量相关。它可以应用于任何需要特征选择的监督学习问题,帮助我们确定哪些特征与因变量相关,从而更好地理解数据并建立更准确的预测模型。
二、实现过程
2.1 准备数据
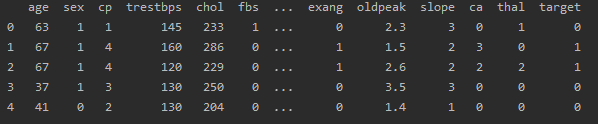
data = pd.read_csv(r'dataset.csv')
df = pd.DataFrame(data)df:
2.2 数据划分
# 目标变量和特征变量
target = 'target'
features = df.columns.drop(target)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(df[features], df[target], test_size=0.2, random_state=0)2.3 创建Boruta对象
基于随机森林分类器创建一个Boruta的选择对象:
model = RandomForestClassifier(n_estimators=100, random_state=0)
feat_selector = BorutaPy(model, n_estimators='auto', verbose=2, random_state=1)
feat_selector.fit(np.array(X_train), np.array(y_train))2.4 特征选择
1、输出各个特征的重要性排名:
print('\n Feature ranking:')
print(pd.DataFrame({"feature":features, 'feature_ranking':feat_selector.ranking_}))
2、特征是否被选择:
print('\n Selected features:')
print(pd.DataFrame({"feature":features, 'Selected':feat_selector.support_}))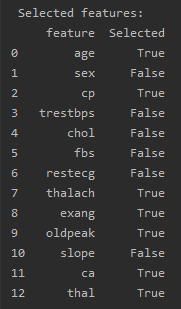
返回一个布尔类型的数组,代表每个特征是否被选择。如果特征被选择,对应的值为True,否则为False。
3、是否存在一些弱特征被选择:
print('\n Support for weak features:')
print(pd.DataFrame({"feature":features, 'Selected':feat_selector.support_weak_}))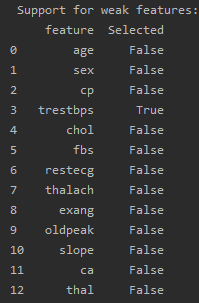
返回一个布尔类型的数组,代表是否存在一些弱特征被选择。如果特征是弱特征且被选择,对应的值为True,否则为False。
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。
这篇关于【Python特征工程系列】使用Boruta算法进行特征重要性分析(案例+源码)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



