本文主要是介绍【域适应】基于深度域适应MMD损失的典型四分类任务实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
关于
MMD (maximum mean discrepancy)是用来衡量两组数据分布之间相似度的度量。一般地,如果两组数据分布相似,那么MMD 损失就相对较小,说明两组数据/特征处于相似的特征空间中。基于这个想法,对于源域和目标域数据,在使用深度学习进行特征提取中,使用MMD损失,可以让模型提取两个域的共有特征/空间,从而实现源域到目标域的迁移。
参考论文:https://arxiv.org/abs/1409.6041
工具
Python

方法实现
定义mmd函数
#!/usr/bin/env python
# encoding: utf-8import torch# Consider linear time MMD with a linear kernel:
# K(f(x), f(y)) = f(x)^Tf(y)
# h(z_i, z_j) = k(x_i, x_j) + k(y_i, y_j) - k(x_i, y_j) - k(x_j, y_i)
# = [f(x_i) - f(y_i)]^T[f(x_j) - f(y_j)]
#
# f_of_X: batch_size * k
# f_of_Y: batch_size * k
def mmd_linear(f_of_X, f_of_Y):delta = f_of_X - f_of_Yloss = torch.mean(torch.mm(delta, torch.transpose(delta, 0, 1)))return lossdef guassian_kernel(source, target, kernel_mul=2.0, kernel_num=5, fix_sigma=None):n_samples = int(source.size()[0])+int(target.size()[0])total = torch.cat([source, target], dim=0)total0 = total.unsqueeze(0).expand(int(total.size(0)), int(total.size(0)), int(total.size(1)))total1 = total.unsqueeze(1).expand(int(total.size(0)), int(total.size(0)), int(total.size(1)))L2_distance = ((total0-total1)**2).sum(2)if fix_sigma:bandwidth = fix_sigmaelse:bandwidth = torch.sum(L2_distance.data) / (n_samples**2-n_samples)bandwidth /= kernel_mul ** (kernel_num // 2)bandwidth_list = [bandwidth * (kernel_mul**i) for i in range(kernel_num)]kernel_val = [torch.exp(-L2_distance / bandwidth_temp) for bandwidth_temp in bandwidth_list]return sum(kernel_val)#/len(kernel_val)def mmd_rbf_accelerate(source, target, kernel_mul=2.0, kernel_num=5, fix_sigma=None):batch_size = int(source.size()[0])kernels = guassian_kernel(source, target,kernel_mul=kernel_mul, kernel_num=kernel_num, fix_sigma=fix_sigma)loss = 0for i in range(batch_size):s1, s2 = i, (i+1)%batch_sizet1, t2 = s1+batch_size, s2+batch_sizeloss += kernels[s1, s2] + kernels[t1, t2]loss -= kernels[s1, t2] + kernels[s2, t1]return loss / float(batch_size)def mmd_rbf_noaccelerate(source, target, kernel_mul=2.0, kernel_num=5, fix_sigma=None):batch_size = int(source.size()[0])kernels = guassian_kernel(source, target,kernel_mul=kernel_mul, kernel_num=kernel_num, fix_sigma=fix_sigma)XX = kernels[:batch_size, :batch_size]YY = kernels[batch_size:, batch_size:]XY = kernels[:batch_size, batch_size:]YX = kernels[batch_size:, :batch_size]loss = torch.mean(XX + YY - XY -YX)return loss
定义基于mmd特征对齐CNN模型
# encoding=utf-8import torch.nn as nn
import torch.nn.functional as Fclass Network(nn.Module):def __init__(self):super(Network, self).__init__()self.conv1 = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=64, kernel_size=(1, 3)),nn.ReLU())self.conv2 = nn.Sequential(nn.Conv2d(in_channels=64, out_channels=64, kernel_size=(1, 3)),nn.ReLU(),nn.Dropout(0.4),nn.MaxPool2d(kernel_size=(1, 2), stride=2))self.fc1 = nn.Sequential(nn.Linear(in_features=64 * 98, out_features=100),nn.ReLU())self.fc2 = nn.Sequential(nn.Linear(in_features=100, out_features=2))def forward(self, src, tar):x_src = self.conv1(src)x_tar = self.conv1(tar)x_src = self.conv2(x_src)x_tar = self.conv2(x_tar)#print(x_src.shape)x_src = x_src.reshape(-1, 64 * 98)x_tar = x_tar.reshape(-1, 64 * 98)x_src_mmd = self.fc1(x_src)x_tar_mmd = self.fc1(x_tar)#x_src = self.fc1(x_src)#x_tar = self.fc1(x_tar)#x_src_mmd = self.fc2(x_src)#x_tar_mmd = self.fc2(x_tar)y_src = self.fc2(x_src_mmd)return y_src, x_src_mmd, x_tar_mmd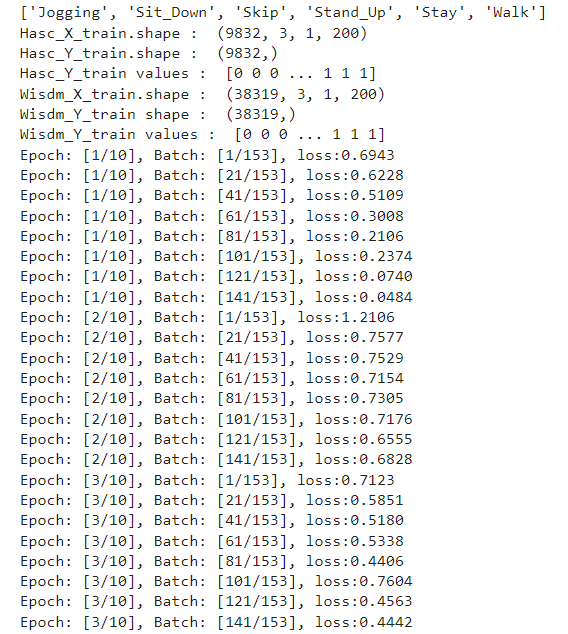
代码获取
后台私信;
其他相关域适应问题和代码开发,欢迎沟通和交流。
这篇关于【域适应】基于深度域适应MMD损失的典型四分类任务实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






