本文主要是介绍揭秘京东文件系统JFS的前世今生,支持双11每秒约10万个对象同时读写,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
背景
作为一家大规模的自营式电商企业,京东需要存储海量的非结构化数据:商品图片、订单文本、仓库流转记录、App客户端文件、日志文件、内部文档等。对于存储这些数据,之前并没有统一的解决方案,都是各个业务线自行解决——MySQL BLOB、HDFS、FastDFS。
2013年5月,京东开始组建存储组,自主研发JFS——京东文件系统,以实现非结构化数据存储统一服务为目标。
小文件存储
针对3个典型的应用场景——商品图片、OFC订单、WMS库房流水,JFS第一版定位为海量小文件存储,其核心功能定义如下。
- 海量小文件存储,极高的可靠性、可用性与一致性。
- Key-File数据模型,Key由系统生成,全局唯一;文件immutable,即不可修改,甚至极少被删除。
其主要包含如下3个模块。
- ZooKeeper作为集群协调器管理元数据信息。
- 由Go语言开发的DataNode,实现服务端读写逻辑、复制协议、故障恢复等。每个DataNode管理一块磁盘——该设计大幅简化了工程实现。
- 由Java开发的客户端。
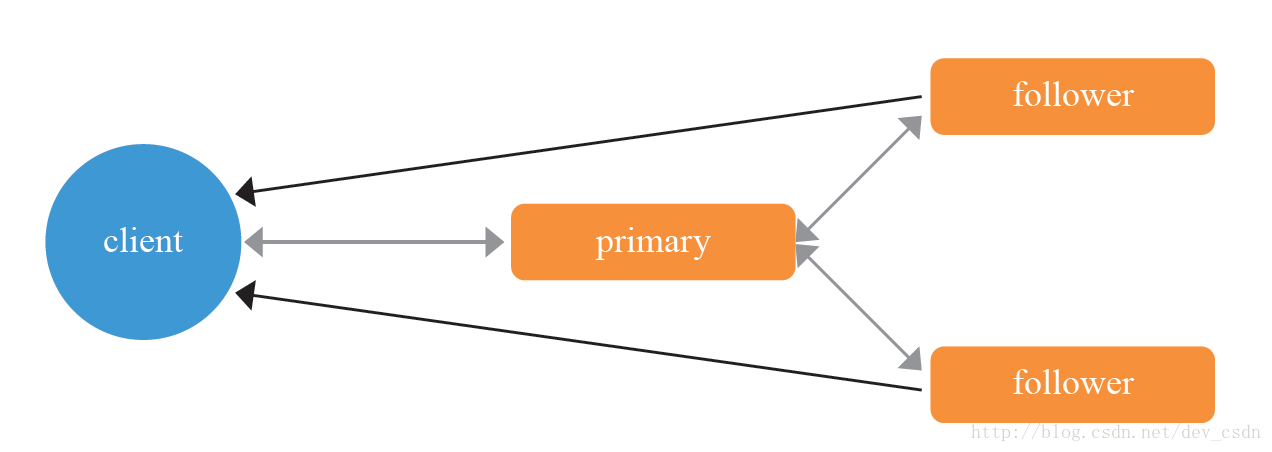
复制协议实现了一种Paxos变体,或者说一种极简的Paxos实现,如图1所示:固定成员(一个复制组由1primary + 2follower构成)、固定角色(primary与follower角色不会发生变更)、固定读写流程(client将写操作发送到primary,它在写本地的同时将写操作发给两个follower,三副本都写入成功后才成功返回给用户;优先在follower上读取,提高系统的并发能力)。
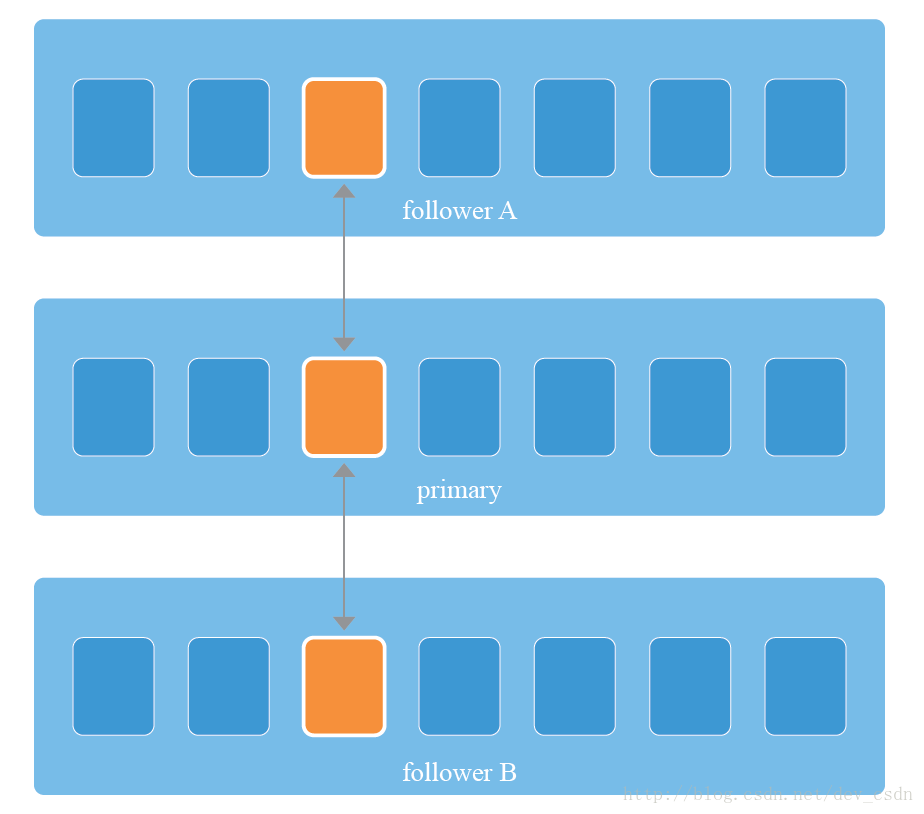
存储引擎采用Append-Only方式,每个DataNode维护一组(默认配置为512)Chunk大文件,客户端上传的小文件(如一张图片)被并行追加至一个复制组三名成员对应的Chunk中,如图2所示。
JFS为每个成功上传的小文件生成全局唯一的JFS Key来编码其存储位置信息:
- 1
比如,jfs/t3442/251/2127752103/150148/57583d02/5844d73fNaca4af3d.jpg是京东网站上一款电饭煲的主图的JFS Key,表示该图片存储在3442号复制组、251号Chunk的2127752103字节偏移处,长度为150148字节,CRC校验码为57583d02,签名5844d73fNaca4af3d用于防止URL篡改攻击。
图片系统
基于JFS小文件存储系统,我们在2014年春天重新建设了京东商品图片系统(系统架构如图3所示),并在公司上市之前成功上线。之后,图片系统零故障稳定运行至今,历经商品图片规模从十亿到百亿的大幅增长。
同一张商品图片可能有数十种不同的规格(不同的设备、展现格式、降质参数),但源站JFS只存一副原图,CDN会缓存各种规格的图片URL,CDN未命中的图片则进行回源实时处理并返回。这样不仅节约了源站JFS的存储空间,也可以灵活地满足业务不断变化的需求。

在解决最核心的图片存储和处理问题后,我们也做了很多工作来推动图片技术的发展。在缩放效率上,引入ICC、IPP编译将图片缩放性能提升到最初的3倍以上。在流量优化方面,将Webp格式引入京东,与无线部门紧密合作,将移动端的图片全部替换成Webp格式,给用户节省约35%的下行流量,并显著提升了用户体验。
大文件存储
JFS V2实现大文件存储功能。对于大文件写操作来说,类Paxos复制协议并不合适。primary拿到数据后同时发送给两个follower,这样primary的带宽资源将成为系统的瓶颈。因此,在大文件存储复制协议的选择上,JFS采取了链式复制(Chained Replication)以提高写操作吞吐量。链式复制结构如图4所示。在数据发送和接收上,也均使用了流水线处理,进一步提高了数据传输效率。

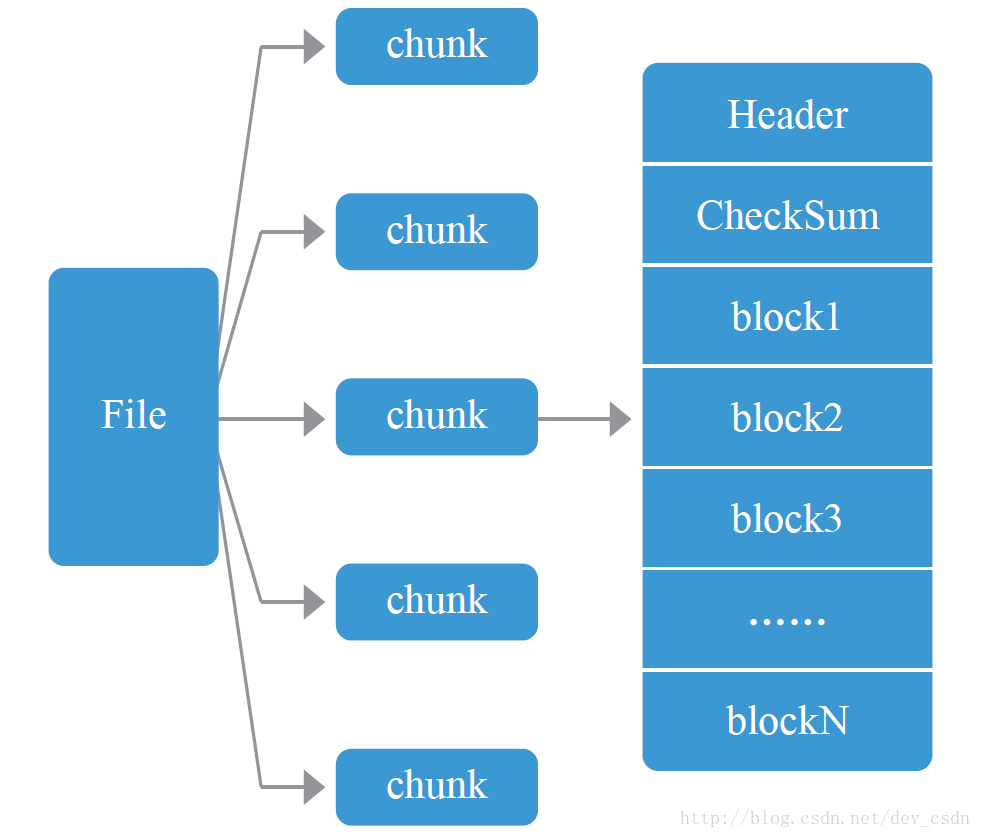
在数据存储结构设计上,恰恰与小文件相反,将一个大文件分成多个块来存储,这样可以规避局部过热的文件造成单机磁盘I/O过载;另外,分成多块也更利于整个系统资源的调度。大文件的数据存储如图5所示。
对象存储服务
JFS的小文件存储和大文件存储功能,从可靠性、可用性和稳定性方面,已经满足了大部分的业务需求,但使用起来却不是很方便,上传和下载都需要通过SDK,用户排查问题不是那么便捷,且对多语言的支持也不好。我们构建了JFS V3产品形态:简单对象存储,支持HTTP协议;支持文本、图片、视频等任何类型数据的存储;支持1个字节到1TB大小的数据存储;支持List操作,用户数据可以有层次结构。JFS V3为众多业务场景提供了最便捷的数据访问方式。
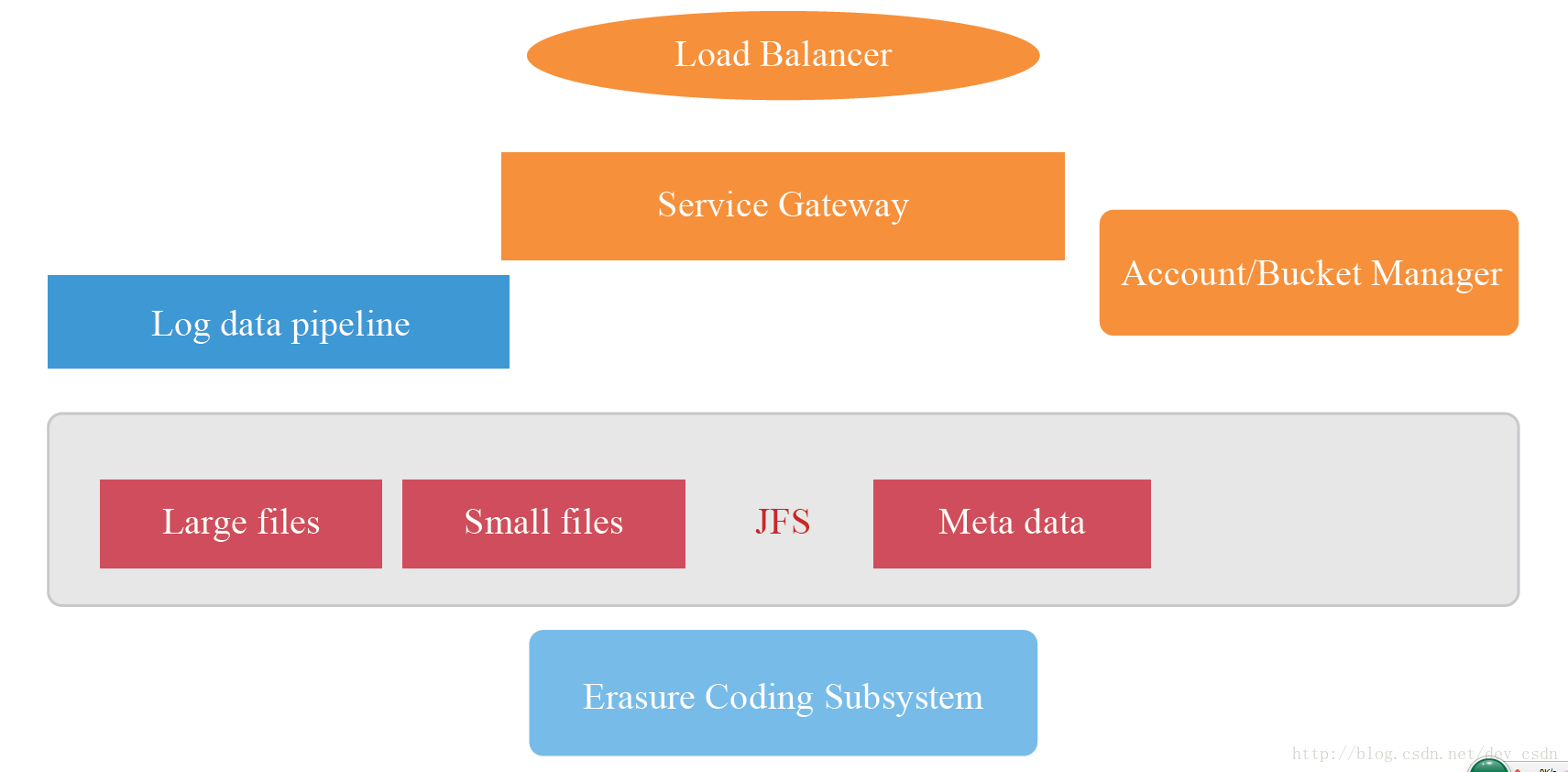
对象存储系统架构如图6所示。除了前面已经提到的大小文件存储,还需要构建Gateway、账户和Bucket管理、日志处理等,当然还有最复杂的元数据管理。
对象存储的元数据管理是一个业内难题。虽然对象存储并无目录的概念,但要支持按前缀进行List的操作,即能通过Prefix和Delimiter的结合,实现层次查询,是有一定难度的。在数据量不大时,类似于Hdfs的NameNode将全部用户Key都存在内存中就能满足需求,但当对象的数量超过十亿时,将会耗尽内存,无法做到横向扩展。很多KV存储能做到随意横向扩展,却不能很好地支持对象存储List请求。
JFS V3采用JED(京东弹性数据库)和JIMDB(京东内存存储系统)组合,来实现对象存储元数据的有效管理。将元数据扁平化持久存储在弹性数据库JED中,热点缓存在JIMDB中,一方面利用JED的单库MySQL的B树结构实现元数据的List层次查询;另一方面使用JIMDB实现高速单Key查询。当数据量达到一定阈值时,JED可以进行在线的扩容与重新分片,JIMDB也可以做动态容量扩展,这使得JFS V3服务逻辑层在工程实现上非常简单。
电子签收
JFS V3作为对象存储服务,一经推出就受到业务部门的广泛欢迎,电子签收小票的存储管理就是一个特别典型的应用。
从环保和成本的角度出发,运营系统青龙研发部创新性地启动了电子签收项目,取代之前每天数百万张的纸质小票。电子签收产生的海量签名图片需要高安全性、高稳定性、高持久性地保存。这无疑是对象存储的一个很好的应用场景,在此之上我们还实现了加解密、文字转图片、图片合成等定制化需求。基于JFS对象存储的电子签收后台系统,根据传回来的签收信息,按照指定样式生成签收小票图片并与用户签名图片合成,再按照业务安全性要求做数据加解密处理。如图7所示。
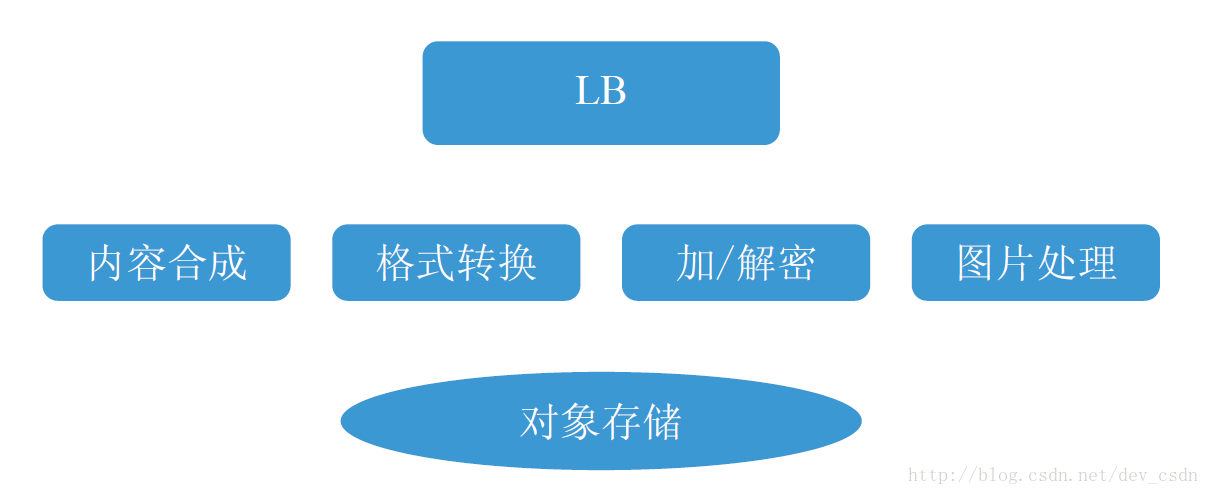
经过过去4年的发展,JFS对象存储目前支持京东1200多个业务的数据存储,双11最高峰值为每秒约10万个对象同时读写,存储对象数目达数百亿级别,数据总量达数十PB。
本文节选自:《京东基础架构建设之路(全彩)》一书;

编辑推荐:
1. 从无到有的架构建设之路,逐步解决业务痛点;
2. 一线架构师的前线战报,为618、11.11保驾护航;
3. 全面解析京东基础架构技术,承载亿级规模存储和流量的基础架构实践;
4. 集诸多热点技术之大成:容器/数据库/存储/中间件/全链路军演/异地多- 活/电商中的机器学习应用。
http://blog.csdn.net/dev_csdn/article/details/78612933
这篇关于揭秘京东文件系统JFS的前世今生,支持双11每秒约10万个对象同时读写的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





