本文主要是介绍中国500米分辨率年最大EVI数据集,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
增强型植被指数(EVI)是在归一化植被指数(NDVI)改善出来的,根据大气校正所包含的影像因子大气分子、气溶胶、薄云、水汽和臭氧等因素进行全面的大气校正,EVI大气校正分三步,第一步是去云处理。第二步是大气校正处理,校正内容除了NDVI已有的瑞利散射和臭氧外,还包括大气分子、气溶胶、水汽等。第三步是进一步处理残留气溶胶影响,方法是借助蓝光和红光通过气溶胶的差异。由于输入的NIR、Red、Blue都经过比较严格的大气校正,所以在设计植被指数算式时,无须为了消除乘法性噪音而采用基于NIR/Red比值的植被指数,因此也就解决了由此引起的植被指数容易饱和以及与实际植被覆盖缺乏线性关系的问题。
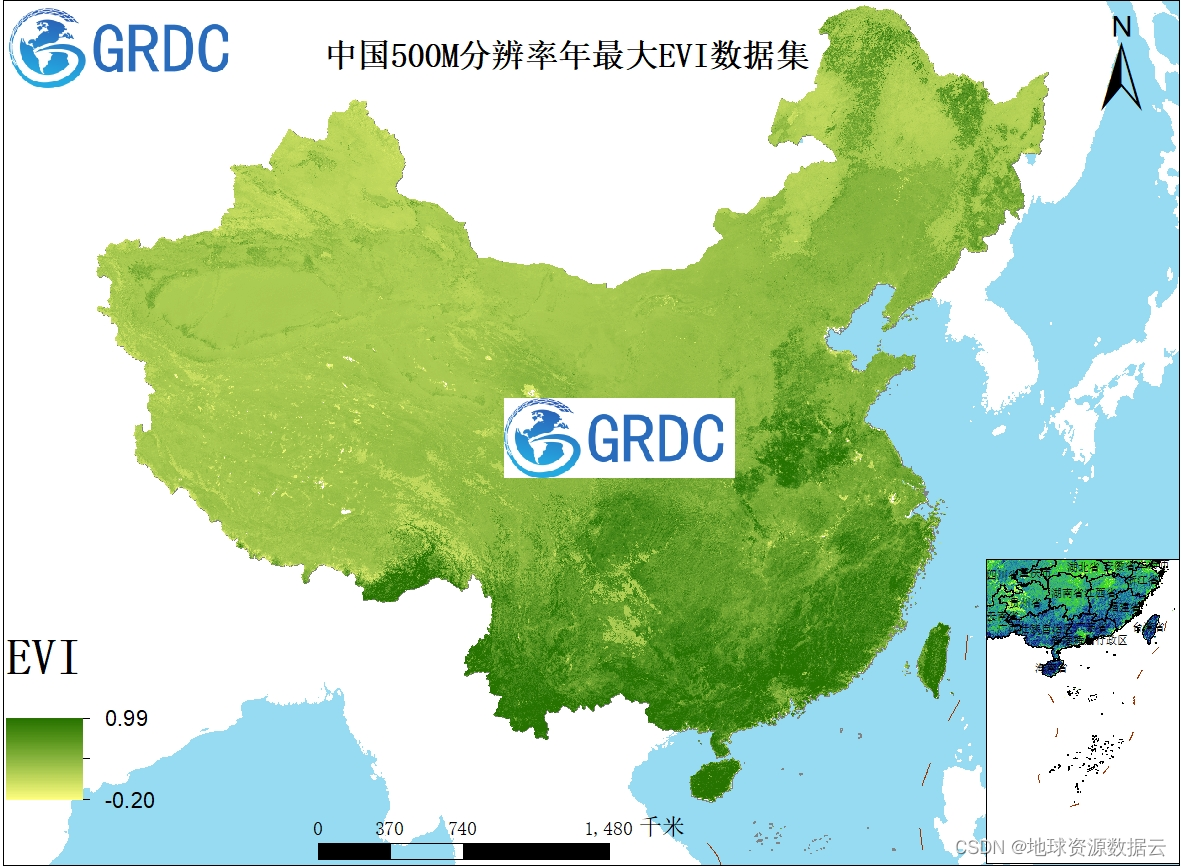
本数据集包含2000年至2023年间中国(东经112.749955°至113.225114°,北纬28.022906°至28.337638°)地区的年最大增强型植被指数(EVI)值,体现了24年间该地区植被动态的年际变化。数据源自MODIS系列遥感卫星,通过Google Earth Engine云计算平台进行处理(包括去云、云影去除)获得。本数据集以500米的空间分辨率捕捉植被的生长状态,为从长时间尺度观测植被变化提供了宝贵的数据资源。
数据类型tif栅格数据,数据类型为32位浮点型。反演增强型植被指数(EVI)计算公式为:
EVI = G *(NIR-RED)/(NIR + C1 * RED-C2 * Blue * L)
NIR、RED和Blue分别代表近红外波段、红光波段和蓝光波段的反射率。G、C1、C2和L参数分别为2.5、6、7.5和1.
EVI = 2.5 * ((NIR - RED) / (NIR + 6 * RED - 7.5 * BLUE + 1))

欢迎大家关注、收藏和留言,如果您想要什么数据,可以在搜索网址地球资源数据云,我会分享更多的好的数据给大家~~~~~
以上是关于中国500米分辨率年最大EVI数据集 详情,欢迎小伙伴们一起学习和分享。
这篇关于中国500米分辨率年最大EVI数据集的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





