本文主要是介绍LangChain-15 Manage Prompt Size 管理上下文大小,用Agent的方式询问问题,并去百科检索内容,总结后返回,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
背景描述
这一节内容比较复杂:
- 涉及到使用工具进行百科的检索(有现成的插件)
- 有
AgentExecutor来帮助我们执行 - 后续由于上下文过大, 我们通过计算
num_tokens,来控制我们的上下文
安装依赖
pip install --upgrade --quiet langchain langchain-openai wikipedia
代码编写
GPT 3.5 Turbo 解决这个问题总是出错,偶尔可以正常解决,所以这里使用了 GPT-4-Turbo,准确率基本时100%。
from operator import itemgetter
from langchain.agents import AgentExecutor, load_tools
from langchain.agents.format_scratchpad import format_to_openai_function_messages
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser
from langchain.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
from langchain_core.prompt_values import ChatPromptValue
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI# Initialize Wikipedia tool with a wrapper for querying
wiki = WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper(top_k_results=5, doc_content_chars_max=10_000)
)
tools = [wiki]prompt = ChatPromptTemplate.from_messages([("system", "You are a helpful assistant"),("user", "{input}"),MessagesPlaceholder(variable_name="agent_scratchpad"),]
)
llm = ChatOpenAI(model="gpt-4-0125-preview")agent = ({"input": itemgetter("input"),"agent_scratchpad": lambda x: format_to_openai_function_messages(x["intermediate_steps"]),}| prompt| llm.bind_functions(tools)| OpenAIFunctionsAgentOutputParser()
)agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
# agent_executor.invoke(
# {
# "input": "Who is the current US president? What's their home state? What's their home state's bird? What's that bird's scientific name?"
# }
# )agent_executor.invoke({"input": "大模型Grok是什么?作者是谁?他还干了什么?Grok是开源模型吗?如果是什么时候开源的?"}
)运行结果
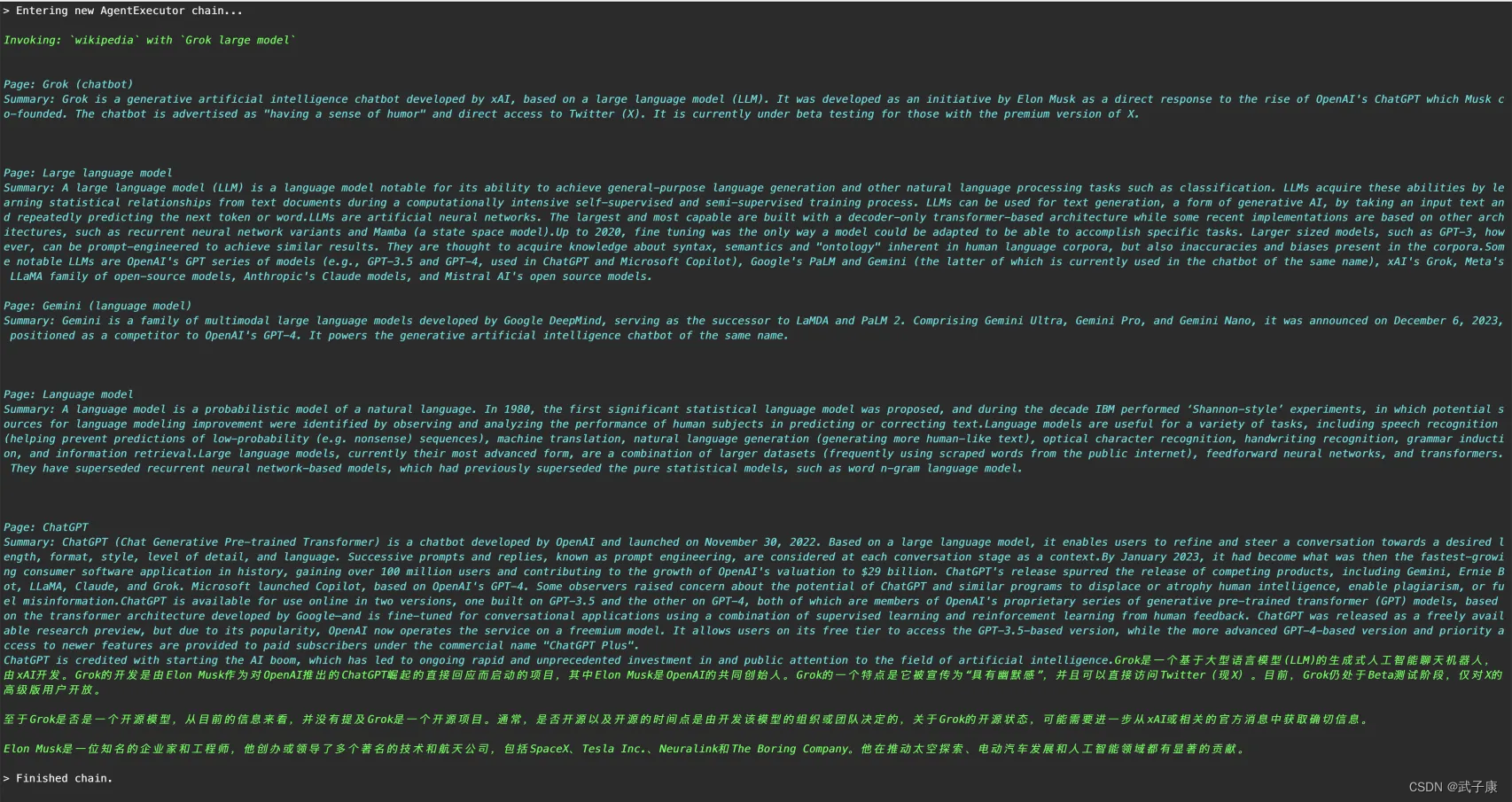
➜ python3 test15.py
/Users/wuzikang/Desktop/py/langchain_test/own_learn/env/lib/python3.12/site-packages/langchain/tools/__init__.py:63: LangChainDeprecationWarning: Importing tools from langchain is deprecated. Importing from langchain will no longer be supported as of langchain==0.2.0. Please import from langchain-community instead:`from langchain_community.tools import WikipediaQueryRun`.To install langchain-community run `pip install -U langchain-community`.warnings.warn(> Entering new AgentExecutor chain...Invoking: `wikipedia` with `Grok large model`Page: Grok (chatbot)
Summary: Grok is a generative artificial intelligence chatbot developed by xAI, based on a large language model (LLM). It was developed as an initiative by Elon Musk as a direct response to the rise of OpenAI's ChatGPT which Musk co-founded. The chatbot is advertised as "having a sense of humor" and direct access to Twitter (X). It is currently under beta testing for those with the premium version of X.Page: Large language model
Summary: A large language model (LLM) is a language model notable for its ability to achieve general-purpose language generation and other natural language processing tasks such as classification. LLMs acquire these abilities by learning statistical relationships from text documents during a computationally intensive self-supervised and semi-supervised training process. LLMs can be used for text generation, a form of generative AI, by taking an input text and repeatedly predicting the next token or word.LLMs are artificial neural networks. The largest and most capable are built with a decoder-only transformer-based architecture while some recent implementations are based on other architectures, such as recurrent neural network variants and Mamba (a state space model).Up to 2020, fine tuning was the only way a model could be adapted to be able to accomplish specific tasks. Larger sized models, such as GPT-3, however, can be prompt-engineered to achieve similar results. They are thought to acquire knowledge about syntax, semantics and "ontology" inherent in human language corpora, but also inaccuracies and biases present in the corpora.Some notable LLMs are OpenAI's GPT series of models (e.g., GPT-3.5 and GPT-4, used in ChatGPT and Microsoft Copilot), Google's PaLM and Gemini (the latter of which is currently used in the chatbot of the same name), xAI's Grok, Meta's LLaMA family of open-source models, Anthropic's Claude models, and Mistral AI's open source models.Page: Gemini (language model)
Summary: Gemini is a family of multimodal large language models developed by Google DeepMind, serving as the successor to LaMDA and PaLM 2. Comprising Gemini Ultra, Gemini Pro, and Gemini Nano, it was announced on December 6, 2023, positioned as a competitor to OpenAI's GPT-4. It powers the generative artificial intelligence chatbot of the same name.Page: Language model
Summary: A language model is a probabilistic model of a natural language. In 1980, the first significant statistical language model was proposed, and during the decade IBM performed ‘Shannon-style’ experiments, in which potential sources for language modeling improvement were identified by observing and analyzing the performance of human subjects in predicting or correcting text.Language models are useful for a variety of tasks, including speech recognition (helping prevent predictions of low-probability (e.g. nonsense) sequences), machine translation, natural language generation (generating more human-like text), optical character recognition, handwriting recognition, grammar induction, and information retrieval.Large language models, currently their most advanced form, are a combination of larger datasets (frequently using scraped words from the public internet), feedforward neural networks, and transformers. They have superseded recurrent neural network-based models, which had previously superseded the pure statistical models, such as word n-gram language model.Page: ChatGPT
Summary: ChatGPT (Chat Generative Pre-trained Transformer) is a chatbot developed by OpenAI and launched on November 30, 2022. Based on a large language model, it enables users to refine and steer a conversation towards a desired length, format, style, level of detail, and language. Successive prompts and replies, known as prompt engineering, are considered at each conversation stage as a context.By January 2023, it had become what was then the fastest-growing consumer software application in history, gaining over 100 million users and contributing to the growth of OpenAI's valuation to $29 billion. ChatGPT's release spurred the release of competing products, including Gemini, Ernie Bot, LLaMA, Claude, and Grok. Microsoft launched Copilot, based on OpenAI's GPT-4. Some observers raised concern about the potential of ChatGPT and similar programs to displace or atrophy human intelligence, enable plagiarism, or fuel misinformation.ChatGPT is available for use online in two versions, one built on GPT-3.5 and the other on GPT-4, both of which are members of OpenAI's proprietary series of generative pre-trained transformer (GPT) models, based on the transformer architecture developed by Google—and is fine-tuned for conversational applications using a combination of supervised learning and reinforcement learning from human feedback. ChatGPT was released as a freely available research preview, but due to its popularity, OpenAI now operates the service on a freemium model. It allows users on its free tier to access the GPT-3.5-based version, while the more advanced GPT-4-based version and priority access to newer features are provided to paid subscribers under the commercial name "ChatGPT Plus".
ChatGPT is credited with starting the AI boom, which has led to ongoing rapid and unprecedented investment in and public attention to the field of artificial intelligence.Grok是一个基于大型语言模型(LLM)的生成式人工智能聊天机器人,由xAI开发。Grok的开发是由Elon Musk作为对OpenAI推出的ChatGPT崛起的直接回应而启动的项目,其中Elon Musk是OpenAI的共同创始人。Grok的一个特点是它被宣传为“具有幽默感”,并且可以直接访问Twitter(现X)。目前,Grok仍处于Beta测试阶段,仅对X的高级版用户开放。至于Grok是否是一个开源模型,从目前的信息来看,并没有提及Grok是一个开源项目。通常,是否开源以及开源的时间点是由开发该模型的组织或团队决定的,关于Grok的开源状态,可能需要进一步从xAI或相关的官方消息中获取确切信息。Elon Musk是一位知名的企业家和工程师,他创办或领导了多个著名的技术和航天公司,包括SpaceX、Tesla Inc.、Neuralink和The Boring Company。他在推动太空探索、电动汽车发展和人工智能领域都有显著的贡献。> Finished chain.
可以看到 Agent 帮助我们执行总结出了结果:
Grok是一个基于大型语言模型(LLM)的生成式人工智能聊天机器人,由xAI开发。Grok的开发是由Elon Musk作为对OpenAI推出的ChatGPT崛起的直接回应而启动的项目,其中Elon Musk是OpenAI的共同创始人。Grok的一个特点是它被宣传为“具有幽默感”,并且可以直接访问Twitter(现X)。目前,Grok仍处于Beta测试阶段,仅对X的高级版用户开放。至于Grok是否是一个开源模型,从目前的信息来看,并没有提及Grok是一个开源项目。通常,是否开源以及开源的时间点是由开发该模型的组织或团队决定的,关于Grok的开源状态,可能需要进一步从xAI或相关的官方消息中获取确切信息。Elon Musk是一位知名的企业家和工程师,他创办或领导了多个著名的技术和航天公司,包括SpaceX、Tesla Inc.、Neuralink和The Boring Company。他在推动太空探索、电动汽车发展和人工智能领域都有显著的贡献。
消耗情况
由于上下文过大,资费是非常恐怖的

优化代码
我们通过定义了一个condense_prompt函数来计算和控制上下文
# 控制上下文大小
def condense_prompt(prompt: ChatPromptValue) -> ChatPromptValue:messages = prompt.to_messages()num_tokens = llm.get_num_tokens_from_messages(messages)ai_function_messages = messages[2:]# 这里限制了while num_tokens > 4_000:ai_function_messages = ai_function_messages[2:]num_tokens = llm.get_num_tokens_from_messages(messages[:2] + ai_function_messages)messages = messages[:2] + ai_function_messagesreturn ChatPromptValue(messages=messages)完整的代码如下
from operator import itemgetter
from langchain.agents import AgentExecutor, load_tools
from langchain.agents.format_scratchpad import format_to_openai_function_messages
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser
from langchain.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
from langchain_core.prompt_values import ChatPromptValue
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI# Initialize Wikipedia tool with a wrapper for querying
wiki = WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper(top_k_results=5, doc_content_chars_max=10_000)
)
tools = [wiki]prompt = ChatPromptTemplate.from_messages([("system", "You are a helpful assistant"),("user", "{input}"),MessagesPlaceholder(variable_name="agent_scratchpad"),]
)
llm = ChatOpenAI(model="gpt-4-0125-preview")# 控制上下文大小
def condense_prompt(prompt: ChatPromptValue) -> ChatPromptValue:messages = prompt.to_messages()num_tokens = llm.get_num_tokens_from_messages(messages)ai_function_messages = messages[2:]# 这里限制了while num_tokens > 4_000:ai_function_messages = ai_function_messages[2:]num_tokens = llm.get_num_tokens_from_messages(messages[:2] + ai_function_messages)messages = messages[:2] + ai_function_messagesreturn ChatPromptValue(messages=messages)# 注意在Chain中加入
agent = ({"input": itemgetter("input"),"agent_scratchpad": lambda x: format_to_openai_function_messages(x["intermediate_steps"]),}| prompt| condense_prompt| llm.bind_functions(tools)| OpenAIFunctionsAgentOutputParser()
)agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
# agent_executor.invoke(
# {
# "input": "Who is the current US president? What's their home state? What's their home state's bird? What's that bird's scientific name?"
# }
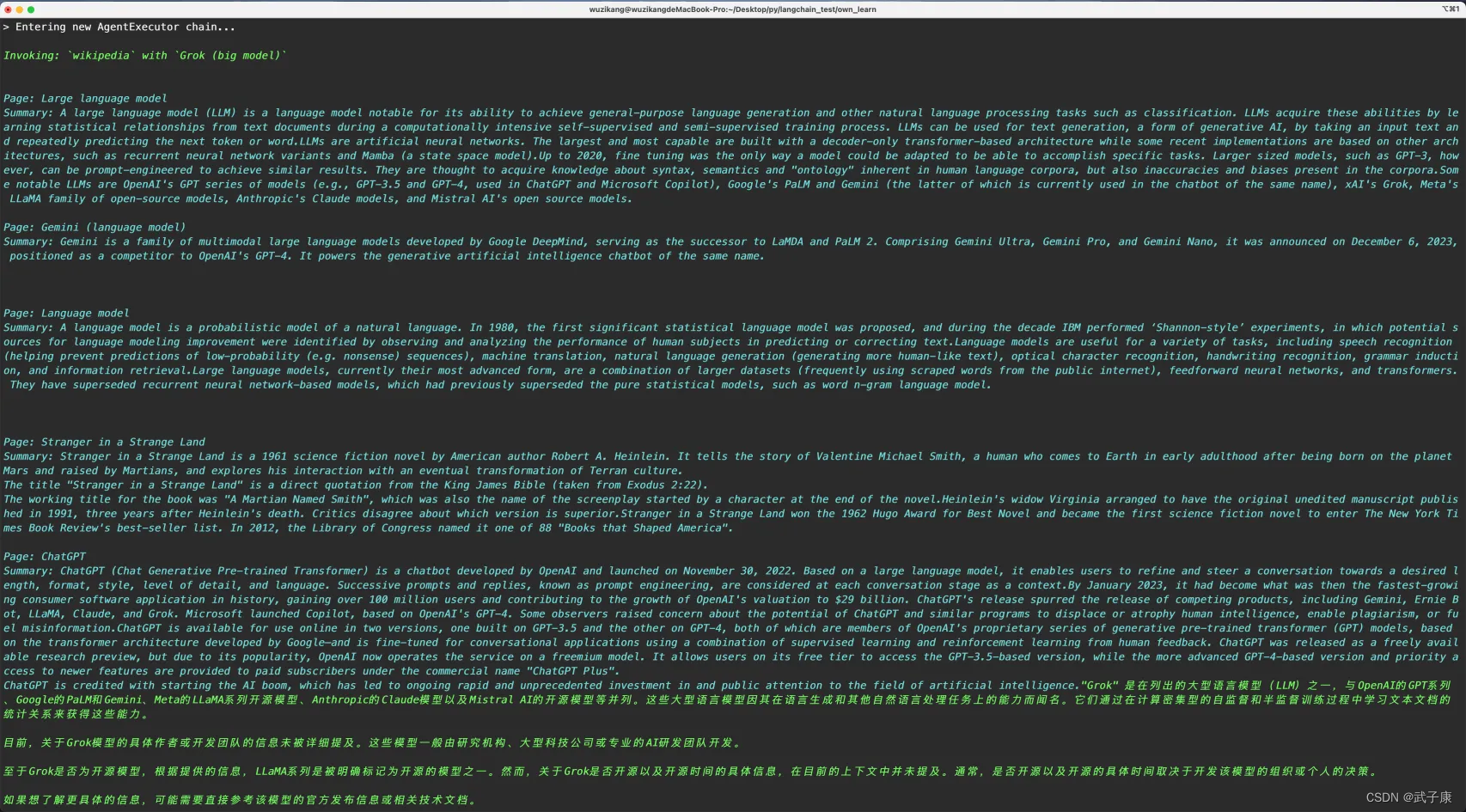
# )agent_executor.invoke({"input": "大模型Grok是什么?作者是谁?他还干了什么?Grok是开源模型吗?如果是什么时候开源的?"}
)
这篇关于LangChain-15 Manage Prompt Size 管理上下文大小,用Agent的方式询问问题,并去百科检索内容,总结后返回的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







