本文主要是介绍OSPF数据报文格式,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
OSPF协议是跨层封装的协议,跨四层封装,直接将应用层的数据封装在网络层协议后面,IP协议包中协议号字段对应的数值为——89
OSPF的头部信息:
——所有数据包公有的信息

版本:OSPF版本
在IPV4中一般使用OSPFV2,所以,版本号一般为2
类型:OSPF数据包类型
Hello —— 1
DBD —— 2
LSR —— 3
LSU —— 4
LSACK —— 5
路由器ID : 发送该数据包者的RID
区域ID:数据包被发出的区域
校验和:校验数据完整性
验证类型:OSPF认证类型
null(不认证)—— 0
simple(明文认证)—— 1
MD5(通过比对摘要值的方式进行认证)—— 2
认证数据:具体的认证数据(如果验证类型为null,则为空)
注意:OSPF在进行认证时,需要比对两部分数据:认证类型,认证数据
hello包:
——周期发现,建立和保活邻居关系,包括DR/BDR选举

网络掩码:接口激活后开始发送hello报文,这个接口配置的ip地址的掩码信息
华为设备要求,邻居之间hello包中携带的子网掩码必须相同,不同则无法建立邻居关系(只针对以太网接口进行检测,对点到点网络不做限制)
hello时间和死亡时间:邻居之间所携带的hello时间和死亡时间必须相同,不同则无法建立邻居关系
8位的可选项:每一个比特都表示路由器所携带的某种OSPF特性
——8位特殊标记中包含OSPF特殊区域的标记 ,这个特殊区域的标记在邻居建立中也需要检测,如果不同,则无法建立邻居关系
路由器的优先级:发出接口DR/BDR选举时的优先级
指定路由器和备份指定路由器:在DR/BDR选举完成后,将会把DR/BDR的IP信息携带在该字段。在 DR/BDR未选出之前,将以0.0.0.0来填充
邻居:本地已知的邻居ID(这是建立邻居关系的重要条件)
hello包中限制邻居关系建立的条件:
1、网络掩码(只针对以太网接口)
2、hello时间
3、dead time
4、ospf特殊区域标记
5、认证
DBD包
—— 数据库描述报文
注意:主从关系选举的作用:
1、为主可以优先进行LSA信息的交换;
2、为主的可以主导DBD包的隐性确认

接口最大传输单元(MTU):默认为0——华为设备默认未开启MTU值检测功能
注意:如果邻居的该字段不一致,则会停留在exstart状态
I (init)—— 该位为一,则代表该DBD是在进行主从关系选举的数据包
M (more) —— 该位为一,则代表后续还有更多的数据包,该位为0,则代表这个DBD包是最后一个DBD包
MS (master)——该位为一,则代表发送DBD包设备为主
在主从关系未选举出时,邻居双方都会将自己的MS位为1,认为自己是主,选举完成后,只有主置1
DBD的序列号 —— 在DBD报文交互过程中,会逐次加一,用于确保BDB报文传输的有序性和可靠性
隐性确认:DBD包的确认机制是通过序列号实现
—— 隐性确认:为主的设备发送一个DBD包,其中包含一个序列号,”从“收到这个数据包后将使用相同的序列号回复DBD包,起到确认的作用
显性确认:通过LSACK数据包实现确认
LSA 头部信息 —— 不是完整的LSA信息,是LSA信息的摘要
LSR包
—— 链路状态请求报文(基于DBD包中的摘要信息,和本地的LSDB进行比对,之后要求未知的LSA信息)
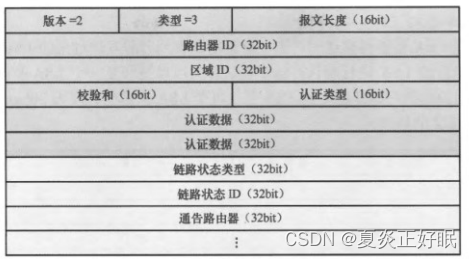
链路状态类型,链路状态ID,通告路由器
——LSA的三元组(可唯一标识一条LSA)
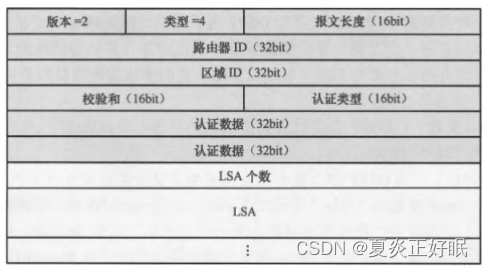
LSU
——链路状态更新报文(携带LSA信息的数据包)
LSACK
——链路状态确认报文

通过LSA头部内容进行确认
这篇关于OSPF数据报文格式的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





