本文主要是介绍Python计算多个表格中多列数据的平均值与标准差并导出为新的Excel文件,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文介绍基于Python语言,对一个或多个表格文件中多列数据分别计算平均值与标准差,随后将多列数据对应的这2个数据结果导出为新的表格文件的方法。
首先,来看一下本文的需求。现有2个.csv格式的表格文件,其每1列表示1个变量,每1行则表示1个样本;其中1个表格文件如下图所示。
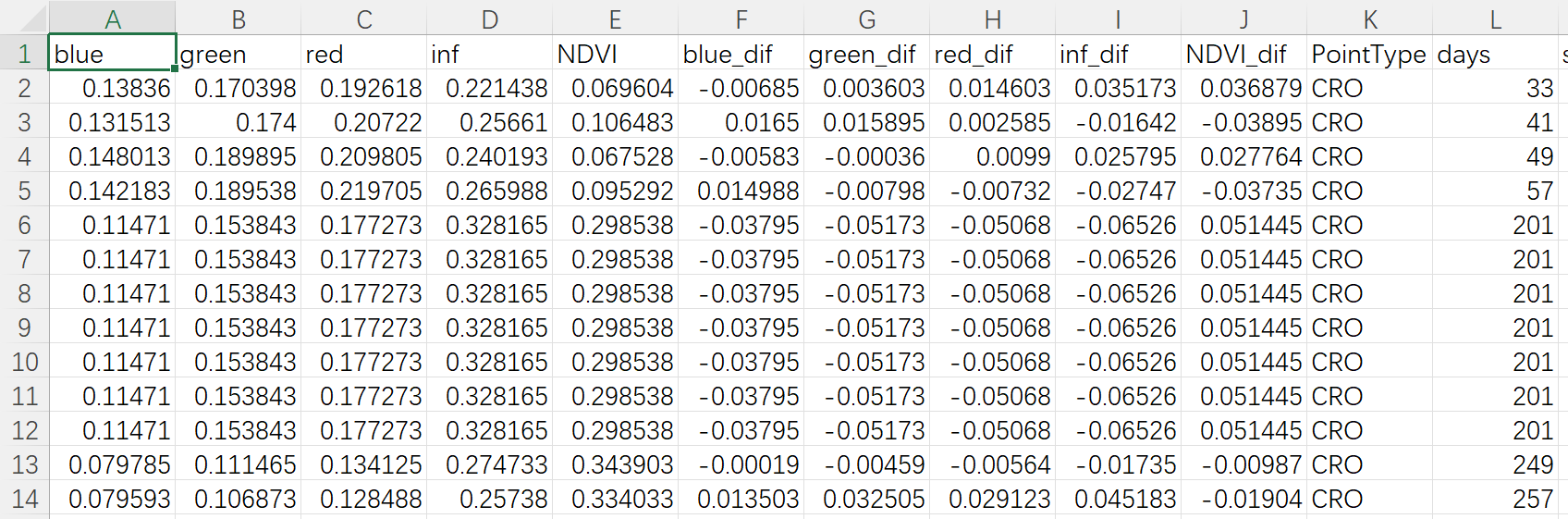
我们现在需要分别对这2个表格文件执行如下操作:计算出其中部分变量(部分列)在所有样本(所有行)中的平均值与标准差数据,然后将这些数据结果导出到一个新的.csv格式文件中。
需求也很简单。明确了需求,接下来就可以开始代码的撰写;本文所用代码如下。
# -*- coding: utf-8 -*-
"""
Created on Sun Mar 10 17:59:23 2024@author: fkxxgis
"""import pandas as pddata = pd.read_csv(r"F:\Data_Reflectance_Rec\Train_data\Train_Model_0715_Main_Over_B_New.csv")
data_nir = pd.read_csv(r"F:\Data_Reflectance_Rec\Train_data\Train_Model_0715_Main_Over_NIR_New.csv")column_need = ["blue", "green", "red", "inf", "NDVI", "NDVI_dif", "days", "sola", "temp", "prec", "soil", "blue_h", "green_h", "red_h", "inf_h", "ndvi_h", "blue_h_dif", "green_h_dif", "red_h_dif", "inf_h_dif", "ndvi_h_dif"]mean_value = data[column_need].mean()
std_value = data[column_need].std()
mean_value_nir = data_nir[column_need].mean()
std_value_nir = data_nir[column_need].std()data_new = pd.DataFrame({"mean_RGB": mean_value, "std_RGB": std_value, "mean_NIR": mean_value_nir, "std_NIR": std_value_nir})data_new.to_csv(r"F:\Data_Reflectance_Rec\Train_data\mean_std.csv", index = True)
上述代码具体含义如下。
首先,使用pandas库导入了pd模块。
其次,使用pd.read_csv()函数从2个.csv格式表格文件中读取数据。其中,因为本文需要读取的是2个文件,所以分别用data变量与data_nir变量读取这2个不同路径的表格文件。
接下来,定义了一个column_need列表,其中包含了需要计算平均值和标准差的列名。
随后,使用mean()函数和std()函数分别计算了data和data_nir中指定列的平均值和标准差,并将结果分别赋值给mean_value、std_value、mean_value_nir和std_value_nir变量。
然后,使用pd.DataFrame创建了一个新的数据框data_new,其中包含了4列数据:mean_RGB列存储了data中计算得到的平均值,std_RGB列存储了data中计算得到的的标准差;mean_NIR列存储了data_nir中计算得到的平均值,std_NIR列存储了data_nir中计算得到的标准差。
最后,使用to_csv()函数将data_new保存到文件路径为mean_std.csv的.csv格式文件中,设置index=True表示将索引列也保存到文件中。
运行上述代码,即可在结果文件夹中找到对应的结果.csv格式文件;如下图所示,其已经是我们需要的形式了——每1列表示1种对应的结果,每1行表示1种变量。
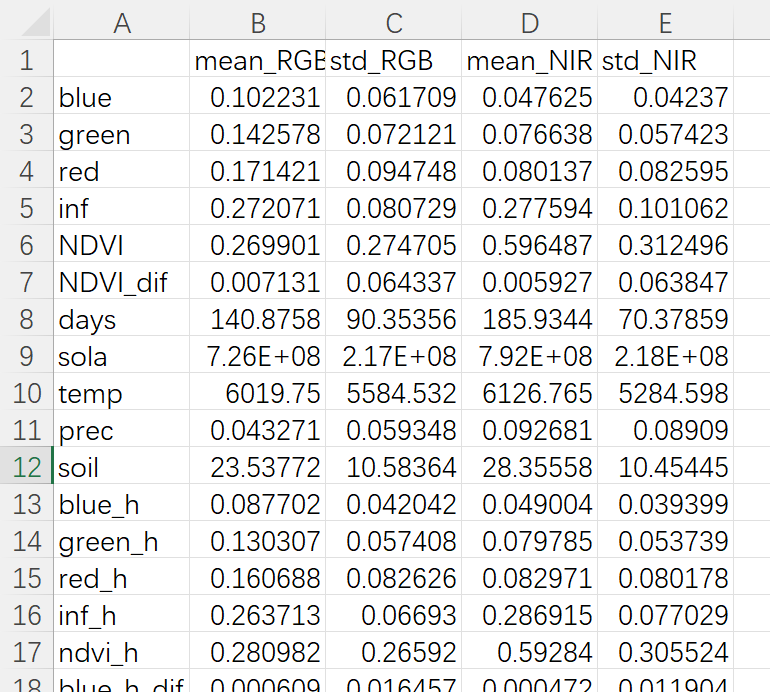
至此,大功告成。
欢迎关注:疯狂学习GIS
这篇关于Python计算多个表格中多列数据的平均值与标准差并导出为新的Excel文件的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




