本文主要是介绍conda创建虚拟环境太慢,Collecting package metadata (current_repodata.json): failed,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
(省流版:只看加粗红色,末尾也有哦)
平时不怎么用conda,在前公司用服务器的时候用的是公司的conda源,在自己电脑上直接用python创建虚拟环境完事儿,所以对conda的配置并不熟悉~~【狗头】。但是python虚拟环境的最大缺点自然是只能用一个python版本,多版本的时候就不方便。
接下主要是解决conda创建虚拟环境慢的问题,如果配置的不专业请指点!
如果直接用conda国外的源,那肯定会慢,所以切国内源,之前我也是这么做的,但仍然非常慢。当时用的就是清华源。
直接修改conda配置文件:C:\Users\<YourUserName>\.condarc
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud- Windows 用户无法直接创建名为
.condarc的文件,可先执行conda config --set show_channel_urls yes生成该文件之后再修改。
接下来试一下,执行:
conda create -n internlm python==3.10 -y
过了N久,失败了
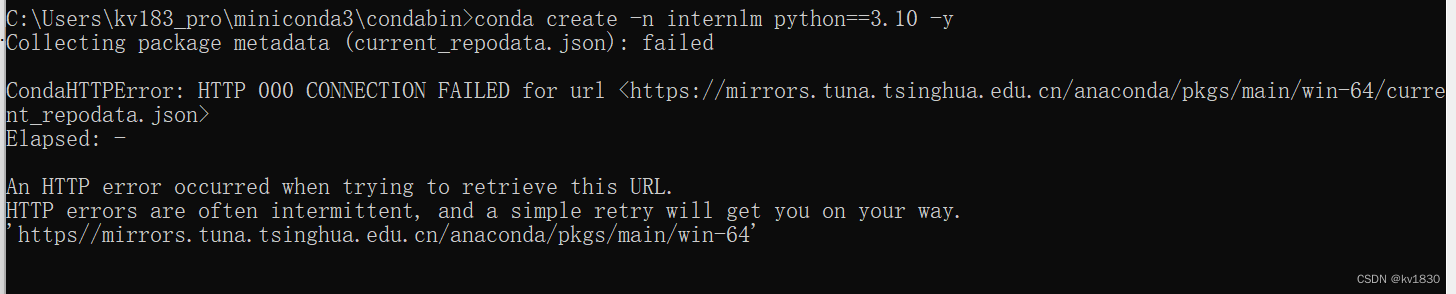
我特意在浏览器里去下载了一下:
https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/win-64/current_repodata.json
这个文件也就6M多,但下载的灰常慢。有可能如果延长一下超时时间啥的,也可以继续安装。但我想找个更快的方式,有可能清华源用的人太多了,所以慢?
故去搜索了一下,有人说用中科大源(https://mirrors.ustc.edu.cn)
那就直接全替换一下?
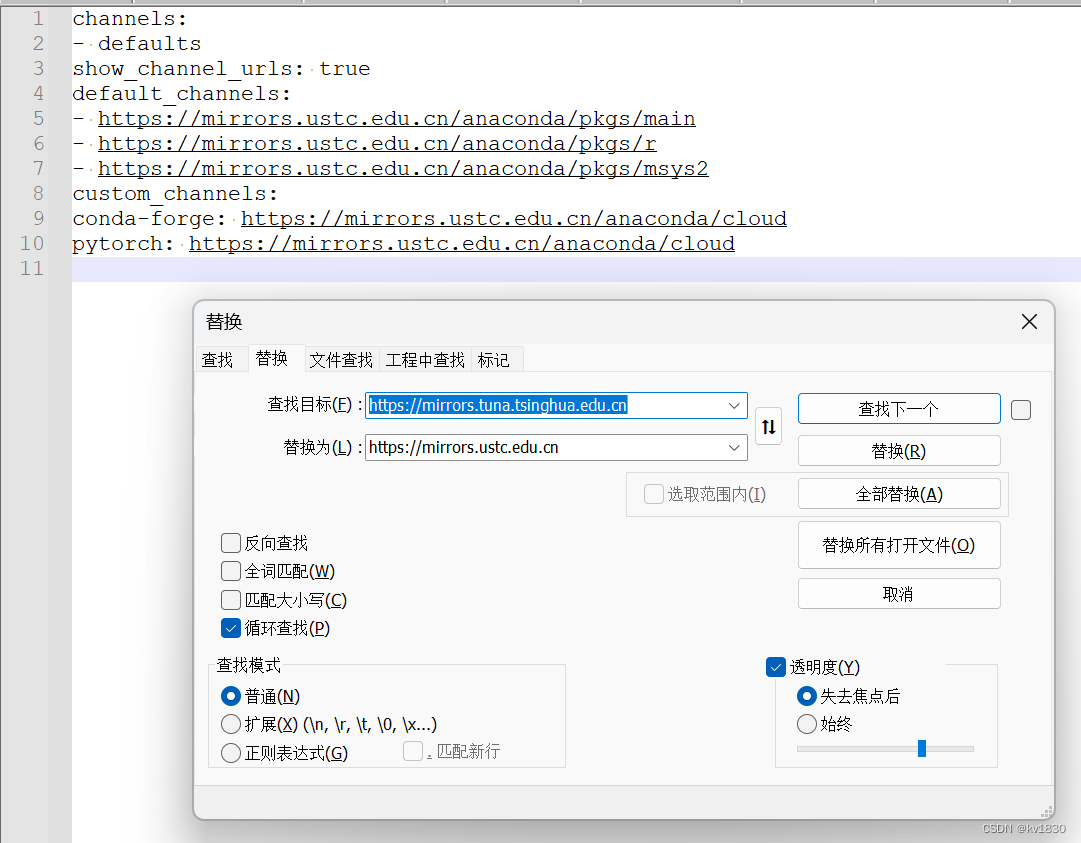
这些链接也确实都能访问,再试一下,结果说不可访问或者无效。
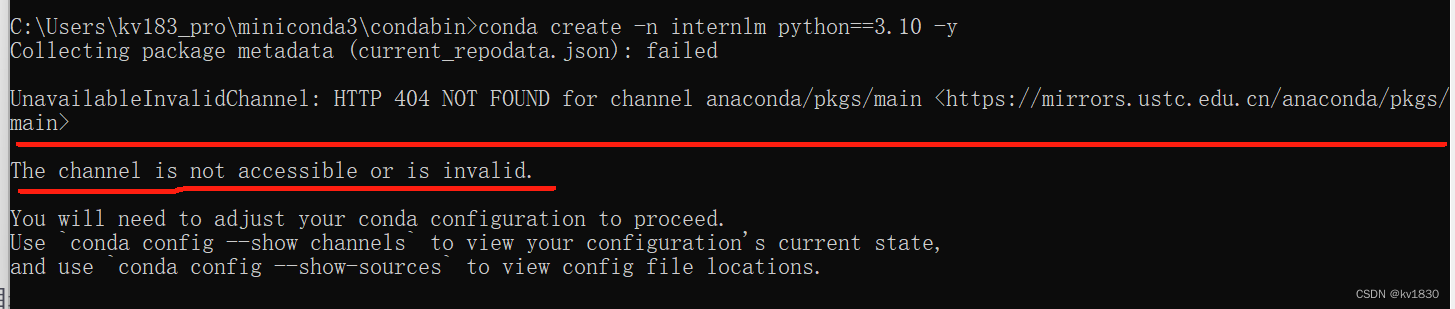
故直接用浏览器访问一下:
https://mirrors.ustc.edu.cn/anaconda/pkgs/main
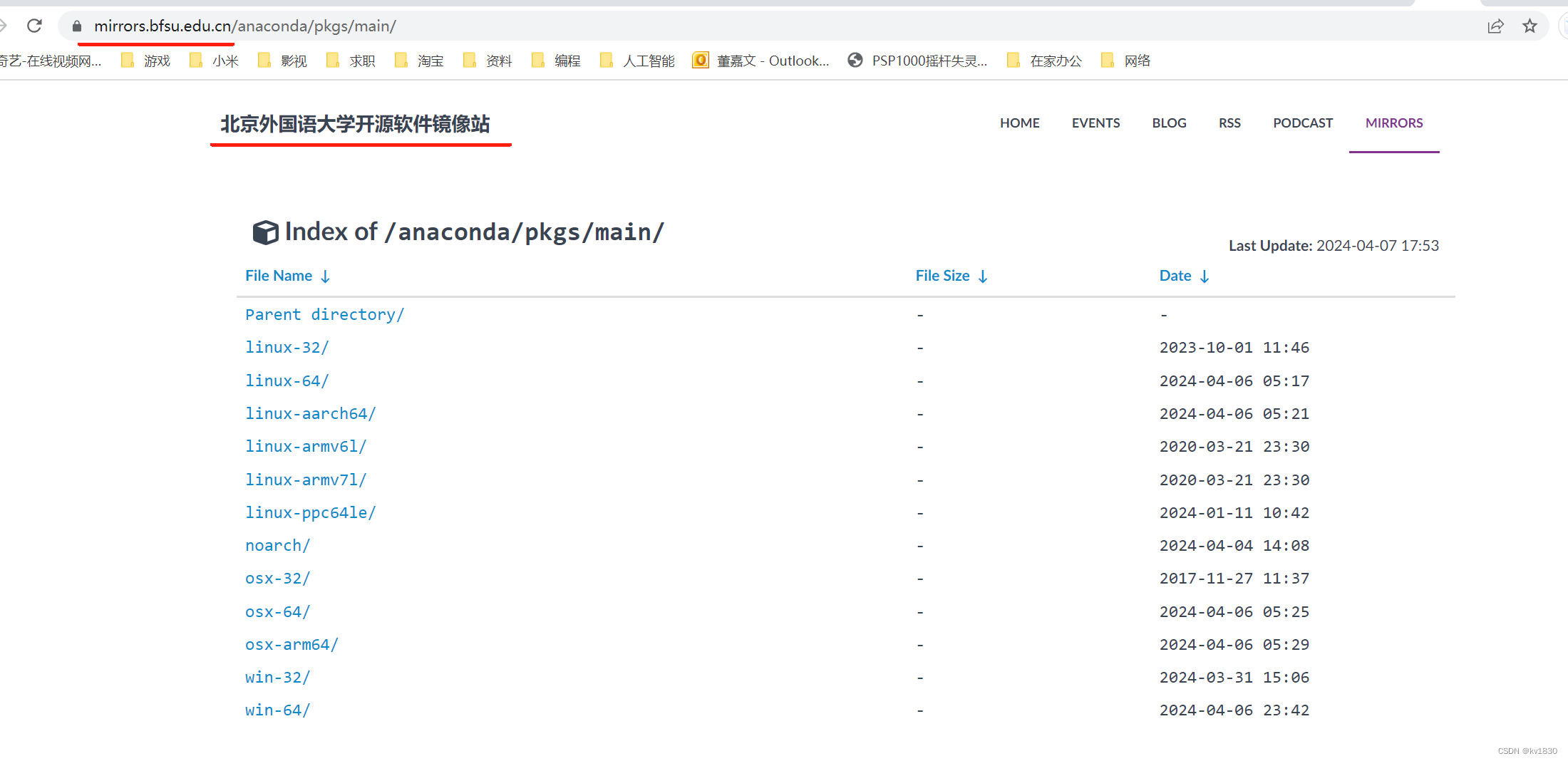
能访问啊,但你会发现域名变了,自动变成北京外国语大学的镜像站了。有可能是中科大并没有conda源,所以给你重定向了一下。难道conda里面不允许这样?配置的源的域名不允许变?
那干脆直接改成北京外国语大学的吧。
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.bfsu.edu.cn/anaconda/pkgs/main
- https://mirrors.bfsu.edu.cn/anaconda/pkgs/r
- https://mirrors.bfsu.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.bfsu.edu.cn/anaconda/cloud
pytorch: https://mirrors.bfsu.edu.cn/anaconda/cloud
再一试,快到飞起,立马就创建好了!
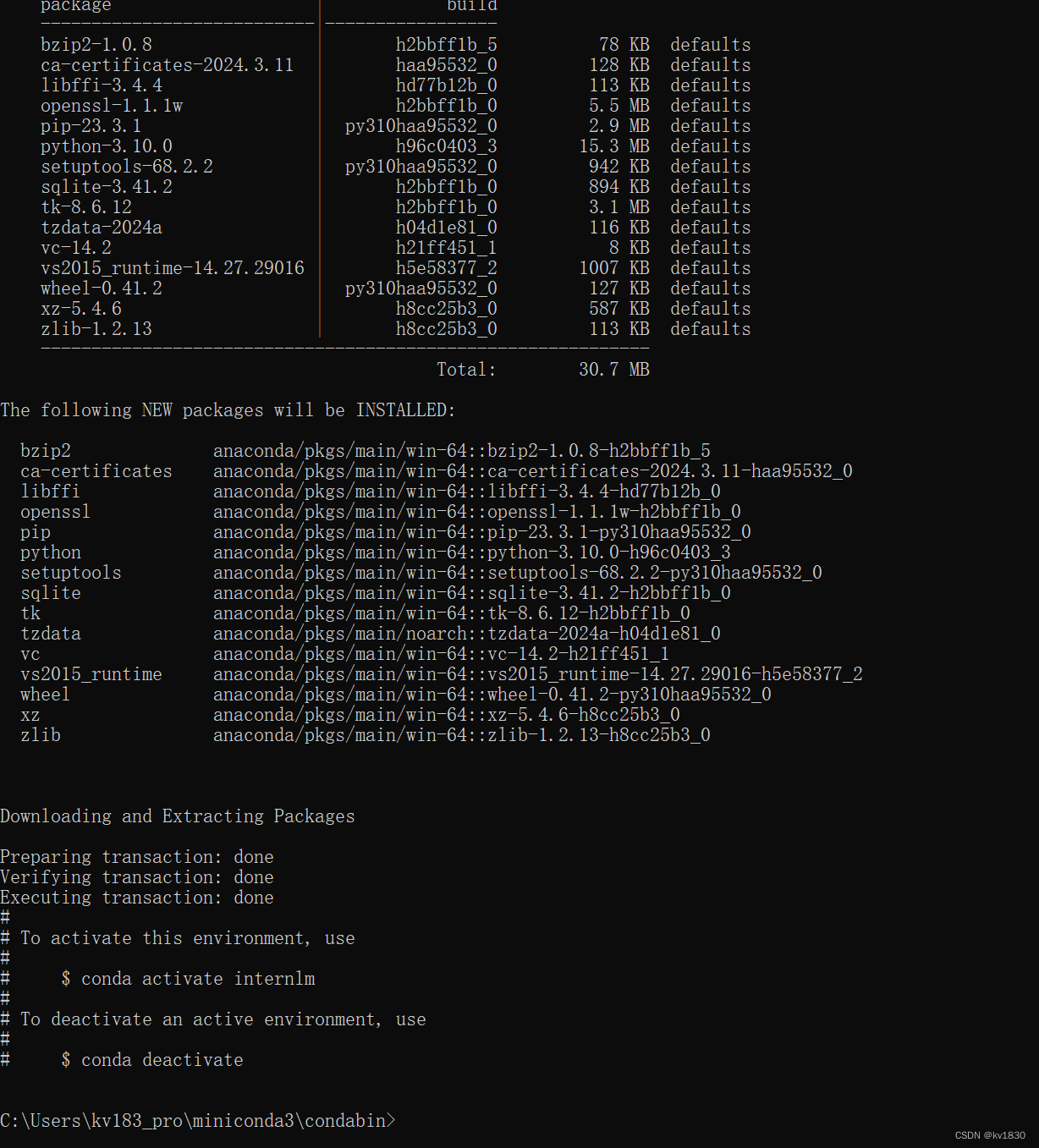
这篇关于conda创建虚拟环境太慢,Collecting package metadata (current_repodata.json): failed的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





