本文主要是介绍【鲜货】企业数据治理的首要一步:数据溯源,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
背景
一、数据探索溯源的定义
二、数据探索溯源的重要性
1、提高数据质量
2、增强数据信任度
3、促进数据合规性
三、数据溯源的主要方法
1、标注法
2、反向查询法
3、双向指针追踪法
四、数据探索溯源的主要步骤
1、确定溯源目标
2、收集元数据
3、分析数据流向
4、验证数据准确性
5、记录溯源结果
五、数据探索溯源的工具和技术
六、数据溯源的应用技巧
1、数据标签
2、数据加密
3、威胁情报平台
4、逆向分析和网络行为分析
5、同源分析、家族溯源、作者溯源
六、数据探索溯源的挑战与应对
背景
数据探索溯源是企业开展数据治理的关键第一步,其目的在于理解和追踪数据的来源、演变过程以及与其他数据的关系。通过数据探索溯源,我们可以确保数据的准确性、完整性和可靠性,为后续的数据分析和决策提供坚实的基础。
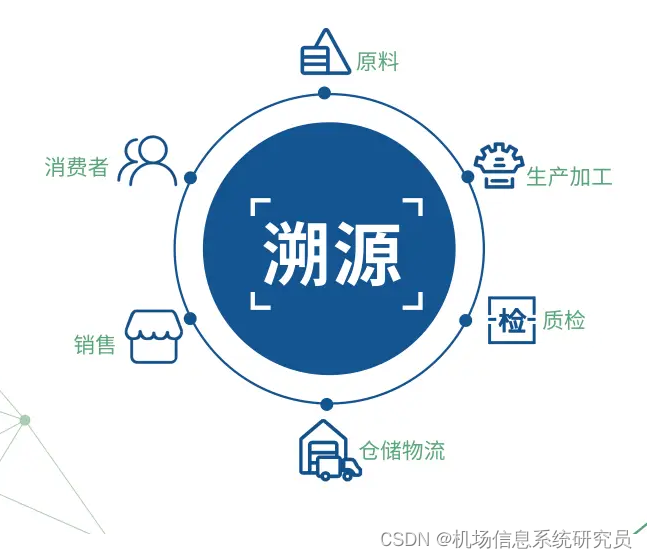
一、数据探索溯源的定义
数据探索溯源,简单来说,就是对数据从产生到使用的全过程进行追溯和了解,数据溯源核心思想是追踪数据的历史变化,以便理解数据的来源、演化过程以及可能发生的风险。这包括数据的来源、采集方式、处理过程、存储位置以及如何使用等各个方面。通过数据探索溯源,我们可以对数据有一个全面的认识,为后续的数据治理工作提供重要依据。
二、数据探索溯源的重要性
1、提高数据质量
通过溯源,我们可以发现数据中存在的问题,如数据缺失、错误或不一致等,从而进行针对性的改进,提高数据质量。
2、增强数据信任度
了解数据的来源和演变过程,可以让我们对数据更加信任,减少因数据问题导致的决策失误。
3、促进数据合规性
在数据法规日益严格的背景下,通过数据探索溯源,我们可以确保数据的合规性,避免违反相关法律法规。
三、数据溯源的主要方法
数据溯源的主要方法有标注法、反向查询法和双向指针追踪法。
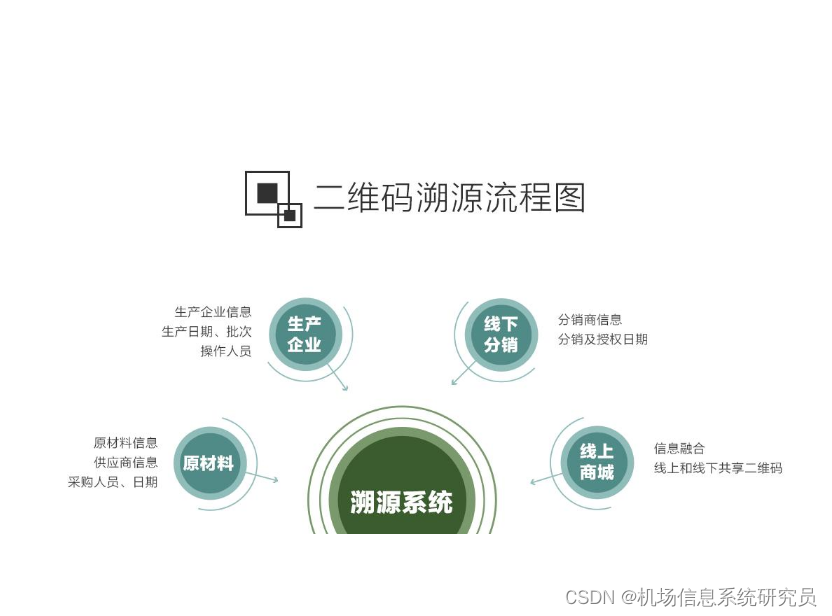
1、标注法
通常涉及在数据源中添加特定的标识符或标记,以便在后续 的数据处理过程中跟踪数据的来源和流动。这种方法的优点是简单易行,缺点 是会引入额外的复杂性和开销。
2、反向查询法
依赖于在数据处理过程中保留的元数据或审计信息,以 便在需要时回溯到数据源。这种方法的优点是可以提供更细粒度的跟踪能力, 缺点是需要更多的存储空间和处理资源。
3、双向指针追踪法
适用于特定的数据库中,其基本思想是使用两个指 针,一个指针用于向前追踪,另一个指针用于向后追踪,通过比较两个指针的 值来确定数据的起源和流向。在实际应用中,双向指针追踪法通常与其他方法 结合使用,以提高追踪的准确性和效率。
四、数据探索溯源的主要步骤
1、确定溯源目标
明确需要溯源的数据范围和目标,例如某个具体的数据集或某个业务流程中的数据。
2、收集元数据
元数据是关于数据的数据,包括数据的描述、结构、来源等信息。通过收集元数据,我们可以初步了解数据的概况。
3、分析数据流向
通过查看数据的流动路径,了解数据在不同系统、应用或部门之间的传递和转换过程。
4、验证数据准确性
通过对比不同来源的数据或采用其他验证方法,确保数据的准确性和可靠性。
5、记录溯源结果
将溯源过程中的发现、分析和验证结果记录下来,形成完整的溯源报告,为后续的数据治理工作提供参考。
五、数据探索溯源的工具和技术
在数据探索溯源过程中,我们可以借助一些工具和技术来提高效率。例如,使用数据管理工具来管理元数据,通过数据可视化技术来展示数据流向,利用数据分析工具进行数据挖掘和验证等。
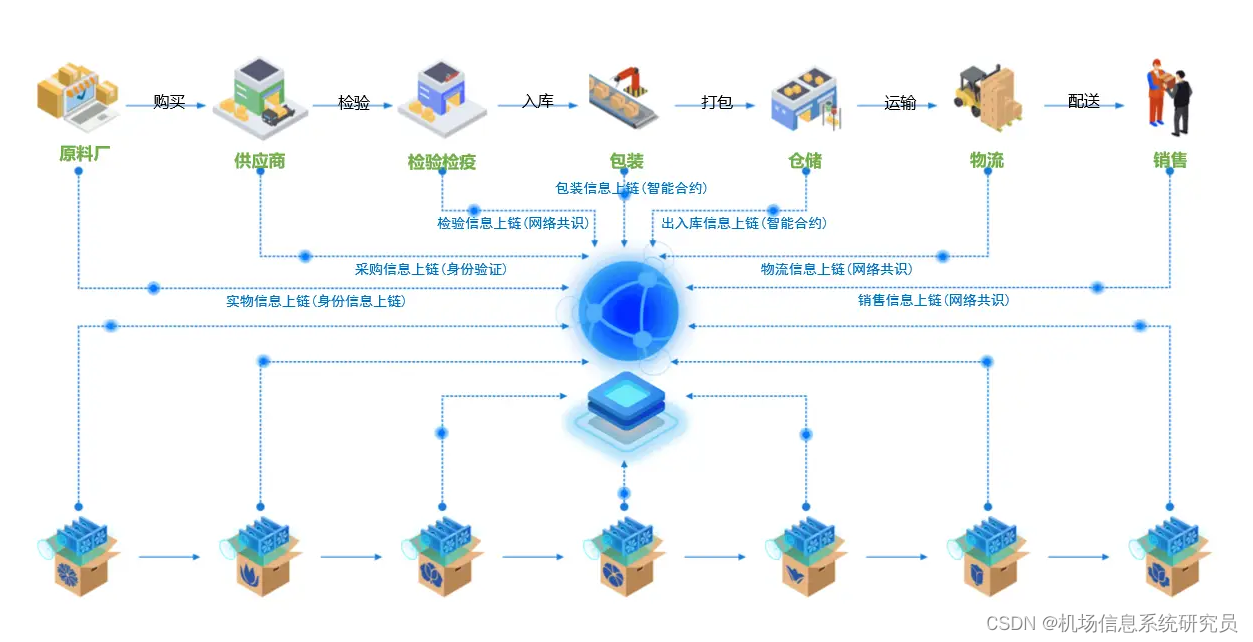
六、数据溯源的应用技巧
1、数据标签
在数据处理过程中,可以对数据进行标签,方便后续的数 据溯源。
2、数据加密
在数据传输和存储过程中,对数据进行加密处理,可以防止数据被篡改或窃取,从而保护数据的完整性和安全性。
3、威胁情报平台
获取到更多的溯源信息,如攻击者的 IP 地址、地理 位置、社交账号信息等。
4、逆向分析和网络行为分析
在对恶意样本分析过程中通常需要关注: 恶意样本中是谁发动攻击、攻击的目的是什么、恶意样本的作者是谁、采用了 哪些攻击技术、攻击的实现流程是怎样的。
5、同源分析、家族溯源、作者溯源
针对恶意样本的溯源分析可以从同 源分析、家族溯源、作者溯源这三方面作为突破点进行分析。
六、数据探索溯源的挑战与应对
尽管数据探索溯源对数据治理具有重要意义,但在实际操作中也会面临一些挑战。例如,数据来源众多、数据格式复杂多样、数据隐私和安全问题等。为了应对这些挑战,我们需要加强数据治理的顶层设计,建立统一的数据管理规范,采用先进的技术手段保障数据安全和隐私,同时加强跨部门、跨领域的合作与沟通。
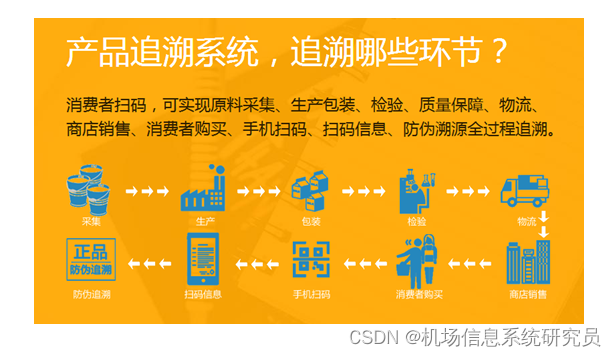
总之,数据探索溯源是数据治理的关键环节之一,通过对其进行深入了解和有效实施,我们可以为数据治理工作奠定坚实的基础,推动数据质量的提升和数据价值的发挥。
这篇关于【鲜货】企业数据治理的首要一步:数据溯源的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



