本文主要是介绍基于遗传优化的SVD水印嵌入提取算法matlab仿真,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1.程序功能描述
2.测试软件版本以及运行结果展示
3.核心程序
4.本算法原理
5.完整程序
1.程序功能描述
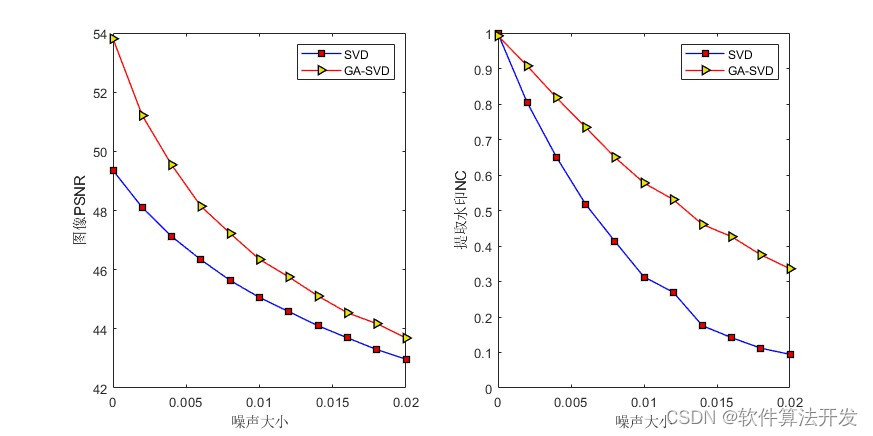
基于遗传优化的的SVD水印嵌入提取算法。对比遗传优化前后SVD水印提取性能,并分析不同干扰情况下水印提取效果。
2.测试软件版本以及运行结果展示
MATLAB2022a版本运行
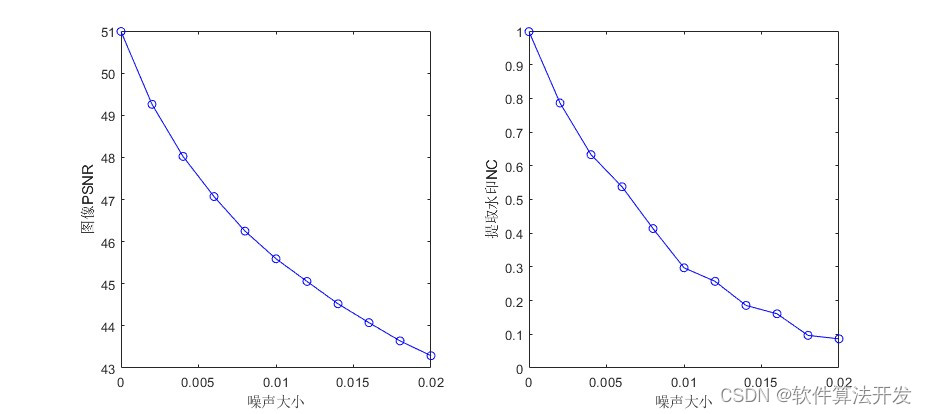
SVD

GA优化SVD

性能对比:

3.核心程序
....................................................................
% 遍历遗传算法返回的各代最优个体(从第二个开始,跳过第一个)
for i = 2:npop% 使用当前个体对应的步长参数进行SVD嵌入水印step_size = a(i);Wimg = func_svd_embeded(I0, Iwat, step_size);% 计算插入水印后图像的峰值信噪比(PEAKSNR)[m, n] = size(I0);error = I0 - Iatt;MSE = (sum(sum(error .^ 2))) / (m * n);if (MSE > 0)peaksnr = 10 * log10(255^2 / MSE);elsepeaksnr = 99;end% 从攻击后图像中提取水印wimg = func_svd_extract(Iatt, step_size);% 存储原始水印图像,用于后续计算归一化相关系数orig_Iwat = Iwat;% 计算归一化相关系数(NC)作为目标函数值norm_cor = corr2(orig_Iwat, wimg);% 计算目标函数值(归一化相关系数)obfunc = norm_cor;% 更新最大目标函数值、最佳步长、PEAKSNR和NC,以及最终图像if (obfunc > max)max = obfunc;step = step_size;peaksnr_value = peaksnr;NC = norm_cor;final_image = Iatt; % 存储最佳攻击后图像end
end
[peaksnr_value,NC]
peaksnr2(ij,kk) = peaksnr_value;
norm_cor2(ij,kk) = NC;
end
endfigure;
subplot(121);
plot(NB,mean(peaksnr2,2),'b-o');
xlabel('噪声大小');
ylabel('图像PSNR');subplot(122);
plot(NB,mean(norm_cor2,2),'b-o');
xlabel('噪声大小');
ylabel('提取水印NC');save R2.mat NB peaksnr2 norm_cor2
37
4.本算法原理
遗传优化是一种基于自然选择和遗传机制的全局优化算法,其在图像水印嵌入与提取领域中有着广泛应用。特别是在SVD( Singular Value Decomposition,奇异值分解)水印算法中,遗传优化能有效地寻找到最佳的水印嵌入参数,以提高水印的鲁棒性和隐蔽性。
SVD水印嵌入:给定一幅待嵌入水印的宿主图像 I,通过奇异值分解将其分解为 I=UΣVT。在选定的奇异值子集上添加水印信息(通常以量化形式表示),然后重构图像得到嵌入水印后的图像 Iw=U(Σ+W)VT,其中 W 为水印信息在奇异值上的映射。
遗传优化:以种群(一组候选解)为基础,通过模拟自然选择、交叉和变异等生物进化过程,逐步优化水印嵌入参数(如嵌入层选择、量化步长、水印强度等),以最大化水印的鲁棒性或隐蔽性。

遗传算法流程
-
初始化:设置遗传算法参数(种群大小、迭代次数、交叉概率、变异概率等),随机生成初始种群,每个个体代表一组水印嵌入参数。
-
适应度评估:计算种群中每个个体的鲁棒性得分FR(θ) 和隐蔽性得分 FH(θ),根据实际需求选择合适的评价指标(如加权和、折衷函数等)。
-
选择:根据适应度得分进行选择操作,保留优秀个体进入下一代种群,常用的策略有轮盘赌选择、tournament选择等。
-
交叉:对选定的个体进行交叉操作,生成新的子代个体。常见的交叉方法有单点交叉、两点交叉、均匀交叉等。
-
变异:以一定概率对子代个体的某些参数进行变异,打破遗传过程中的局部最优,增加种群多样性。常用变异操作包括二进制变异、实数域均匀变异、高斯变异等。
-
更新:将交叉和变异产生的子代个体加入下一代种群,替换掉被淘汰的个体。
-
迭代:若达到最大迭代次数或收敛条件满足,则停止;否则,返回步骤2继续下一轮迭代。
-
最优解选取:从最终种群中选择适应度最高的个体作为最佳水印嵌入参数。
5.完整程序
VVV
这篇关于基于遗传优化的SVD水印嵌入提取算法matlab仿真的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



