本文主要是介绍循序渐进丨MogDB Ustore存储引擎剖析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
背景
MogDB 数据库支持不同的存储引擎,其中行存引擎有Astore和Ustore,目前大部分客户场景使用的是Astore,也就是 Append Update(追加更新)模式。
Astore对于业务中的增、删以及HOT Update(即同一页面内更新)有很好的性能表现,但对于跨数据页面的非HOT UPDATE场景,存在历史数据回收不够高效的问题。
造成这一问题的主要原因是Astore中将新旧版本元组集中存储,在进行老数据回收时需要遍历所有数据页面;同时在执行更新操作时后,数据空间中存在一条元组的多个版本,频繁的更新操作会导致页表中存在大量的历史版本,造成数据空间的膨胀。虽然VACUUM机制可以进行一定的空间回收,但是并不能彻底解决表空间的膨胀问题,在元组中会形成很多的碎片空洞,此时只能通过VACUUM FULL进行表的重建,但是VACUUM FULL会阻塞业务,并且带来很高的IO负担。空间膨胀问题,进一步会导致数据库的增删改查性能出现不同程度的下降;数据可见性的判断需要从旧往新遍历版本链,也会造成读操作的时延增加。
Ustore设计方案
Ustore的设计是为了解决Astore中数据空间膨胀及空间膨胀引起的性能问题。Ustore中采用新旧版本分离存储的方式,将最新版本的“有效数据”存储在数据页面上,并单独开辟一段UNDO空间,用于统一管理历史版本的“垃圾数据”。因此Ustore中数据空间不会由于频繁更新而膨胀,同时历史版本“垃圾数据”集中管理,回收效率更高。
为了进一步提升性能,Ustore存储引擎采用NUMA-aware的UNDO子系统设计,使得UNDO子系统可以在多核平台上有效扩展;同时索引使用多版本技术,解决索引清理问题,有效提升了存储空间的回收和复用效率。
Ustore存储引擎结合UNDO空间,还可以实现更高效、更全面的闪回查询和回收站机制,实现快速回退“误操作”,为 MogDB 提供了更丰富和人性化的企业级功能。
01
空间结构
Ustore与Astore相同,磁盘存储结构也使用8KB页面,区别在于Ustore页面中仅存储最新版本数据,旧版本数据通过版本链集中存储在Undo段中。Ustore页面的结构如图1所示,包括页头、事务目录、元组指针区、元组区和Special Area。与Astore类似,元组指针从前往后插入,元组从后往前插入,在中间形成一段空闲空间,以供后续插入元组和元组指针使用。
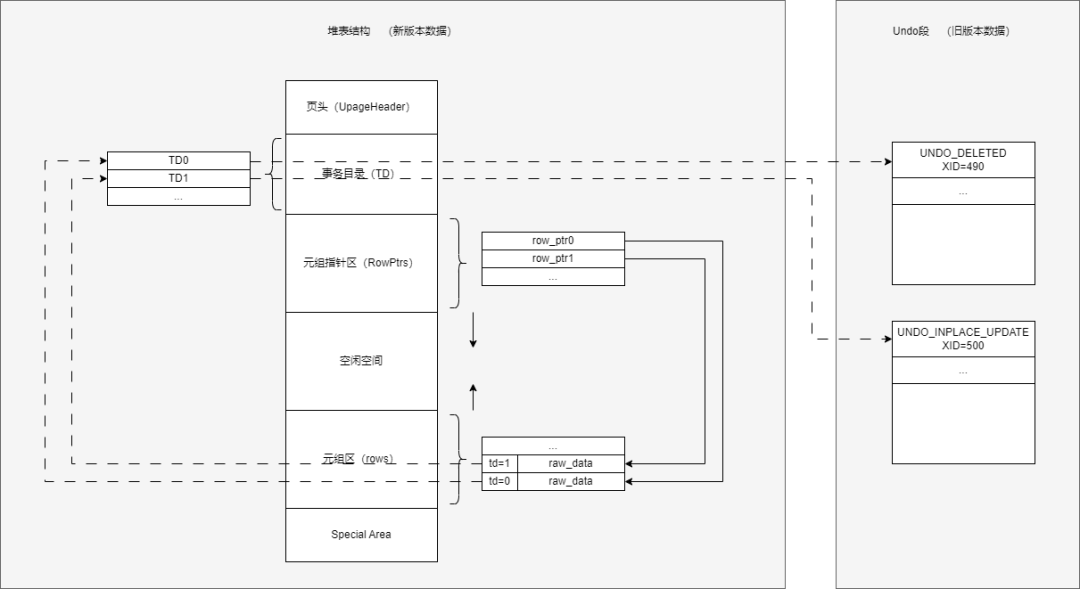
图1 Ustore的页面结构
Ustore的页面结构相比Astore新增了事务目录(TD)。它可以为数据页上的元组(tuple)链接相应的事务表(Transaction Table)及UNDO子系统中的UNDO页面。数据库中的每个表可以自定义事务目录的数量,并且可以复用那些已经完成的事务所占用的事务目录。
每个数据页默认有4个事务目录,根据并发需求的不同,事务目录的数量可设置为2~128的任意值。在使用CREATE TABLE命令创建使用Ustore存储引擎的表时添加了一个新的选项INIT_TD,用于指定所需的事务目录数量。命令示例如下:
CREATE TABLE t1
(c1 integer;c2 boolen;
) WITH (INIT_TD=16);02
原地更新
Astore中更新一个元组时新旧元组会混杂排列在堆表中,历史版本链是从旧到新。而Ustore在空间允许的情况下会尽可能进行原地更新操作,如图2所示。Ustore原地更新操作会将旧版本数据保存至UNDO空间中,堆表中始终存放最新版本的数据,数据版本按照最新到最旧的方式进行链接。

图2 Ustore原地更新示意图
03
空间清理
Ustore支持用户执行Vacuum语句对空间进行清理,但Vacuum不是唯一的清理途径。Ustore有一套自适应的空间清理机制,执行DML(insert,update,delete)、DQL(select)语句时,一旦发现空间不足或者检测到潜在空闲空间达到阈值,即尝试进行清理,如图3所示。
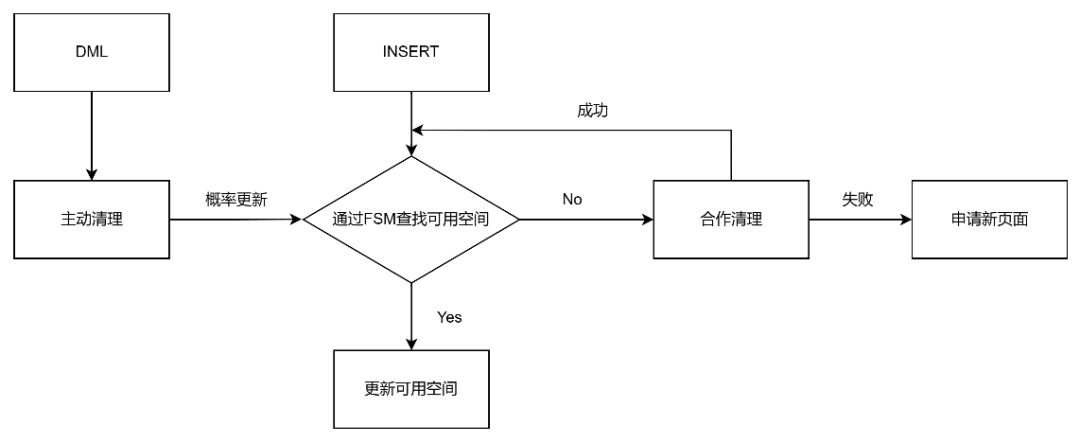
图3 Ustore空间清理流程
通过DML或者DQL触发清理,会出现如果某些页面一直未访问,就不能进行清理。为了解决此问题,Ustore引入基于概率的清理方案。基于概率的清理,使用随机算法选择本次清理的页面,该算法并非完全随机,可以保证在执行多次后选取的页面可覆盖关系表的所有页面。

性能测试对比
Ustore的核心优势场景是数据频繁更新的场景,相较于Astore而言Ustore空间利用更加紧凑,且高效的空间利用有效解决了频繁更新场景下的数据空间膨胀造成性能下降的问题。为此我们测试对比了Astore和Ustore在数据频繁更新场景下的性能。
在非主键的范围更新下,Ustore测试结果相比Astore有很大提升,在不同并发数下的平均性能提升在40%以上,结果如图4所示。
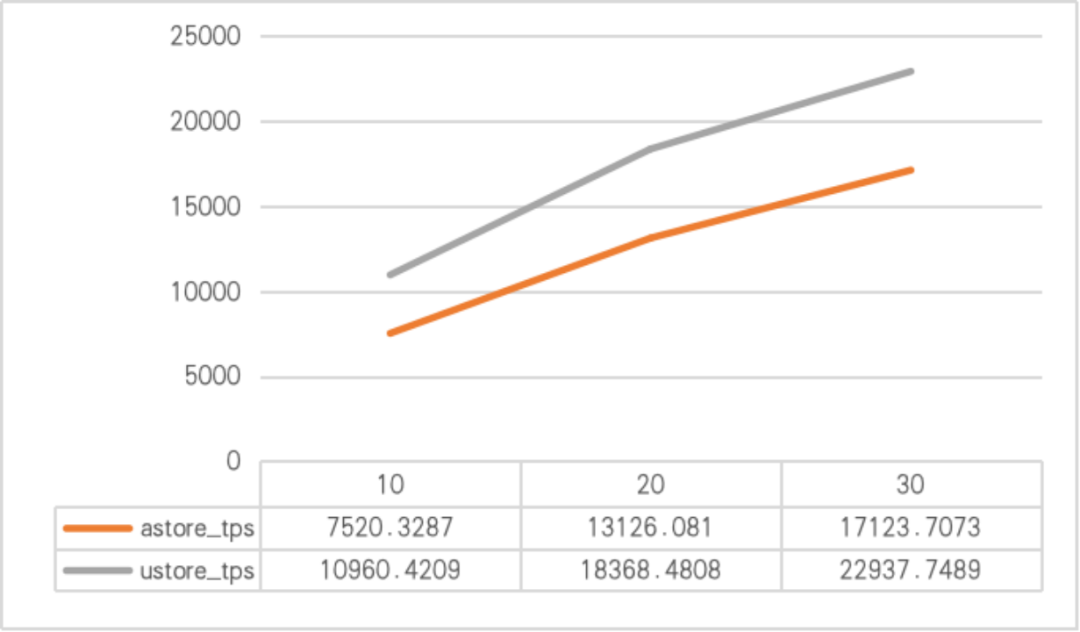
图4 非主键范围更新,Astore和Ustore的性能对比
另一方面,随着更新操作不断执行,Astore出现了表空间膨胀问题,而 Ustore的空间使用则比较平稳,如图5所示。

图5 非主键范围更新,Astore和Ustore的空间对比

总结
Ustore存储引擎在数据频繁更新场景下有非常好的性能和空间表现,可以确保业务系统运行更加平稳,能够支持适应更多业务场景和工作负载,特别是对性能和稳定性有更高要求的金融核心业务场景。
关于作者
赵森,云和恩墨数据库内核研发工程师,毕业于西安交通大学,参与MogDB数据库Ustore引擎的设计、规格文档撰写,目前主要从事Ustore存储引擎uheap、ubtree模块的开发工作。

数据驱动,成就未来,云和恩墨,不负所托!
云和恩墨创立于2011年,是业界领先的“智能的数据技术提供商”。公司总部位于北京,在国内外35个地区设有本地办公室并开展业务。
云和恩墨以“数据驱动,成就未来”为使命,致力于将创新的数据技术产品和解决方案带给全球的企业和组织,帮助客户构建安全、高效、敏捷且经济的数据环境,持续增强客户在数据洞察和决策上的竞争优势,实现数据驱动的业务创新和升级发展。
自成立以来,云和恩墨专注于数据技术领域,根据不断变化的市场需求,创新研发了系列软件产品,涵盖数据库、数据库存储、数据库云管和数据智能分析等领域。这些产品已经在集团型、大中型、高成长型客户以及行业云场景中得到广泛应用,证明了我们的技术和商业竞争力,展现了公司在数据技术端到端解决方案方面的优势。
在云化、数字化和智能化的时代背景下,云和恩墨始终以正和多赢为目标,感恩每一位客户和合作伙伴的信任与支持,“利他先行”,坚持投入于数据技术核心能力,为构建数据驱动的智能未来而不懈努力。
我们期待与您携手,共同探索数据力量,迎接智能未来。
这篇关于循序渐进丨MogDB Ustore存储引擎剖析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





