本文主要是介绍语言模型进化史(上),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
由于篇幅原因,本文分为上下两篇,上篇主要讲解语言模型从朴素语言模型到基于神经网络的语言模型,下篇主要讲解现代大语言模型以及基于指令微调的LLM。文章来源是:https://www.numind.ai/blog/what-are-large-language-models
一、语言模型
简单来说,语言模型能够以某种方式生成文本。它的应用十分广泛,例如,可以用语言模型进行情感分析、标记有害内容、回答问题、概述文档等等。但理论上,语言模型的潜力远超以上常见任务。
想象你有一个完备的语言模型,可生成任意类型的文本,并且人们还无法辨别这些内容是否由计算机生成,那么我们就可以使其完成很多事,例如生成具有代表性的内容,如电子邮件、新闻稿、书籍和电影剧本等。再进一步来看,还可以用其生成计算机程序,甚至构建整个软件。只要愿意,我们还可以让它生成科学论文。如果语言模型真正“完备”,那么它们生成的论文将能够以假乱真,与真实论文没有区别,这意味着必须对语言模型展开实质性研究!
当然,就目前而言,完备的语言模型还无法实现,不过也展示出了这些系统的潜力。语言模型不仅仅能“预测文本”,它们的潜力可能远超想象。
现在我们回顾一下语言模型的发展历程,从最初的朴素语言模型到目前基于Transformer的LLM(大语言模型)。
二、朴素语言模型
语言模型是机器学习模型, 因此它们会学习如何生成文本。教授它们的方法(即训练阶段)是提供一个大规模文本语料库,它们将从中学习如何模仿生成这些文本的过程。
也许这听起来有些抽象,但创建一个朴素语言模型实际上非常简单。你可以将文本语料库分成一定大小的字符串块,并测量它们的频率。下面是我使用大小为2的字符串得到的结果:
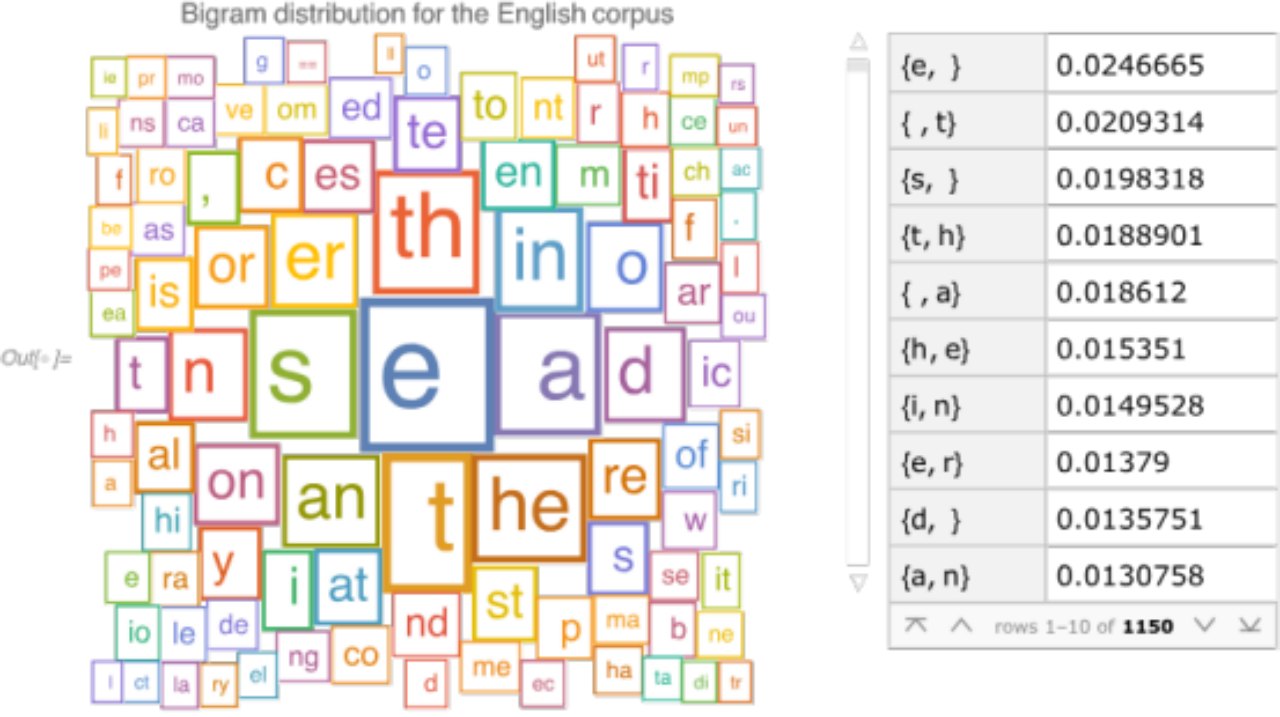
这些字符串块被称为n-gram(其中n表示字符串的大小,因此此处n=2)。通过这些n-gram,你可以像玩多米诺骨牌一样生成文本。从一个初始的n-gram开始,例如“th”,然后根据测量的频率随机选择一个以初始n-gram结尾的n-gram。在这个例子中,如果选择“hi”,就会形成 “th”+“hi”=“thi”。然后再继续添加以“i”开头的n-gram,以此类推,生成整段文本。不过正如你所想,这些n-gram模型并不能生成足够连贯的文本。但也说得通,因为该模型的记忆能力很有限, 只通过前一个字符来预测下一个字符。如果我们使用n=4的字符串,结果会稍微好一些:
“complaine building thing Lakers inter blous of try sure camp Fican chips always and to New Semested and the to have being severy undiscussion to can you better is early shoot on”
现在出现了一些拼写正确的单词,但结果仍不够理想!理论上,进一步增加n的值,输出结 果会得到改善,但在实践中,我们无法显著增加n值,因为这需要一个庞大的数据集来训练模型。最后,我们可以尝试将单词而不是字符作为基本单位(在自然语言处理术语中称为“词元(token))。这会改善输出结果,但因为n<6,生成的文本仍然缺乏连贯性。
这些朴素语言模型的记忆能力始终有限,因此无法生成超过一定长度的连贯文本。尽管如此, 它们仍具备一定用途。几年前,朴素语言模型被广泛用于文本分类和语音识别,且如今仍被用于语言识别等任务。然而,对于更高级的文本理解和文本生成任务来说,朴素语言模型就捉襟见肘了。因此需要神经网络。
三、基于神经网络的语言模型
现代语言模型基于(人工) 神经网络。神经网络是受人脑启发开发出的计算机,能够通过任务示例学习如何执行任务。这种机器学习形式也被称为深度学习, 因为其中的网络由多个计算层组成(因此被称为“深度”网络)。在神经网络中,通过遍历任务示例并迭代修改网络参数以优化任务目标,从而实现学习。你可以将这些参数想象成一组旋钮(knob),通过左右旋动以改进目标,但区别是计算机为你进行改进,并且知道如何同时正确地朝着改进方向进行调整(得益于著名的反向传播算法)。因此,网络会遍历任务示例(通常以几百个示例为一批),并在这一过程中优化目标。以下是一个正在被优化的目标示例(称为成本函数,数值越小越 好):

随着模型的训练,成本函数值会逐渐下降,意味着模型在任务处理上变得更加优秀。
在该案例中,我们想要生成文本。 目前,标准的方法是训练一个模型,通过前面的单词预测后面的单词。由于下一个单词有多种可能性,模型会学习为每个可能的单词关联一个概率。以下是对“the cat sat on the”之后可能出现单词的概率分布可视化图像:
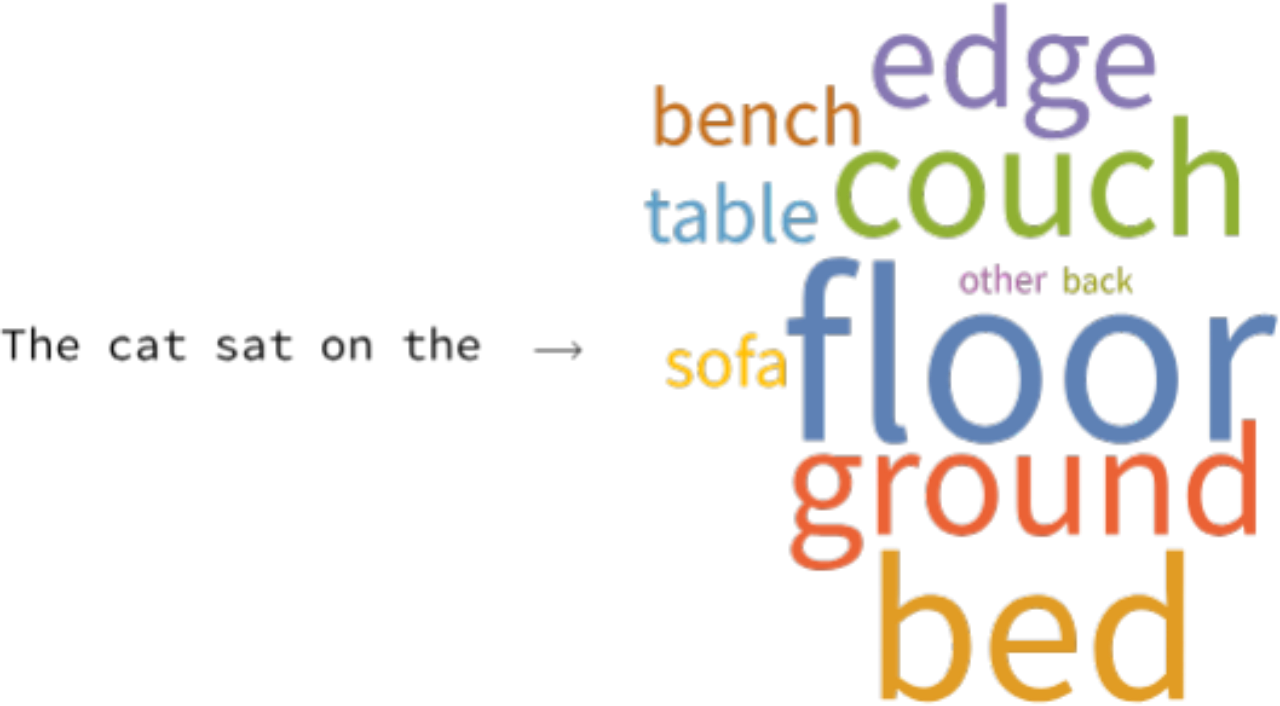
一旦拥有这样的预测模型,就可以从预测概率中抽样来生成下一个单词,然后将该单词重新输入到网络,再抽样一个新的单词,以此类推,从而生成文本。这一生成过程被称为自回归,因为网络利用自己的预测结果来生成新的预测。虽然有人对此提出了异议,认为这并非最佳方法,但目前而言,这就是最实际的操作方式, 且效果也出奇地好!
曾经用于建模语言的第一类神经网络是RNN(循环神经网络),尤其是LSTM(长短期记忆网络)架构。RNN就像一个逐个阅读单词的小型机器, 在这一过程中,它会更新思维状态(mental state)。这种思维状态如同记忆,使它们在生成文本时能大概记住一段时间的信息。相比n-gram模型,RNN模型能够获得更为优越的性能。
RNN创建之初, 神经对话模型(Neural Conversational Model)给我留下了深刻印象。该模型是Google于2015年基于电影字幕训练的一个特殊LSTM模型, 当时这个模型已经算得上 是LLM了(也可能是首个LLM):拥有3亿参数,并在约10亿词的数据上进行训练。由于 电影字幕是对话形式,因此可直接将该模型用作聊天机器人。以下是不同人类输入对应的回答示例:
人类:你叫什么名字?
机器:我叫朱莉娅。
人类:你是什么时候出生的?
机器:7月20日。人类:我的名字是大卫。我的名字是什么?
机器:大卫。
人类:天行者是谁?
机器:他是一个英雄。
人类:天空是什么颜色?
机器:蓝色。
人类:血液是什么颜色?
机器:和黑眼圈的颜色相同。
如你所见,该模型能够闲聊,同时也对世界有一定了解,这些知识完全是通过学习如何预测文本获得的!我记得自己曾对这一事实很感兴趣:学习预测文本迫使你理解世界(但并不意味着这个过程很容易)。然而,该模型也有一些明显的短板:它经常出错,并且与类似基于LSTM的模型一样,无法生成长篇连贯的文本。理论上,循环神经网络可以长时间记忆事物,但在实践中,它们却往往很快就忘记了:经过几十到一百个词之后,它们就会开始偏离主题,不再连贯。
2017年,人们针对短期记忆问题提出一种解决方案——Transformer。Transformer是一种基于注意力机制的新型神经网络架构(本质上是一种选择操作),下图来自介绍Transformer的论文,用以说明其在翻译任务中的工作原理:
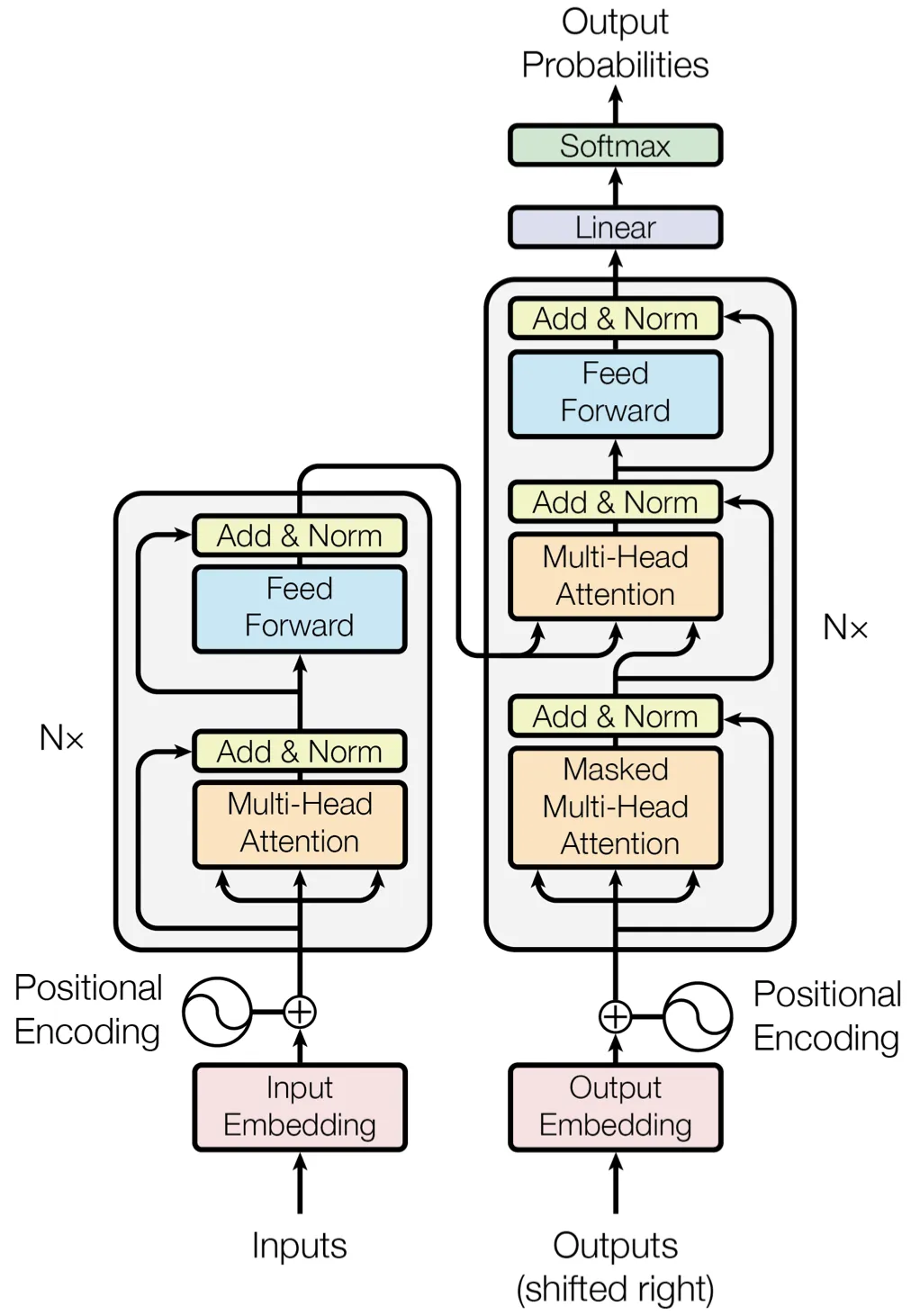
Transformer在各个方面都可圈可点,但最值得一提的是, 该架构在文本建模方面表现非常出色,并且很适合在GPU上运行,从而处理(和学习)大量数据。正是有了Transformer这 种架构,才使得现代LLM得以兴起(或至少起到了很强的促进作用) 。
(上篇结束)
这篇关于语言模型进化史(上)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



