本文主要是介绍基于lora技术微调Gemma(2B)代码实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、前置条件
获得模型访问权,选择Colab运行时,配置训练环境。
先在Kaggle上注册,然后获得Gemma 2B 的访问权;
然后在Google colab 配置环境,主要是GPU的选择,免费的是T4,建议采用付费的A100(为了节省时间,微调训练耗时T4需要30分钟左右,A100只需要2分钟左右)
最后 在Kaggle 上的account上生成令牌文件(主要是usename 和 API Key),并将令牌文件配置到colab环境。

二、微调步骤
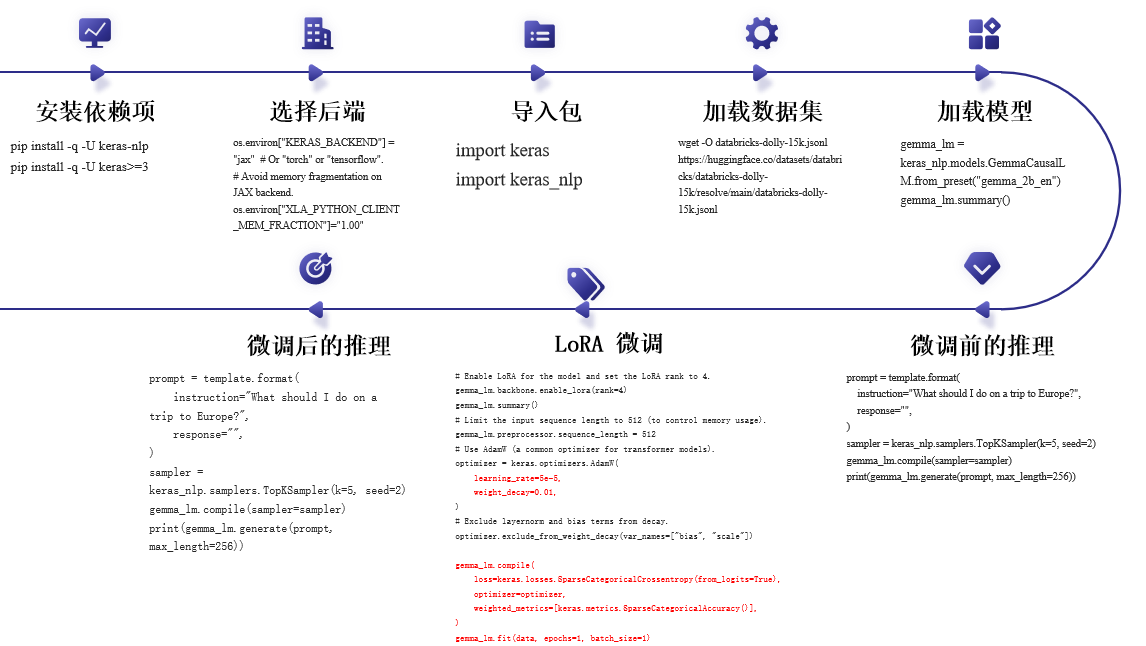
三、源码
# -*- coding: utf-8 -*-
"""gemma-lora微调.ipynbAutomatically generated by Colaboratory.Original file is located athttps://colab.research.google.com/drive/1_uEbuYP-vk0tCO0EA7IQ1t85jJ6ne7Qi
"""from google.colab import files
uploaded = files.upload()!mkdir ~/.kaggle
!mv kaggle.json ~/.kaggle/!chmod 600 ~/.kaggle/kaggle.json# Install Keras 3 last. See https://keras.io/getting_started/ for more details.
!pip install -q -U keras-nlp
!pip install -q -U keras>=3import osos.environ["KERAS_BACKEND"] = "jax" # Or "torch" or "tensorflow".
# Avoid memory fragmentation on JAX backend.
os.environ["XLA_PYTHON_CLIENT_MEM_FRACTION"]="1.00"import keras
import keras_nlp!wget -O databricks-dolly-15k.jsonl https://huggingface.co/datasets/databricks/databricks-dolly-15k/resolve/main/databricks-dolly-15k.jsonlimport json
data = []
with open("databricks-dolly-15k.jsonl") as file:for line in file:features = json.loads(line)# Filter out examples with context, to keep it simple.if features["context"]:continue# Format the entire example as a single string.template = "Instruction:\n{instruction}\n\nResponse:\n{response}"data.append(template.format(**features))# Only use 1000 training examples, to keep it fast.
data = data[:1000]gemma_lm = keras_nlp.models.GemmaCausalLM.from_preset("gemma_2b_en")
gemma_lm.summary()prompt = template.format(instruction="What should I do on a trip to Europe?",response="",
)
sampler = keras_nlp.samplers.TopKSampler(k=5, seed=2)
gemma_lm.compile(sampler=sampler)
print(gemma_lm.generate(prompt, max_length=256))prompt = template.format(instruction="Explain the process of photosynthesis in a child could understand.",response="",
)
print(gemma_lm.generate(prompt,max_length=256))# Enable LoRA for the model and set the LoRA rank to 4.
gemma_lm.backbone.enable_lora(rank=4)
gemma_lm.summary()# Limit the input sequence length to 512 (to control memory usage).
gemma_lm.preprocessor.sequence_length = 512
# Use AdamW (a common optimizer for transformer models).
optimizer = keras.optimizers.AdamW(learning_rate=5e-5,weight_decay=0.01,
)
# Exclude layernorm and bias terms from decay.
optimizer.exclude_from_weight_decay(var_names=["bias", "scale"])gemma_lm.compile(loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),optimizer=optimizer,weighted_metrics=[keras.metrics.SparseCategoricalAccuracy()],
)
gemma_lm.fit(data, epochs=1, batch_size=1)prompt = template.format(instruction="What should I do on a trip to Europe?",response="",
)
sampler = keras_nlp.samplers.TopKSampler(k=5, seed=2)
gemma_lm.compile(sampler=sampler)
print(gemma_lm.generate(prompt, max_length=256))prompt = template.format(instruction="Explain the process of photosynthesis in a way that a child could understand.",response="",
)
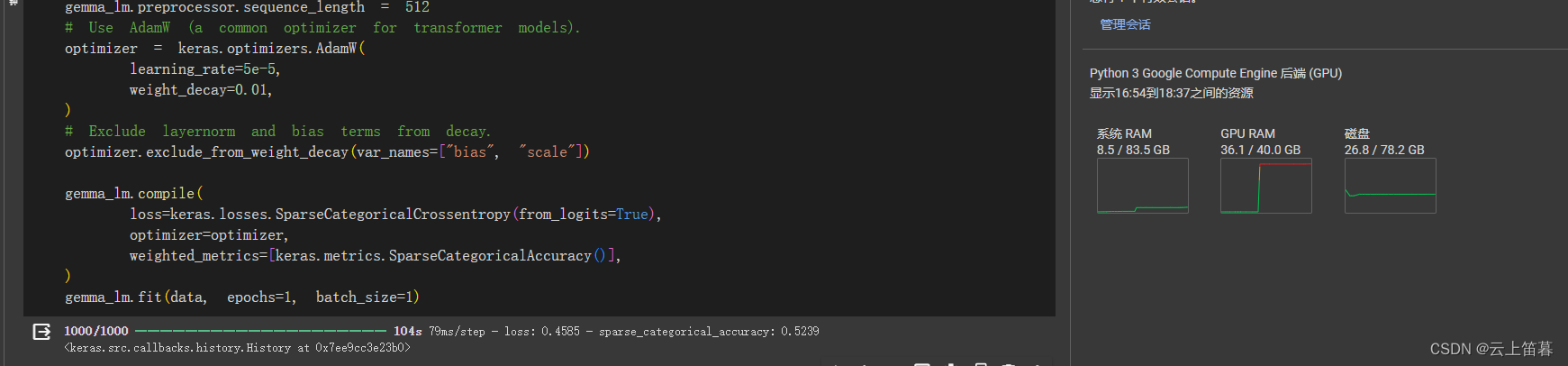
print(gemma_lm.generate(prompt, max_length=256))微调关键代码--A100
这篇关于基于lora技术微调Gemma(2B)代码实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






