本文主要是介绍基于HA的hadoop2.7.1完全分布式集群搭建,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文的前提是假设你已经成功安装一台服务器的hadoop伪分布式,因此有些细节没有具体给出解释(http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/SingleCluster.html)。
参考文章:http://hadoop.apache.org/docs/r2.7.1/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html
首先截图看下完成后能通过web访问的hadoop框架的样子
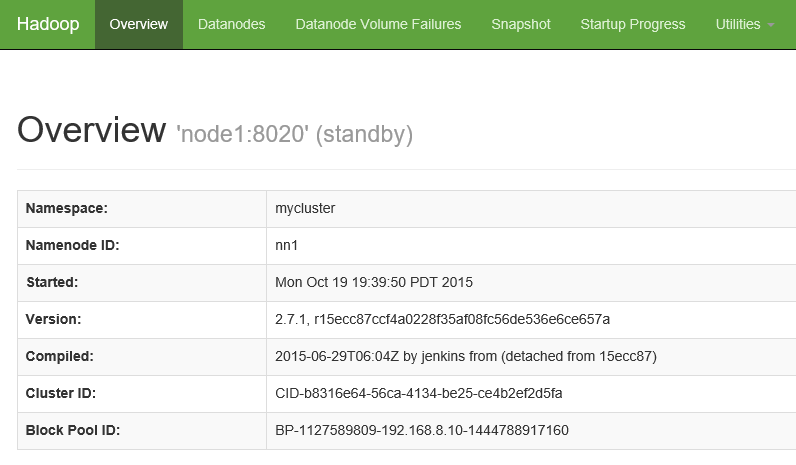
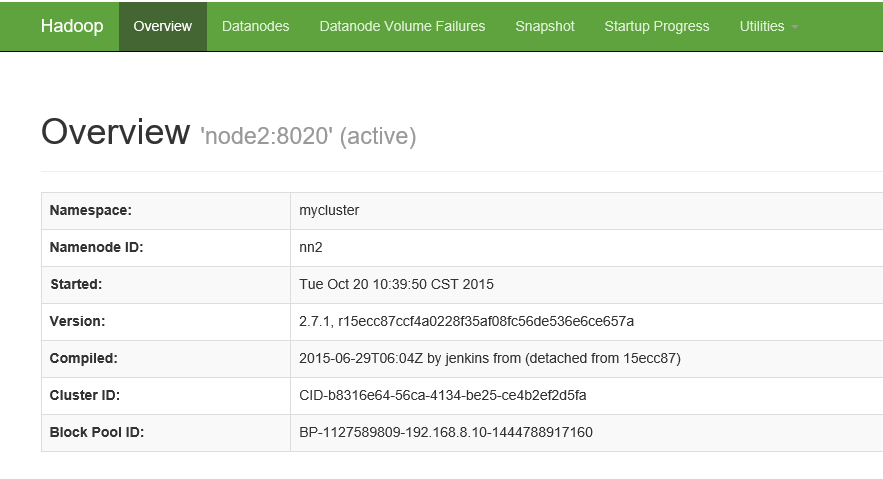
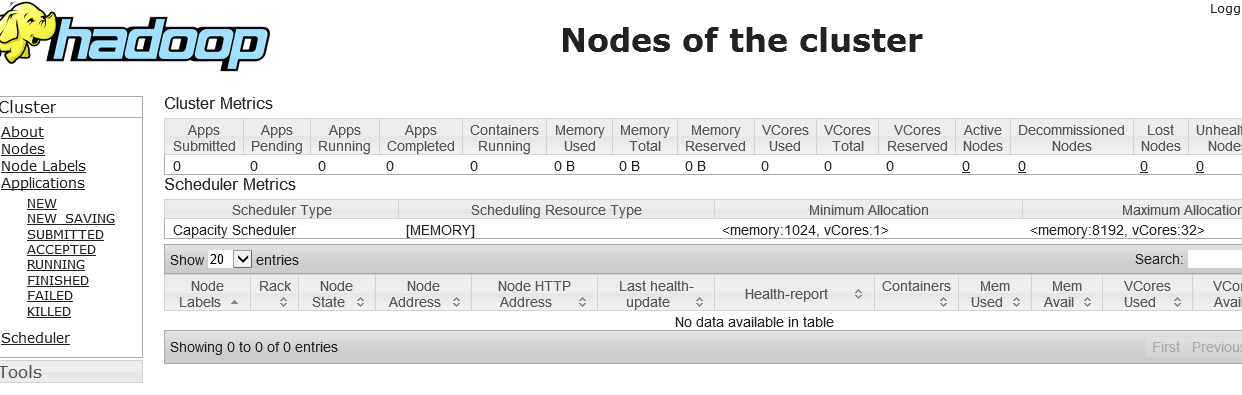
一、节点的分布

可以看到这个集群有5台服务器,我本人是在VMware虚拟机中装的2台Ubuntu14.04和3台centOS7,由这五台虚拟服务器来进行完全的分布式的集群hadoop搭建。(当然,可以根据自己的需求或者是意愿来选着linux系统和服务器台数,推荐这样建立集群:在一台虚拟服务器上把zookeeper和hadoop以及JDK等的环境配置好后,通过VMware虚拟机的克隆功能来复制剩下的若干台,这样会节省重复的时间,最后是修改各自的ip和hostname。)
二、JDK和Hadoop的下载安装
linux系统的java jdk和hadoop的解压和安装,可以百度,或者谷歌,本文省略,不过有一点需要提下,注意linux和hadoop的版本的匹配,hadoop的官网的2.5版本和之前的都是32位的,之后的是64位的(查看hadoop版本:进入hadoop-2.x.x/lib/native中输入如下命令:file libhadoop.so.1.0.0即可查看是32位的还是64位的,如果版本和系统不匹配,则需要下载源码进行编译,不过话说回来,随着内存的扩大,现在一般系统都选择64位的。)
三、hadoop的HA的搭建
1、zookeeper的下载
在zookeeper的官网下在3.4.6的最新稳定版本。
2、linux前期准备
在搭建之前,介绍下linux的下的ssh免密码登录,和防火墙的关闭,
Ubuntu 的防火墙:ufw disable
centOS的防火墙:centOS7是 systemctl stop firewalld.service(之前的是iptables,笔者刚搭建的时候没注意到,后面MapReduce各种连接错误,都快崩溃了,希望少走弯路,保持学习的热情。)
ssh 的免密码登录:在node1上:
①没有ssh安装ssh,可以如下命令,如果linux提示错误,按照提示的错误,更新下出错的那个版本在安装sshserver即可。
$ sudo apt-get install ssh
$ sudo apt-get install rsync
②生成公钥和私钥
$ ssh-keygen -t dsa -P ” -f ~/.ssh/id_dsa
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
之后可以在node1用ssh localhost登录,发现不用输入密码了。
(补充一点,在每台linux上把每台主机的主机名依次修改位node1到node5,/etc/hostname中)
③ 把node1的公钥拷贝到node2~node5中,实现node1到其他服务器的ssh无密码登录。
scp -r ~/.ssh/authorized_keys root@node2:~/.ssh/
把node2依次改为node3到node5,即可。
在node1中登录node2:ssh node2,发现不需要密码就登录了(第一次登录提示yes or no ?输入yes即可),主机名为node2了,输入exit即可退出回到node1的界面,再登录node3到node5即可。
3、zookeeper集群搭建(可以参考zookeeper的官网)
把zookeeper中conf目录下的
zoo_sample.cfg复制一封改为:zoo.cfg,文件中添加如下内容:
dataDir=/opt/zookeeper
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
最后在node1的服务器的/opt/zookeeper目录下建立myid文件,内容为1;同理node2为2;node3为3。
在node1上进入到zookeeper的bin目录下,输入./zkServer.sh start
同理node2;
同理node3;
再在node1到node3的bin目录下,输入./zkServer.sh status
看到如下内容表示你已成功:
JMX enabled by default
Using config: /usr/zookeeper/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: follower
如上zookeeper集群已经搭建完成。
四、hadoop的集群的搭建
1、xml文件的配置
首先把每台机服务器的/etc/hosts文件配好,如本人的:
192.168.8.3 node1
192.168.8.13 node2
192.168.8.50 node3
192.168.8.51 node4
192.168.8.6 node5
注意5台机器保持是一样,可以通过scp拷贝。
在node1上的hadoop的解压目录下,进入etc/hadoop
在hadoop-env.sh、yarn-env.sh中,把JAVA_HOME改为你在linux中安装的jdk目录。
修改hdfs-site.xml :
<configuration>
<property><name>dfs.nameservices</name><value>mycluster</value>
</property>
<property><name>dfs.ha.namenodes.mycluster</name><value>nn1,nn2</value>
</property>
<property><name>dfs.namenode.rpc-address.mycluster.nn1</name><value>node1:8020</value>
</property>
<property><name>dfs.namenode.rpc-address.mycluster.nn2</name><value>node2:8020</value>
</property>
<property><name>dfs.namenode.http-address.mycluster.nn1</name><value>node1:50070</value>
</property>
<property><name>dfs.namenode.http-address.mycluster.nn2</name><value>node2:50070</value>
</property>
<property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://node3:8485;node4:8485;node5:8485/mycluster</value>
</property>
<property><name>dfs.client.failover.proxy.provider.mycluster</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property><name>dfs.ha.fencing.methods</name><value>sshfence</value></property><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/root/.ssh/id_dsa</value></property>
<property><name>dfs.journalnode.edits.dir</name><value>/opt/journal/node/local/data</value>
</property>
<property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property></configuration>修改core-site.xml:
<configuration>
<property><name>fs.defaultFS</name><value>hdfs://mycluster</value></property><property> <name>hadoop.tmp.dir</name><value>/opt/hadoop/data/hadoop/temp</value><description>Abase for other temporarydirectories.</description></property><property><name>ha.zookeeper.quorum</name><value>node1:2181,node2:2181,node3:2181</value>
</property>
</configuration>修改yarn-site.xml:
<configuration>
<!-- Site specific YARN configuration properties -->
<property><name>yarn.resourcemanager.hostname</name><value>node1</value>
</property>
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value>
</property>
<property><name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>修改mapred-site.xml:
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value><description>Execution framework set to Hadoop YARN.</description></property>
</configuration>在还是hadoop的etc/hadoop配置文件中:
修改slaves文件:增加三个datanode
node3
node4
node5
最后,node1上改动的文件通过scp拷贝到其他的四台机器的相同位置上替换原来的这些文件即可。
总结:2.x的必需的守护进程有5个,所以可以看到我们需要配置的文件也有5个,少任何一个都是不行的。
五、hadoop的启动运行
这个,我不行敲字,我就截个图,把我的运行步骤贴上来,
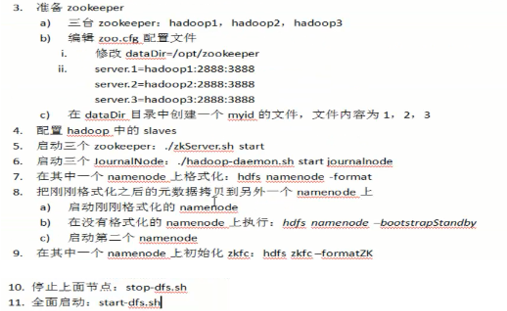
最后启动yarn:start-yarn.sh
(友情提示:不要多次 namenode -format,这样会报错,解决办法,就是到你在xml文件中配置的路径下,找到datanode对应的文件夹,删除之后,再namenode format 就可以了。)
查看,我们通过jps查看,如开头的表格所示,我们这十七个节点是否全部启动:
node1:
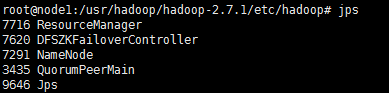
node2:
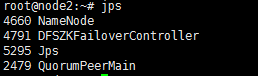
node3:
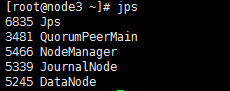
node4:
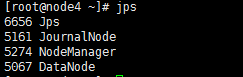
node5:
这篇关于基于HA的hadoop2.7.1完全分布式集群搭建的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




