本文主要是介绍scRNA+bulk+MR:动脉粥样硬化五个GEO数据集+GWAS,工作量十分到位,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天给大家分享一篇JCR一区,单细胞+bulk+MR的文章:An integrative analysis of single-cell and bulk transcriptome and bidirectional mendelian randomization analysis identified C1Q as a novel stimulated risk gene for Atherosclerosis

- 标题:单细胞和批量转录组的整合分析以及双向孟德尔随机化分析确定了C1Q作为动脉粥样硬化新型受刺激风险基因。
- 发表日期:2023年12月
- 期刊:Frontiers in Immunology
- 影响因子:7.3
- 中科院分区:医学2区
- 小类:免疫学2区
摘要
背景:
补体成分1q(C1Q)相关基因对人类动脉粥样硬化斑块(HAP)的作用尚不清楚。我们的目标是利用单细胞RNA测序(scRNA-seq)和批量RNA分析来建立与C1Q相关的中心基因,以更有效地诊断和预测HAP患者,并利用双向孟德尔随机化(MR)分析探究C1Q与HAP(缺血性中风)之间的关联。
方法:
从基因表达数据共享库(GEO)数据库下载HAP scRNA-seq和批量RNA数据。使用GBM、LASSO和XGBoost算法筛选与C1Q相关的中心基因。我们建立了机器学习模型,使用广义线性模型和接收器工作特征(ROC)分析来诊断和区分动脉粥样硬化的类型。此外,我们使用ssGSEA评分了HALLMARK_COMPLEMENT信号通路,并通过在RAW264.7巨噬细胞和apoE-/-小鼠中进行qRT-PCR确认了中心基因的表达。此外,通过双向MR分析评估了C1Q与HAP之间的风险关联,以C1Q作为暴露因素,以缺血性中风(IS,大动脉动脉粥样硬化)为结果。使用倒数方差加权(IVW)作为主要方法。
结果:
我们利用scRNA-seq数据集(GSE159677)识别了24个细胞群和12种细胞类型,并在scRNA-seq和GEO数据集中揭示了七个C1Q相关的差异表达基因(DEGs)。然后,我们使用GBM、LASSO和XGBoost从这七个DEGs中选择了C1QA和C1QC。我们的研究结果表明,无论是训练队列还是验证队列,都能有效诊断出HPAs患者。此外,我们确认SPI1是负责调节HAP中这两个中心基因的潜在转录因子。我们的分析进一步揭示了HALLMARK_COMPLEMENT信号通路与C1QA和C1QC相关且被激活。我们使用qPCR确认了ox-LDL处理的RAW264.7巨噬细胞和apoE-/-小鼠中C1QA、C1QC和SPI1的高表达水平。MR的结果表明,C1Q的遗传风险与IS之间存在正相关,证据是比值比(OR)为1.118(95%CI:1.013-1.234,P = 0.027)。
结论:
作者已经成功开发并验证了一个包含两个基因的HAP新型诊断标志,而MR分析提供了支持C1Q对IS有利关联的证据。
关键词:动脉粥样硬化斑块(AP),ScRNA-seq,孟德尔随机化(MR),补体成分1q(C1q),LASSO
结果
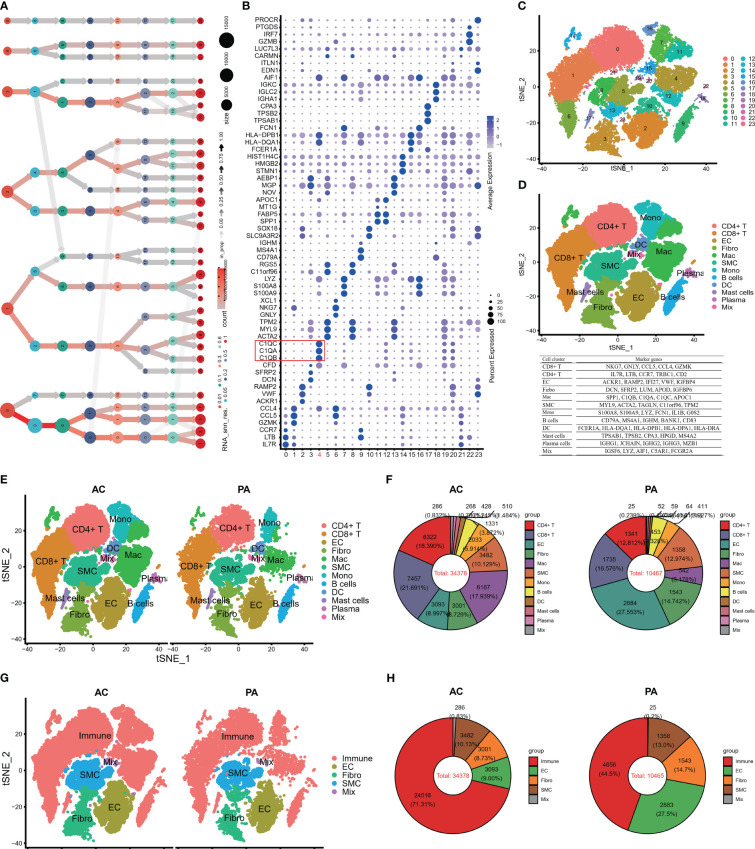
图1 人类AP组织的单细胞RNA测序。
- (A)对总scRNA-seq数据进行不同分辨率的聚类树分析。
- (B)使用Seurat包(4.1.2)的“FindAllMarkers”功能绘制了每个群集的前三个标记物。红色框表示C1Q细胞群。
- (C)T分布随机邻居嵌入(tSNE)在0.8的分辨率下显示了24个聚类。
- (D)tSNE图被着色显示了12种不同的细胞类型。注意:标记基因位于tSNE图下方。
- (E)生成并按细胞类型着色的AC和PA组之间的12种细胞类型的概述。
- (F)使用饼图比较了每个组中细胞类型的比例。
- (G,H)使用Seurat包(4.1.2)将免疫细胞与其他细胞合并后,使用tSNE和饼图描述了AC和AP组之间的细胞类型。
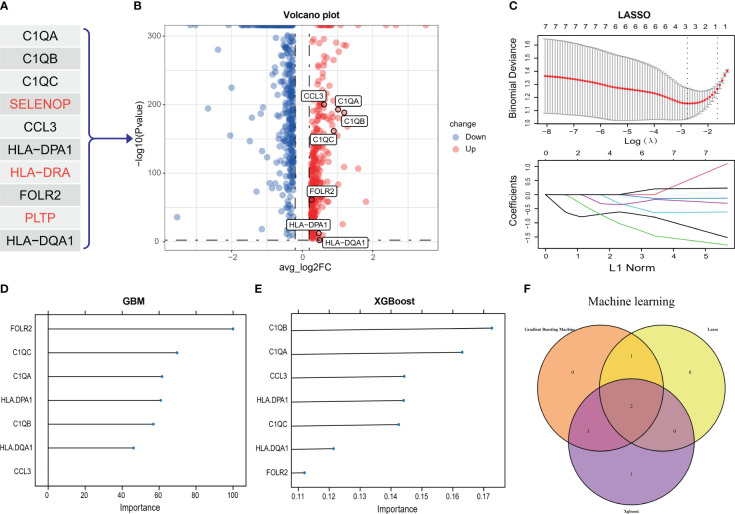
图2 从scRNA-seq和GEO数据集中选择C1Q中心基因。
- (A)从C1Q细胞群中提取的前十个基因。
- (B)这10个基因在scRNA-seq中的AC和PA组之间的781个差异表达基因中检测到,并且得到了七个基因(C1QA、C1QB、C1QC、CCL3、HLA-DPA1、FOLR2和HLA-DQA1)以进行进一步分析。
- (C)LASSO算法选择C1Q中心基因。
- (D)GBM算法选择C1Q中心基因。
- (E)XGBoost算法选择C1Q中心基因。
- (F)三种算法识别了两个基因(C1QA和C1QC)。
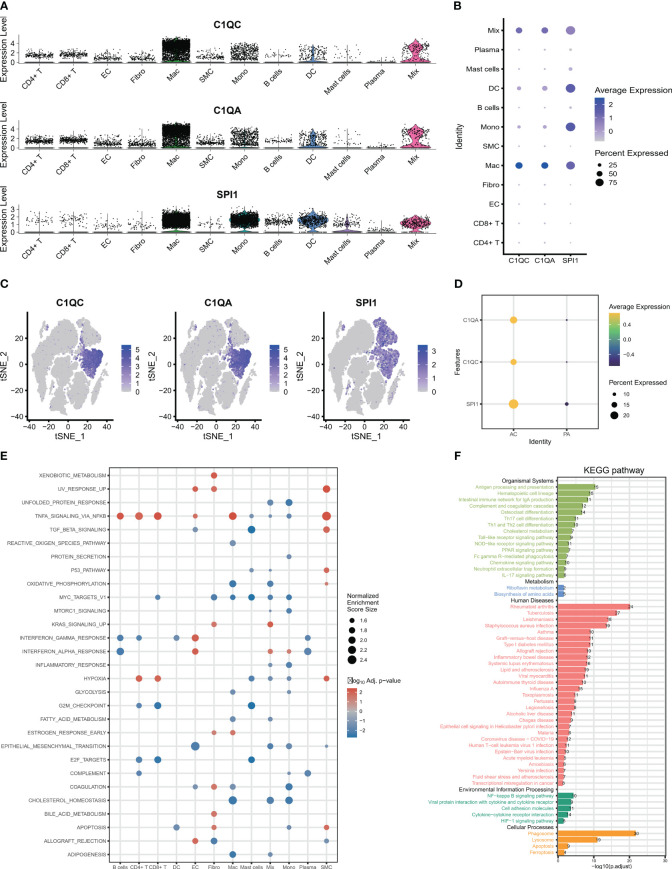
图3 scRNA-seq中特征基因的表达和参与的信号通路。
- (A-C)图显示了使用scRNA-seq在细胞群中C1QA、C1QC和SPI1的表达。
- (D)三个特征基因在AC组中上调表达。
- (E)GSEA显示了所有12个细胞群中的信号通路。
- (F)KEGG图显示了巨噬细胞群中的KEGG通路。

图4 动脉粥样硬化(AP)进展的诊断预测模型。
- (A)使用广义线性模型(回归)在GSE43292训练队列中使用两个生物标志物构建的诊断预测模型的混淆矩阵显示实际和预测样本(动脉瘤和完整)。
- (B)使用ROC曲线评估了训练队列中两个标志物的诊断预测准确性(动脉瘤=32,完整=32,AUC=0.842)。
- (C)PCoA分析显示这两个标志物可以显著区分动脉瘤和完整样本。
- (D)使用广义线性模型(回归)在GSE41571外部验证队列中使用两个生物标志物构建的诊断预测模型的混淆矩阵显示实际和预测样本(破裂=5,稳定=6)。
- (E)使用ROC曲线评估了验证队列中两个标志物的诊断预测准确性(破裂=5,稳定=6,AUC=0.933)。
- (F)PCoA分析显示这两个标志物可以显著区分破裂样本和稳定样本。
- (G)使用两个生物标志物构建的诊断预测模型在GSE28829外部验证队列中的实际和预测样本的混淆矩阵显示(进展=13,早期=16)。
- (H)使用ROC曲线评估了验证队列中两个标志物的诊断预测准确性(进展=13,早期=16,AUC=0.938)。
- (I)PCoA分析显示这两个标志物可以显著区分进展样本和早期样本。
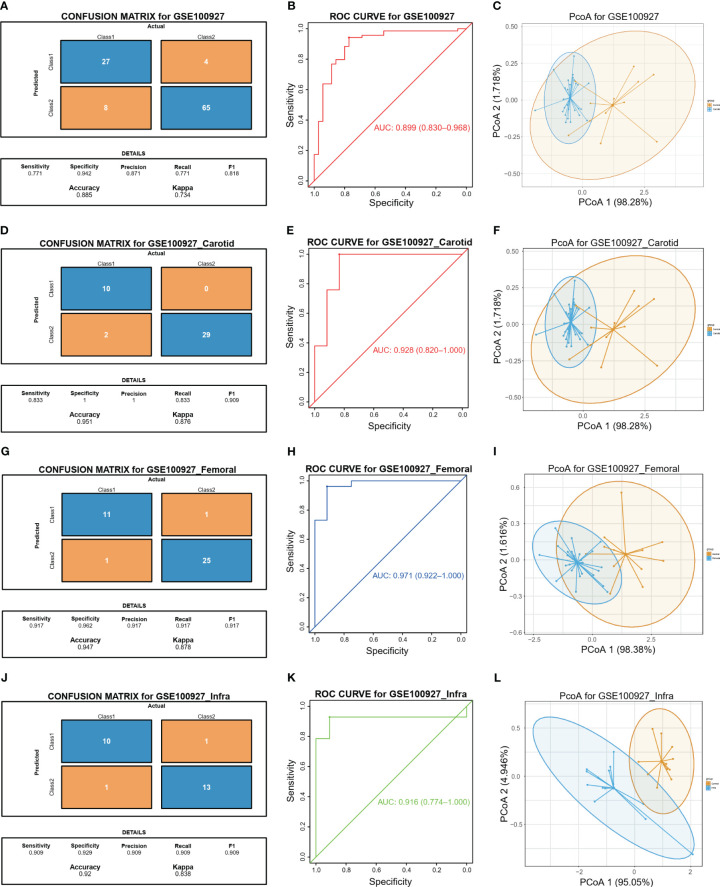
图5 用于诊断和预测HAP与正常对照组的诊断预测模型。
- (A)使用两个生物标志物在GSE100927外部验证队列中构建的诊断预测模型的混淆矩阵显示实际和预测样本(动脉粥样硬化=69,正常动脉=35)。
- (B)使用ROC曲线评估了验证队列中两个标志物的诊断预测准确性(动脉粥样硬化=69,正常动脉=35,AUC=0.899)。
- (C)PCoA分析显示这两个标志物可以显著区分动脉粥样硬化动脉和正常动脉。
- (D)使用两个生物标志物在GSE100927_Carotid外部验证队列中构建的诊断预测模型的混淆矩阵显示实际和预测样本(颈动脉=29,正常=12)。
- (E)使用ROC曲线评估了验证队列中两个标志物的诊断预测准确性(颈动脉=29,正常=12,AUC=0.928)。
- (F)PCoA分析显示这两个标志物可以显著区分颈动脉动脉粥样硬化和正常动脉。
- (G)使用两个生物标志物在GEO100927_Femoral外部验证队列中构建的诊断预测模型的混淆矩阵显示实际和预测样本(股动脉=26,正常=12)。
- (H)使用ROC曲线评估了验证队列中两个多组学标志物的诊断预测准确性(股动脉=26,正常=12,AUC=0.981)。
- (I)PCoA分析显示这两个标志物可以显著区分股动脉中的AP和正常样本。
- (J)使用两个生物标志物在GSE100927_Infra外部验证队列中构建的诊断预测模型的混淆矩阵显示实际和预测样本(下肢下部领域=14,正常=11)。
- (K)使用ROC曲线评估了验证队列中两个标志物的诊断预测准确性(下肢下部领域=14,正常=11,AUC=0.89)。
- (L)PCoA分析显示这两个标志物可以显著区分下肢下部领域中的AP和正常样本。
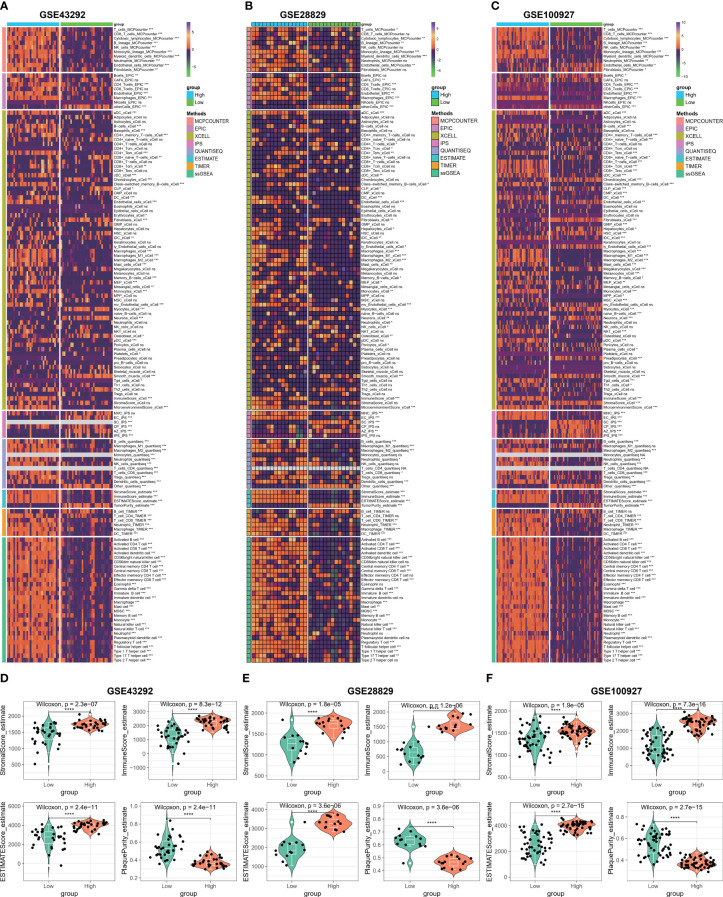
图6 基于C1Q中心基因的免疫微环境分析。
- (A)热图显示了通过8种算法在GSE43292队列中动脉瘤和完整样本之间免疫浸润细胞的富集情况。
- (B)热图显示了通过8种算法在GSE28829队列中早期和晚期样本之间免疫浸润细胞的富集情况。
- (C)热图显示了通过8种算法在GSE100927队列中动脉粥样硬化斑块和对照样本之间免疫浸润细胞的富集情况。
- (D-F)比较了GSE43292(D)、GSE28829(E)和GSE100927(F)数据集中高和低C1Q组之间的基质分数、免疫分数、ESTIMATE分数和斑块纯度。

图7 基于C1Q中心基因的免疫信号通路和免疫调节因子评估。
- (A-C)比较了GSE43292(A)、GSE28829(B)和GSE100927(C)数据集中高低C1Q组之间的16个免疫信号通路,并对免疫信号通路与C1QA或C1QC之间的相关性进行了分析。
- (D-F)使用七种算法通过热图分析可视化了免疫调节因子的富集情况,分别在GSE43292(D)、GSE28829(E)和GSE100927(F)数据集中进行。
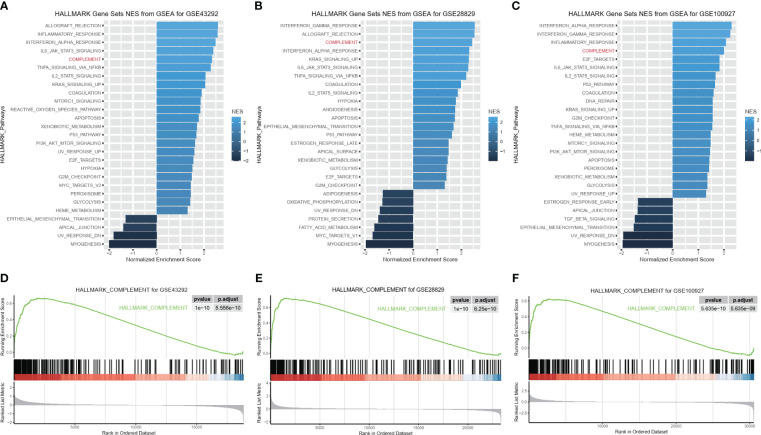
图8 C1QA激活了HAP中的HALLMARK_COMPLEMENT信号通路。
- (A-F)C1QA对三个GEO数据集(GSE43292、GSE28829和GSE100927)的GSEA分析结果。
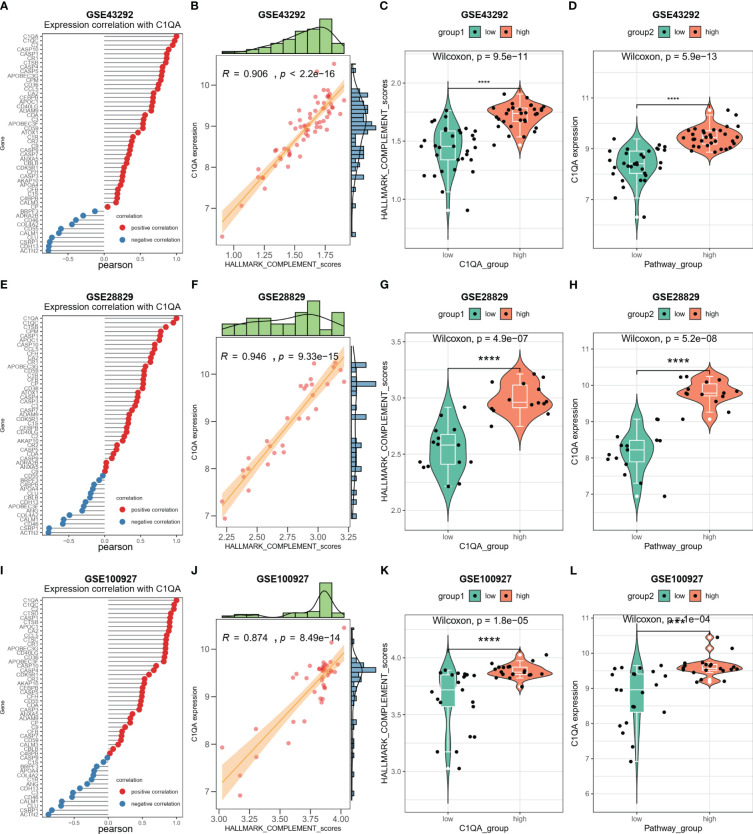
图9 C1QA与HAP中的HALLMARK_COMPLEMENT信号通路相关。
- C1QA基因与HALLMARK_COMPLEMENT信号通路之间的相关性以及它们在不同数据集中的表达水平和信号通路得分之间的关系
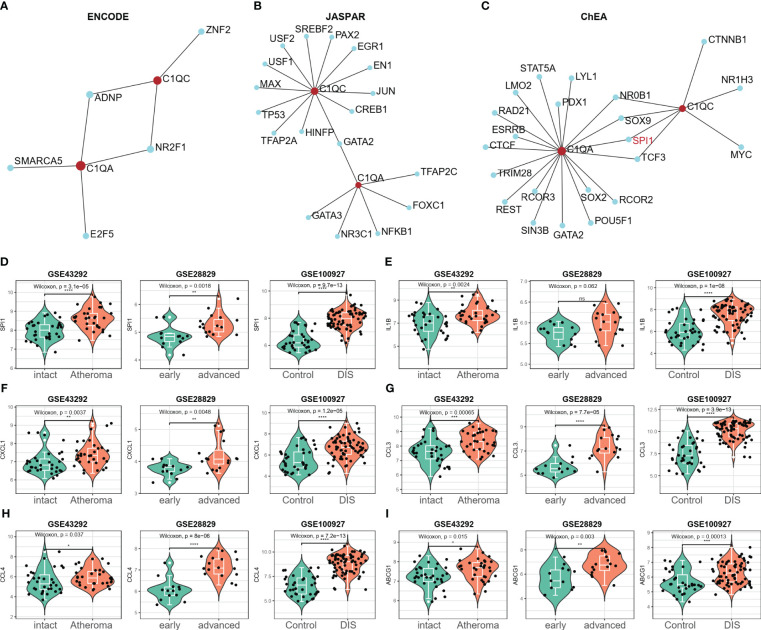
图10 SPI1被确定为HAP中的潜在关键转录因子。
- (A-C)通过NetworkAnalyst 3.0从三个数据库(ENCODE、JASPAR和ChEA)筛选可能调节C1QA和C1QC基因的潜在转录因子。
- (D)只有SPI1在所有三个GEO数据集(GSE43292、GSE28829和GSE100927)中的表达显著上调,并被视为C1QA和C1QC基因的潜在转录因子。
- (E-I)IL-1β、CXCL1、CCL3、CCL4和ABCG1基因在所有三个GEO数据集中均上调表达。
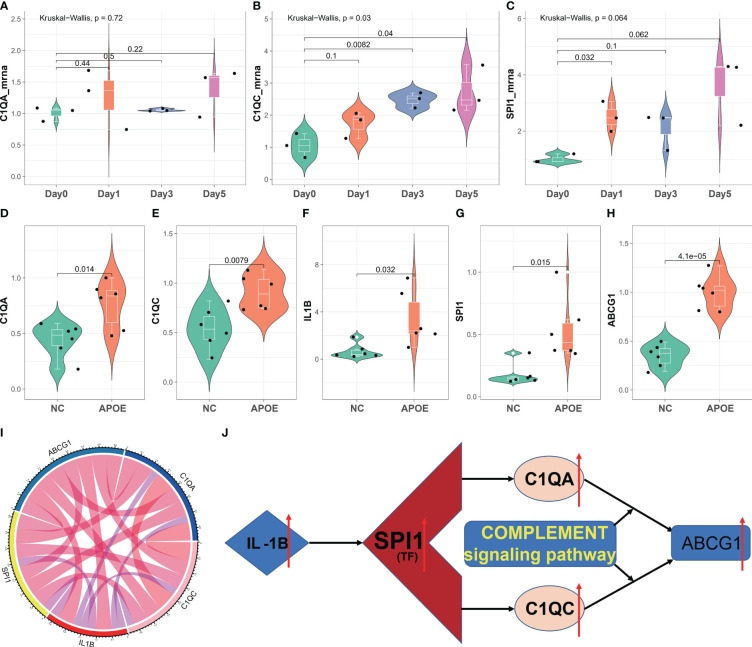
图11 C1QA和C1QC的体外和体内验证。
- (A-C)实时PCR检测氧化低密度脂蛋白(ox-LDL)处理的RAW264.7巨噬细胞组和正常对照组中C1QA和C1QC的相对mRNA表达水平。
- (D-H)实时PCR检测apoE小鼠的胸主动脉和腹主动脉以及正常小鼠中C1QA、C1QC、IL1B、SPI1和ABCG1的相对mRNA表达值。
- (I)这五个基因之间呈正相关关系。
- (J)C1QA和C1QC基因调节的HAP发展的潜在机制。
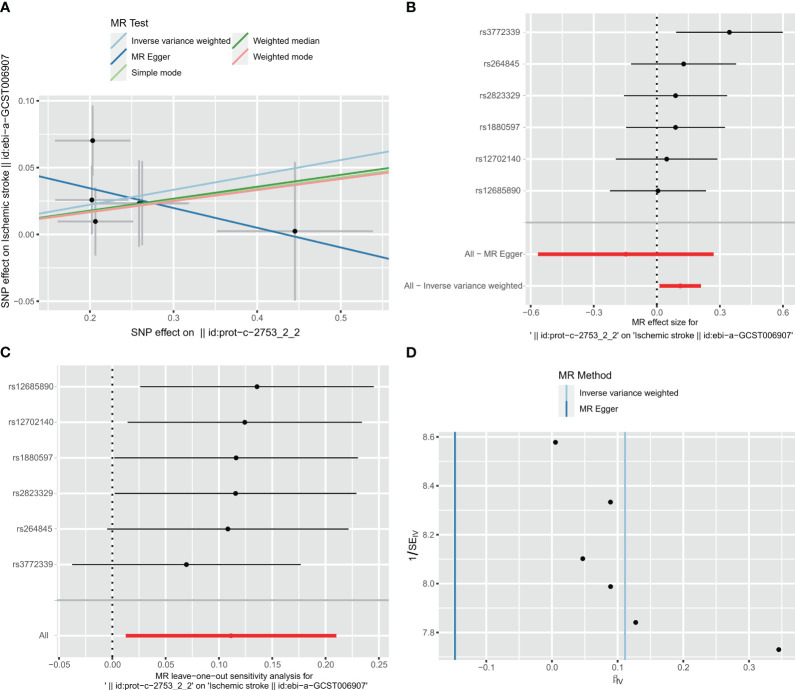
图12 C1Q对缺血性中风(IS)的MR分析可视化。
- (A)C1Q对IS影响的散点图MR分析。
- (B)C1Q相关单核苷酸多态性(SNPs)对IS的因果效应森林图。
- (C)对C1Q对IS影响的留一法敏感性分析。
- (D)漏斗图显示SNPs之间无显著异质性。
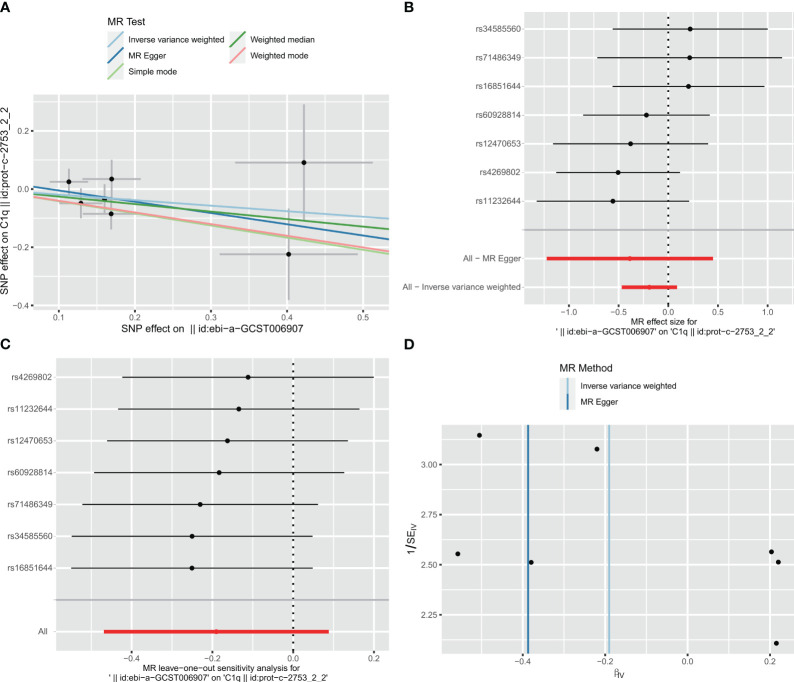
图13 缺血性中风(IS)对C1Q的MR分析可视化。
- (A)IS对C1Q影响的散点图MR分析。
- (B)IS相关单核苷酸多态性(SNPs)对C1Q的因果效应森林图。
- (C)对IS对C1Q影响的留一法敏感性分析。
- (D)漏斗图显示SNPs之间无显著异质性。
小结
- 主要数据及方法:
| Types | Notes |
|---|---|
| 转录组数据 | scRNA:GSE159677;bulkRNA:GSE28829、、GSE43292、GSE41571、GSE100927 |
| 其他数据 | GWAS:IEU openGWAS |
| 分析方法 | 单细胞标准流程;单细胞的GO、KEGG、GSVA和GSEA(Scillus 包);免疫微环境和信号通路富集(IMvigor210CoreBiologies R);机器学习筛选靶点(GBM、LASSO、XGBoost);ROC曲线;MR |
| 实验技术 | 体外细胞逆转录流程;小鼠建模-qPCR、免疫组化 |
- 非常严谨的思路和”充满诚意“的工作量,本质上还是单细胞+bulk的一种分析思路,MR充当验证的角色,其次最大的亮点就是多数据集多维度验证,当然还有着实验加持
- 文章是好文章,值得学习和借鉴~
这篇关于scRNA+bulk+MR:动脉粥样硬化五个GEO数据集+GWAS,工作量十分到位的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





