本文主要是介绍HRnet人体姿态估计的C++部署,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一. 导出模型
- 二、编译运行
- 三、原理
- 3.1 骨骼点识别(姿态估计)
- 3.2 higher hrnet
一. 导出模型
附件位置:
1.导出模型
- 进入Pytorch环境(可以使用Conda或者docker)
docker run --gpus all -it --name env_pyt_1.12 -v $(pwd):/app nvcr.io/nvidia/pytorch:22.03-py3
- 我们采用了bottom up的骨骼点检测算法,higher hrnet。 首先我们clone官方git(我做了fork备份)
# 克隆
git clone https://github.com/enpeizhao/HigherHRNet-Human-Pose-Estimation.git# 安装
pip install -r requirements.txt# 安装COCOAPI:# COCOAPI=/path/to/clone/cocoapi
git clone https://github.com/cocodataset/cocoapi.git $COCOAPI
cd $COCOAPI/PythonAPI
# Install into global site-packages
make install
# Alternatively, if you do not have permissions or prefer
# not to install the COCO API into global site-packages
python3 setup.py install --user# 安装 CrowdPose
git clone https://github.com/Jeff-sjtu/CrowdPose
# 安装步骤与COCOAPI类似
make install
python3 setup.py install --user
- 使用自己训练的模型,或使用官方的骨骼点模型,下面用官方提供的模型作为例子, 在higher hrnet的目录下运行
# 依赖
pip install onnx onnxruntime onnxsim
# 导出
python tools/export.py --cfg experiments/coco/higher_hrnet/w32_512_adam_lr1e-3.yaml TEST.MODEL_FILE weights/pose_higher_hrnet_w32_512.pth
导出模型后会得到hrnet.onnx, 和hrnet_sim.onnx。
二、编译运行
附件位置:
2.项目代码
# 构建
cmake -S . -B build
cmake --build build# 转TensorRT engine
./build/build --onnx_file ./weights/hrnet_sim.onnx --input_h 512 --input_w 512 --input_c 3# 启动推流服务器,下载rtsp-simple-server (改名叫mediamtx了),请下载对应的版本
# https://github.com/aler9/mediamtx/releases# 启动rtmp服务器
./start_server.sh# 测试文件或者视频流
# 单线程
./build/stream --vid rtsp --hrnet ./weights/hrnet_sim.engine --stream
# 多线程
./build/thread --vid rtsp --hrnet ./weights/hrnet_sim.engine --stream
如果是jetson nano或者jetson NX,请使用课程附件:4.jetson,操作流程参考之前课程。
三、原理
3.1 骨骼点识别(姿态估计)
骨骼点识别(Human Pose Estimation, HPE)是计算机视觉领域中的重要任务,旨在从图像或视频中检测和定位人体关节。目前的骨骼点识别方法主要分为两类:自顶向下(Top-Down)和自底向上(Bottom-Up)。
- 自顶向下方法(Top-Down): 自顶向下方法首先对整张图像进行人体检测,识别出所有可能的人体区域,然后分别对每个检测到的人体区域进行关键点检测和定位。这种方法通常包括以下两个步骤:
- 人体检测:在这一步中,通常使用预训练的目标检测模型(如Faster R-CNN、SSD或YOLO等)对图像中的人体进行检测。检测结果包括多个边界框,每个边界框对应一个人体实例。
- 关键点检测:对于每个检测到的人体实例,使用预训练的关键点检测模型(如OpenPose、Hourglass或CPM等)对其关键点进行检测和定位。最后,通过关键点之间的连线构建出完整的人体姿态。
- 自底向上方法(Bottom-Up): 自底向上方法直接在整张图像上进行关键点检测,然后将检测到的关键点通过一定的规则分组,形成不同人体的姿态。这种方法主要包括以下两个步骤:
- 关键点检测:使用预训练的关键点检测模型(如OpenPose、Hourglass或CPM等)对整张图像进行关键点检测。与自顶向下方法不同,自底向上方法不需要进行人体检测。
- 关键点分组:将检测到的关键点根据一定的规则(如距离、方向、颜色等)进行分组,形成不同人体的姿态。分组方法通常包括启发式搜索、图分割或者使用图神经网络等。
| 项目 | 计算复杂度 | 准确性 |
|---|---|---|
| top-down | 计算复杂度较高,一般人越多越慢。 | 对每个检测到的人体实例进行关键点检测,这使得它在处理遮挡和重叠情况时具有较好的准确性。 但如果人体检测阶段出现误检或漏检,将直接影响关键点检测的准确性。 |
| Bottom-up | 计算复杂度相对较低。 但在人体关键点分组阶段,可能需要更复杂的算法来处理遮挡和重叠的情况 | 在关键点检测阶段不受人体检测结果的影响,但在关键点分组阶段可能面临较大的挑战,尤其是在人体遮挡和重叠较为严重的场景中。 |
3.2 higher hrnet
本文中我们使用的是bottom up的多人骨骼点检测算法——higher hrnet。
参考:HigherHRNet: Scale-Aware Representation Learning for
Bottom-Up Human Pose Estimation
它是基于heat map的关键点检测算法,并使用associate embedding将点对应到个人。

如下图,是单人身体不同部位的关键点对应的heatmap,比如这里一共有14张图(14个关键点):

想象一下,如果是多人,则每个人都会检测出来14个关键点:

此时heatmap大致长这样,同一张图上是不同人的同一类型关键点,如第一幅图,是两个人的鼻子的位置
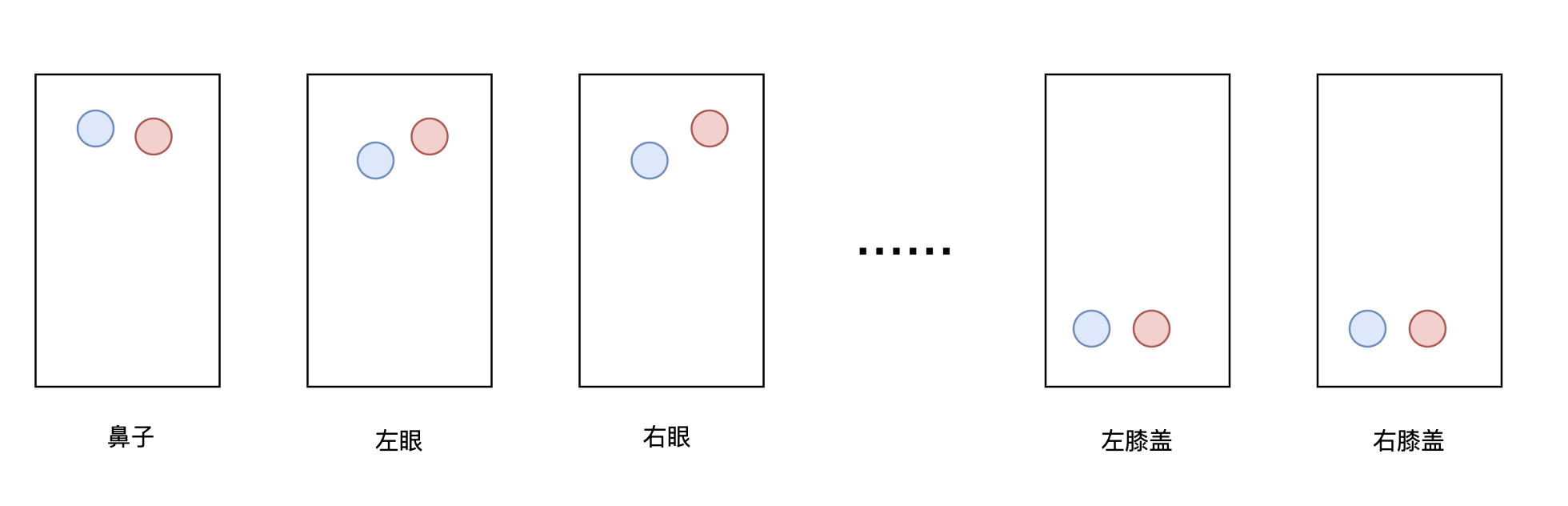
为了将检测结果对应到个人,需要用到Associative Embedding。网络需要对每个关节点的每个像素位置产生一个标签,也就是说,每个关节点的heatmap对应一个标签heatmap,因此,如果一张图片中待检测的关节点有 m 个,则网络理想状态下会输出 2m 个通道, m 个通道用于定位, m 个通道用于分组。
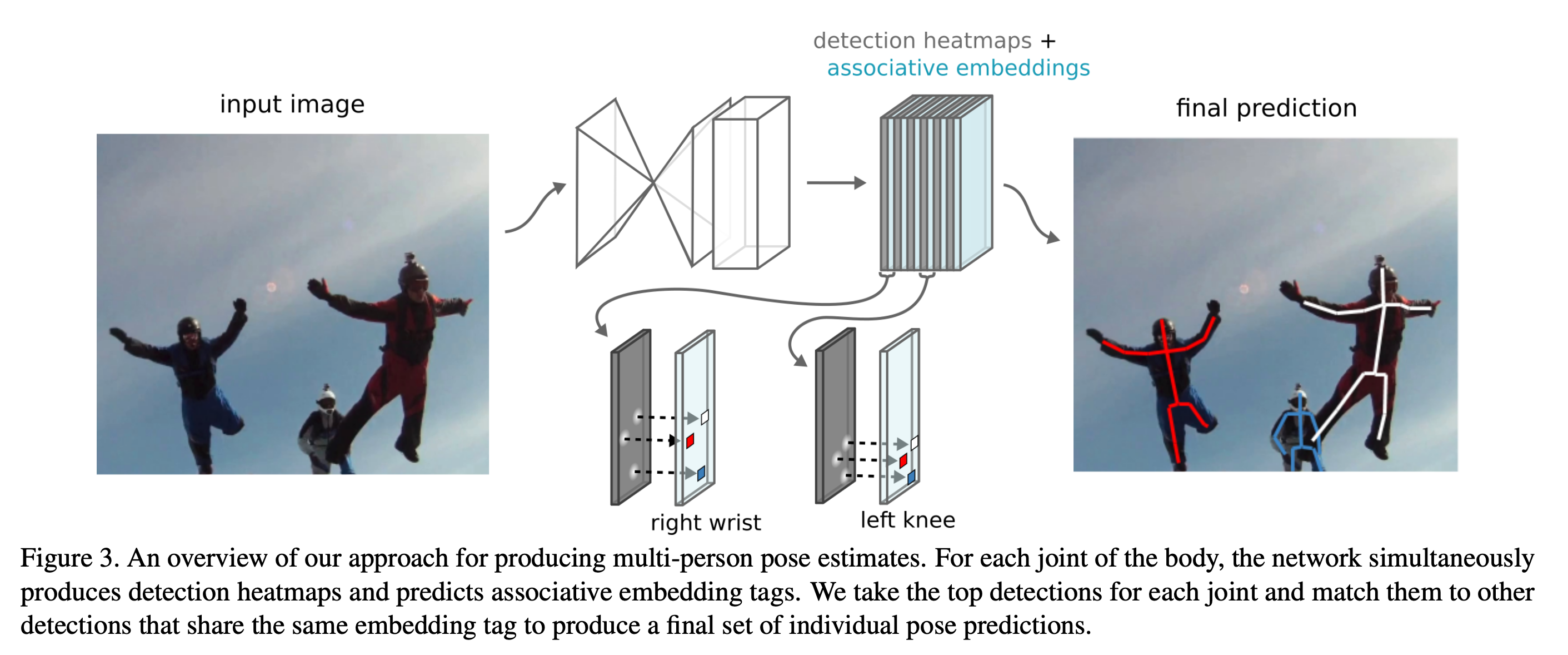
具体来说,可以用非极大值抑制(non-maximun suppression)来取得每个关节heatmap峰值,然后检索其对应位置的标签,再比较所有身体位置的标签,找到足够接近的标签分为一组,这样就将关节点匹配单个人身上,整个过程如下图所示:
参考:Associative Embedding: End-to-End Learning for Joint Detection and Grouping
其中标签所在的heatmap类似分割任务,如下图所示:

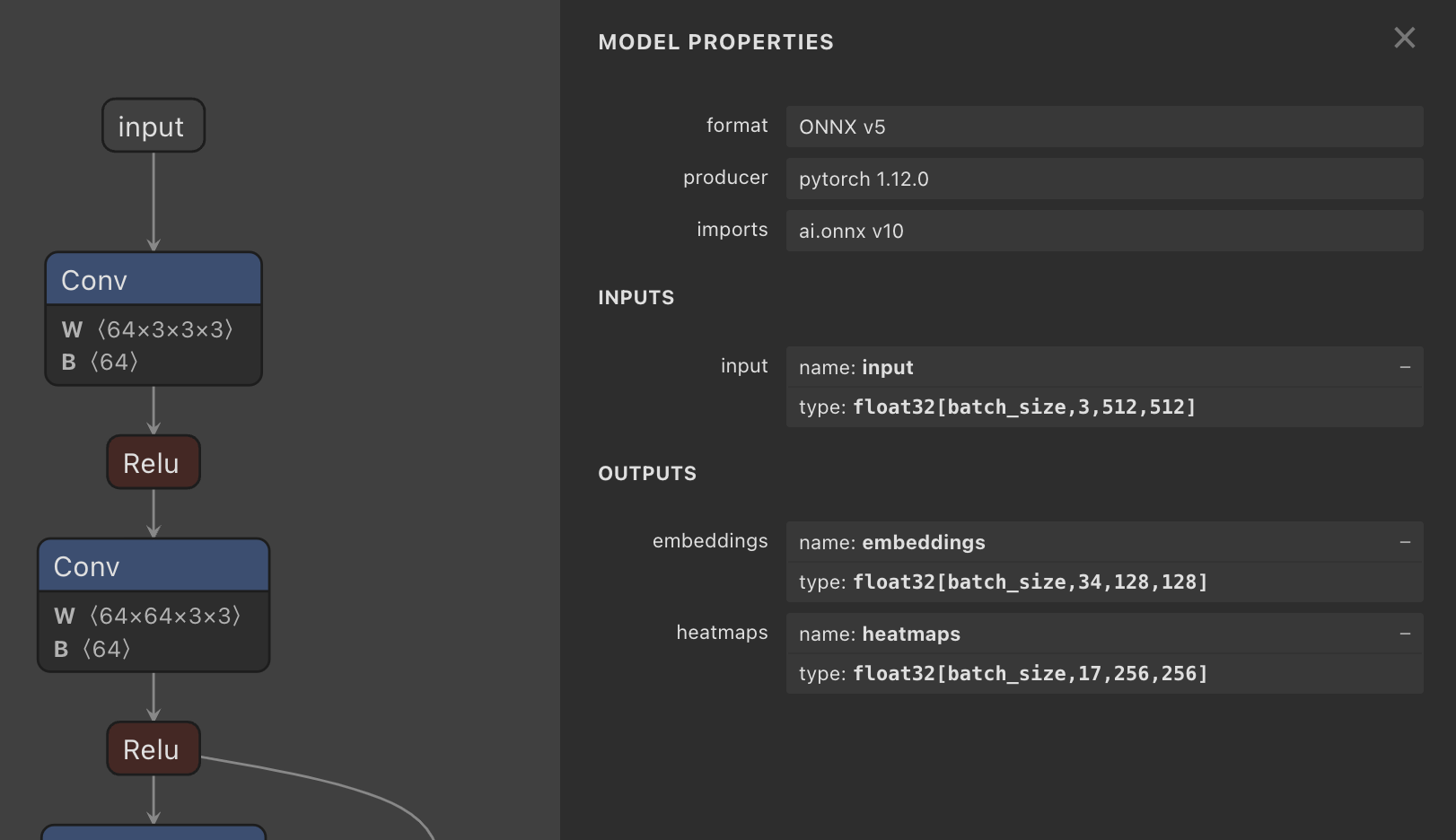
如下图:我们检查higher hrnet的网络可以看到2个输出:
- Heat maps:(n,17,256,256),17个身体部位关键点的heatmap;
- embedding:(n, 34, 512, 512),后17个图是heatmap对应的标签heatmap。
最后代码中需要执行以下步骤:
- heatmap NMS:每个关节heatmap峰值(课程里我们使用CUDA kernel来加速的,效果查看附件:
3.NMS演示下2张图。

- Associative Embedding:为了将检测结果对应到个人,这里参考的是以下代码:
- Python版:
- https://github.com/HRNet/HigherHRNet-Human-Pose-Estimation/blob/master/lib/core/group.py
- https://github.com/princeton-vl/pose-ae-train/blob/454d4ba113bbb9775d4dc259ef5e6c07c2ceed54/utils/group.py
- C++ 版:
- https://docs.openvino.ai/latest/omz_models_model_higher_hrnet_w32_human_pose_estimation.html
- https://github.com/openvinotoolkit/open_model_zoo/blob/master/demos/common/cpp/models/src/associative_embedding_decoder.cpp
- Python版:
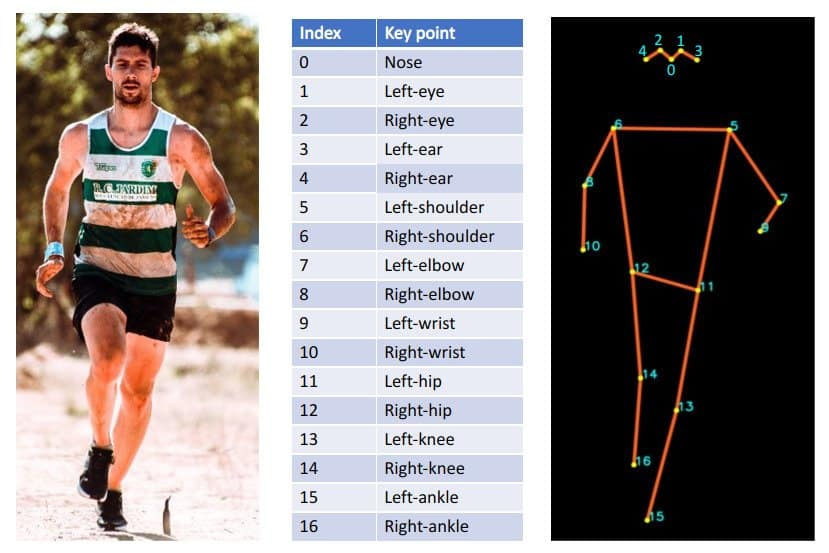
代码中的动作识别根据关节夹角关系实现:
这篇关于HRnet人体姿态估计的C++部署的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








