本文主要是介绍Pipy与BPF:打造无侵入无感知的流量拦截方案,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

背景
在当代的互联网技术领域,微服务架构已成为应用部署的主流模式,它虽然增强了开发流程的敏捷性和系统的可扩展性,但随着服务数量的增加,系统的内部通信变得越来越复杂。特别是在服务的接口和依赖关系不透明的情况下,整个系统的维护和优化工作变得异常困难。

今天要介绍的流量拦截技术,从本质上讲,提供了一种“上帝视角”来观察和分析在复杂网络系统中流动的数据。这种方法使得开发和运维团队能够对通常隐蔽和不透明的服务间交互进行“抽丝剥茧”,揭露隐藏在数据流中的详细信息和交互模式。通过这种高度的可视化和分析能力,团队可以深入理解服务的运行机制,即使这些服务表面上看起来像是封闭和不透明的“黑盒”。
方案
Pipy 的升级到 1.0 版本 标志着它从一个单纯处理数据流的代理,转变为一个全面的可编程应用引擎。这一重要的演进不仅扩展了 Pipy 的使用场景,也极大地提高了其在现代网络架构中的价值和灵活性。将 Pipy 作为 BPF(Berkeley Packet Filter)的控制器使用,是其作为控制面能力的一个典型示例。这种能力的加入,为网络流量管理和系统监控提供了更加强大和灵活的工具。
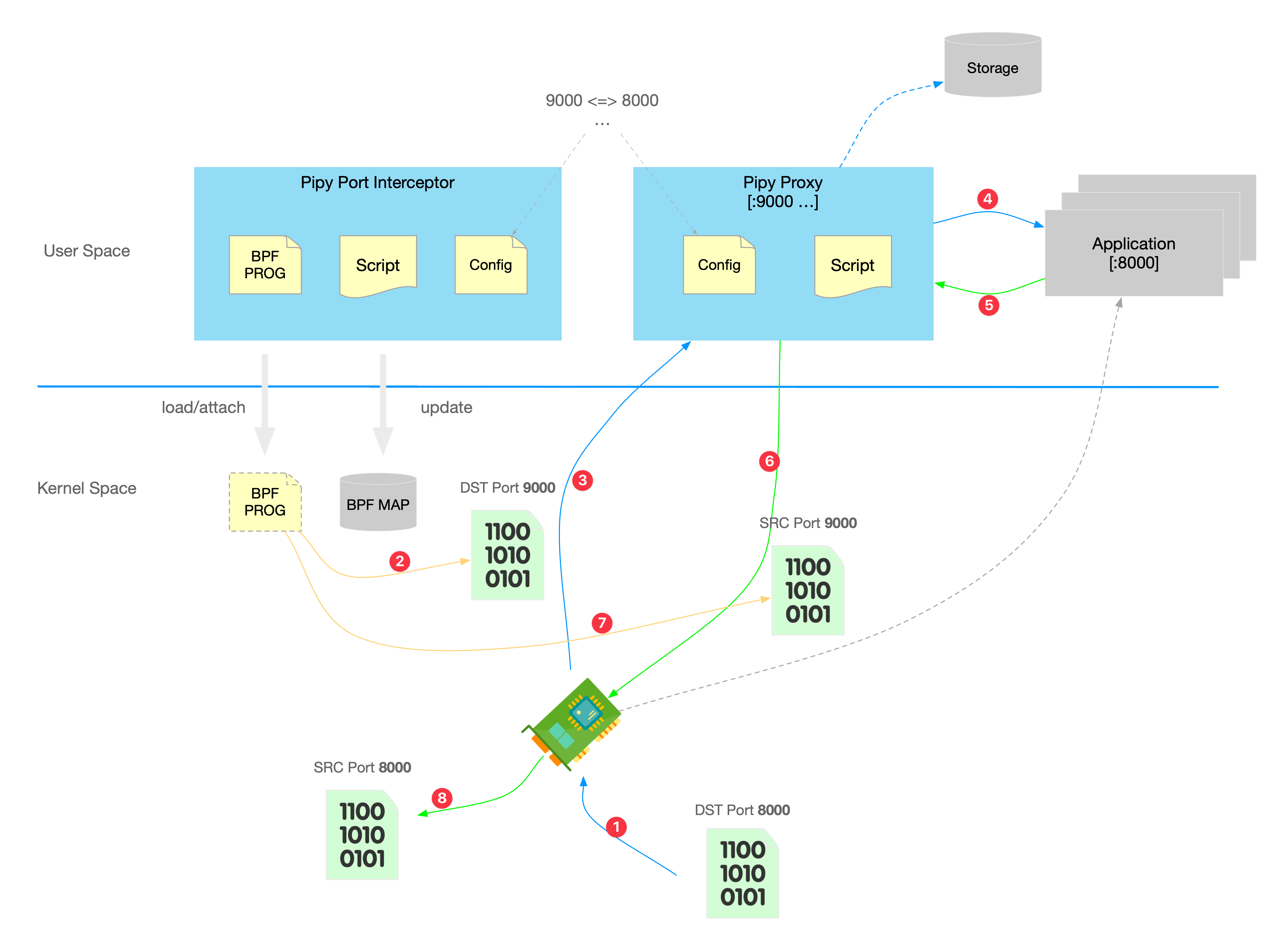
本方案利用 Pipy 代理作为控制面,在主机节点上加载 BPF(Berkeley Packet Filter)程序,根据预设的配置(如端口映射关系)动态拦截并转发目标流量。这一过程中,访问原始端口(originalPort)的流量会被转发到一个监听指定端口(port)上的代理服务。代理服务进一步根据流量的协议类型,对数据包进行解码和结构化处理,然后将解析后的请求内容通过 HTTP 协议发送到如 Elasticsearch 的存储进行存储和分析。此外,流量还会被原封不动地转发到原始目标端口,确保服务的连续性和透明性。
接下来我们演示如何使用 Pipy 来进行 HTTP 和 Dubbo 的流量拦截和分析。
演示
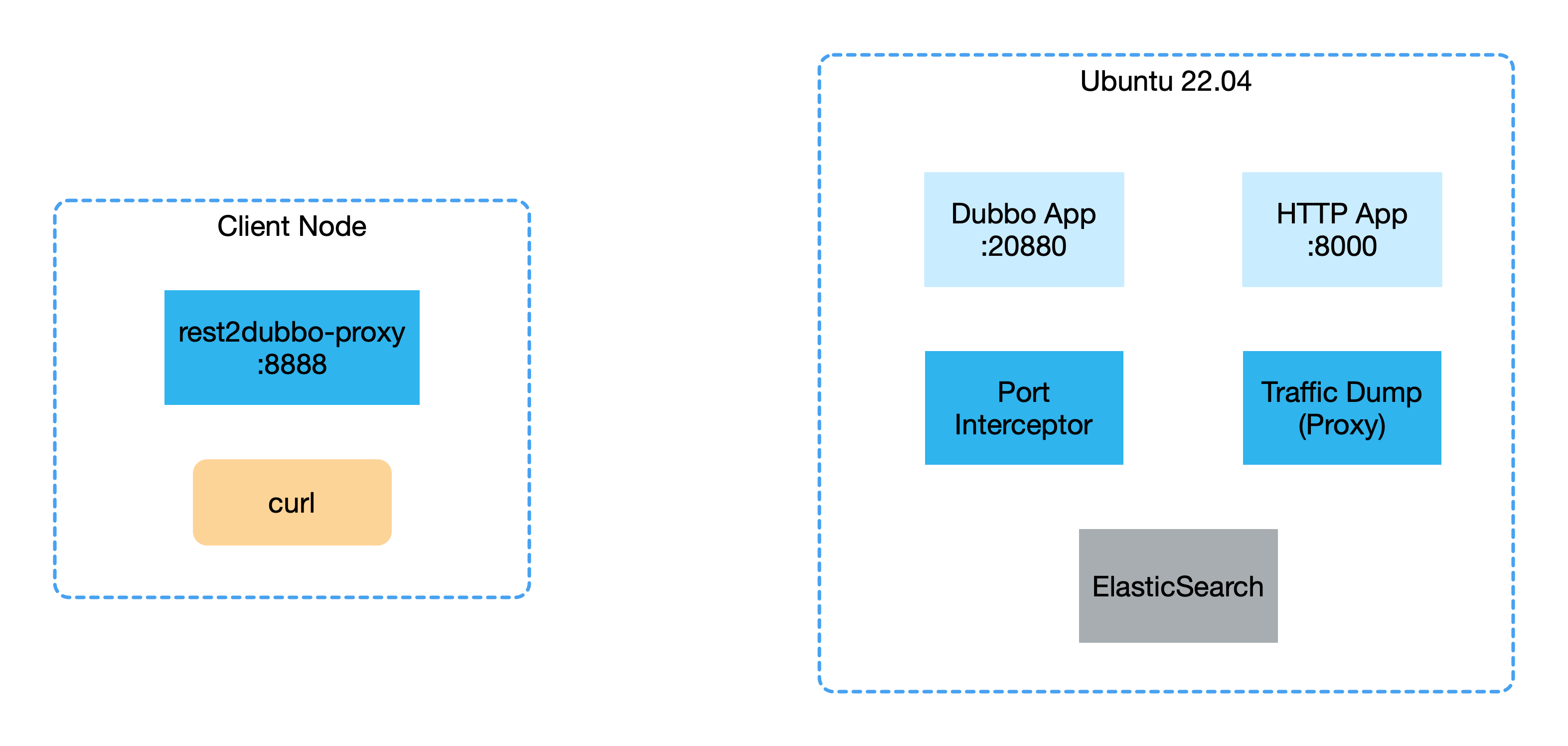
这篇演示中,我们将用到项目 traffic-interceptor,这个项目中包含三个部分:
- rest2dubbo:使用 Pipy 做 HTTP 到 Dubbo 的协议转换。
- port-interceptor:使用 Pipy 实现的端口拦截控制器,通过 BPF 将访问某些原始端口(originalPort)的流量转发到指定的端口(port)进行流量拦截。
- traffic-dump:使用 Pipy 实现的代理,监听指定的端口(port)然后将流量转发到原始端口(originalPort),同时会将流量的信息结构化后发送到 ElasticSearch 中。
下面是演示的架构图:
前置条件
- Ubuntu 22.04(内核版本 6.5):运行 Dubbo 和 HTTP 应用的主机
- 客户端主机(系统类型不限):用于运行 rest2dubbo 代理、发起 HTTP 请求
- 下载并安装 Pipy 1.0.0
- Docker
- jq
环境准备
- 启动 Dubbo 应用,服务在
20880端口。
docker run --rm -d --name bookwarehouse -e spring.profiles.active=dubbo,dev -e dubbo.registry.register=false -p 20880:20880 addozhang/bookwarehouse-dubbo:0.3.1
- 启动 HTTP 应用。
pipy "pipy.listen(8000, $ => $.serveHTTP(new Message('Hi, Pipy')))"
- 启动 ElasticSearch。
docker run --rm -d --name es -p 9200:9200 -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:7.10.1
环境验证
在客户端主机上,启动 rest2dump 代理。这个代理会接收 HTTP 请求,通过协议转换成 Dubbo 请求后转发给上面的 Dubbo 应用。
git clone https://github.com/flomesh-io/pipy-demos.git
cd pipy-demos/traffic-interceptor
在启动代理之前,需要将 rest2dubbo/main.js 中的 上游服务地址 改为运行 Dubbo 服务的主机地址,比如我使用的主机地址是 20.24.215.69。然后启动代理。
pipy rest2dubbo/main.js
启动成功后从日志中可以看到其监听 8888 端口,通过 curl 来发送请求。
curl 'http://127.0.0.1:8888/v1/getBook' --header 'Content-Type: application/json' --data '{"id": 1}'
将收到如下响应。这说明我们的 rest2dump 的协议转换代理运行正常。
{"date": "2024-03-14T15:18:56.982Z","isbn": "9787517054221","author": "Flomesh","name": "Pipy 入门","value": 0,"id": "1"
}
同样测试 HTTP 应用的访问。
curl http://20.24.215.69:8000/hi
正常收到响应。
Hi, Pipy
接下来我们就可以测试流量拦截了,先启动 Traffic Dump 代理。
启动 Traffic Dump 代理
Traffic Dump 代理的运行很简单,执行下面的命令。
git clone https://github.com/flomesh-io/pipy-demos.git
cd pipy-demos/traffic-interceptor
pipy traffic-dump/main.js
运行之后可以从日志中可以看到其监听 9000 和 30880 两个端口。
启动端口拦截
首先我们需要编译 BPF 程序。
cd port-interceptor
make
在 bin 目录中可以看到编译好的 BPF 程序 port-interceptor.o。
执行下面的命令启动端口拦截。
sudo pipy /main.js
注意:该脚本需要
sudo,因为它需要调用tc将 BPF 程序挂接到内核中的数据路径,这需要管理员权限。
启动后可以看到 Pipy 更新 BPF map 以及加载 BPF 程序的日志。
2024-03-14 15:48:11.881 [INF] Updating BPF maps...
2024-03-14 15:48:11.881 [INF] Created port mapping 8000 <---> 9000
2024-03-14 15:48:11.881 [INF] Created port mapping 8443 <---> 9443
2024-03-14 15:48:11.881 [INF] Created port mapping 20880 <---> 30880
验证
再次重发上面的 HTTP 和 Dubbo 请求,都可以正常收到响应。
curl http://20.24.215.69:8000/hi
curl 'http://127.0.0.1:8888/v1/getBook' --header 'Content-Type: application/json' --data '{"id": 1}'
访问 ElasticSearch 查询保存的请求记录。
HTTP 请求:
curl -s -X GET "http://localhost:9200/http/_search" -H 'Content-Type: application/json' | jq .hits.hits
[{"_index": "http","_type": "_doc","_id": "W9mqPY4Bi_IvwOBjFiex","_score": 1,"_source": {"time": 1710431540691,"host": "20.24.215.69:8000","path": "/hi","headers": "{\"host\":\"20.24.215.69:8000\",\"user-agent\":\"curl/8.4.0\",\"accept\":\"*/*\"}"}}
]
Dubbo 请求:
curl -s -X GET "http://localhost:9200/dubbo/_search" -H 'Content-Type: application/json' | jq .hits.hits
[{"_index": "dubbo","_type": "_doc","_id": "WtmqPY4Bi_IvwOBjEycL","_score": 1,"_source": {"time": 1710431539513,"dubboVer": "2.0.2","interface": "io.flomesh.demo.api.BookWarehouseService","ver": "v1","method": "getBook","args": ["Ljava/lang/String;","1"],"raw": "[\"2.0.2\",\"io.flomesh.demo.api.BookWarehouseService\",\"v1\",\"getBook\",\"Ljava/lang/String;\",\"1\",{\"kind\":\"map\",\"elements\":[[\"input\",\"196\"],[\"path\",\"io.flomesh.demo.api.BookWarehouseService\"],[\"interface\",\"io.flomesh.demo.api.BookstoreService\"],[\"version\",\"v1\"]]}]"}}
]
Bingo!演示完成。
总结
通过这一系列步骤,我们展现了如何利用 Pipy 来实施流量拦截与分析,全部操作均在无需改动现有网络结构和应用代码的前提下完成。
Pipy 1.0 的发布,不仅代表了其从一个数据面代理向可编程应用引擎的转变,也预示着其在现代网络架构中角色的重大扩展。Pipy 的高度可编程性和灵活性使其成为实现精细流量管理和深度网络分析的强大工具。无论是提高网络透明度、优化服务性能,还是加强安全防护,Pipy 都能提供有效的支持。
关于 Flomesh
Flomesh(易衡科技)成立于 2018 年,自主研发并开源了高性能可编程代理 Pipy(https://github.com/flomesh-io/pipy)。以 Pipy 为基础,Flomesh 研发了软件负载均衡、服务网格两款软件产品。为工信部认证的可信云产品、可信开源项目。
Flomesh 核心竞争力来自完全自研的核心组件 Pipy,该组件高性能、高可靠、低延迟、可编程、可扩展、低依赖,采用 C++ 开发,内置自研的 JS 引擎,支持适用 JS 脚本做扩展开发。支持包括 x86、arm、龙芯、海光等硬件 CPU 架构;支持 Linux、FreeBSD、macOS、Windows、OpenWrt 等多种核心的操作系统。
Flomesh 成立以来,以技术为根基、以客户为导向,产品被应用在头部股份制商业银行总行、大型保险公司、运营商总部以及研究院等众多客户和多个场景。

这篇关于Pipy与BPF:打造无侵入无感知的流量拦截方案的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





