本文主要是介绍ANTLR使用访问器遍历语法树,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
计算器
语法文件
实现一个简单的计算器,可以对如下表达式进行识别
193
a = 5
b = 6
a+b*2
(1+2)*3
如下为匹配规则的语法文件Expr.g4
grammar Expr;/** 起始规则,语法分析的起点 */
prog: stat+ ; stat: expr NEWLINE //匹配expr表达式 + 换行| ID '=' expr NEWLINE //匹配 变量 = 表达式 换行 | NEWLINE //匹配换行 ;expr: expr ('*'|'/') expr //匹配表达式*/| expr ('+'|'-') expr //匹配表达式+-| INT //整数 | ID //变量| '(' expr ')' //括号;//词法分析器
ID : [a-zA-Z]+ ; // 由字母组成的变量名
INT : [0-9]+ ; // 数字
NEWLINE:'\r'? '\n' ; // 换行
WS : [ \t]+ -> skip ; // 匹配空白,按->skip命令跳过
左递归规则:例如在语法规则expr: expr ('*'|'/') expr中,expr在备选分支的起始位置对自身进行了递归调用
使用antlr运行编译,然后利用TestBig工具进行测试
D:\Code\antlr\demo\chapter4>antlr4 Expr.g4 # 生成语法、词法分析器D:\Code\antlr\demo\chapter4>javac *.java # 编译相关文件# 对语法Expr进行测试,初始规则prog,输入文件t.expr,并以可视化的方式输出结果
D:\Code\antlr\demo\chapter4>grun Expr prog -gui t.expr
生成的语法分析树如下所示
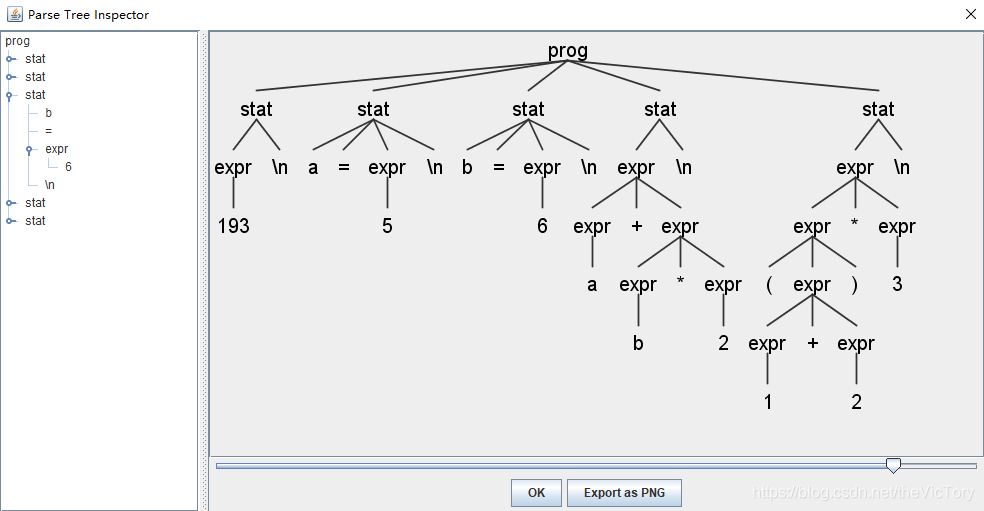
文件引入
在一个庞大的项目中,通常将语法文件拆分为语法规则文件和词法规则文件,这样有一些重复的词法规则就可以放在一个文件中以实现重用,当需要使用的时候再将文件引入。
如下所示,将所有词法规则放到文件CommonLexerRules.g4中
lexer grammar CommonLexerRules; // 词法文件以关键字"lexer grammar"开头ID : [a-zA-Z]+ ;
INT : [0-9]+ ;
NEWLINE:'\r'? '\n' ;
WS : [ \t]+ -> skip ;
然后在语法规则文件LibExpr.g4中引入所需的文件,之后我们只需要对LibExpr运行antlr构建工具即可,不需要再手动操作导入的文件
grammar LibExpr;
import CommonLexerRules; // 引入词法文件prog: stat+ ; stat: expr NEWLINE | ID '=' expr NEWLINE | NEWLINE ;expr: expr ('*'|'/') expr | expr ('+'|'-') expr | INT | ID | '(' expr ')' ;
错误处理
ANTLR语法分析器能够自动识别语法报告中的错误并从错误中恢复。
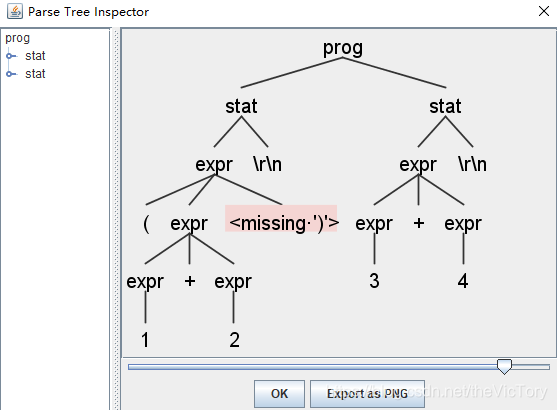
如下所示,在输入中少了一个括号,语法分析树会输出提示信息,并且会继续向后匹配
D:\Code\antlr\demo\chapter4>grun LibExpr prog -tree
(1+2
3+4
^Z
line 1:4 mismatched input '\r\n' expecting {'*', '/', '+', '-', ')'} # 提示缺失
(prog (stat (expr ( (expr (expr 1) + (expr 2)) <missing ')'>) \r\n) (stat (expr (expr 3) + (expr 4)) \r\n))\ # 不影响继续匹配
如果使用gui的方式,会在确实的节点显示为红色
使用访问器遍历树
在构建了语法分析树后,使用访问器对节点进行遍历从而得出计算结果。访问器机制和监听器机制最大的区别在于,监听器方法会被遍历器自动调用,而访问器必须手动调用visit()方法实现对子节点的访问。
在使用访问器之前,需要对语法文件的每个分支添加标签,ANTLR会为每个标签生成相应的方法,否则只会默认为每个规则生成一个方法。如下所示为语法规则文件LabeledExpr.g4,标签以#开头,放在分支右侧
grammar LabeledExpr;prog: stat+ ;stat: expr NEWLINE # printExpr| ID '=' expr NEWLINE # assign| NEWLINE # blank;expr: expr op=('*'|'/') expr # MulDiv| expr op=('+'|'-') expr # AddSub| INT # int| ID # id| '(' expr ')' # parens;//在语法文件中,为词法符号命名,这样在Java中就可以当作常量来访问了
MUL : '*' ; // 将 '*' 命名为MUL
DIV : '/' ;
ADD : '+' ;
SUB : '-' ;//词法规则
ID : [a-zA-Z]+ ; // match identifiers
INT : [0-9]+ ; // match integers
NEWLINE:'\r'? '\n' ; // return newlines to parser (is end-statement signal)
WS : [ \t]+ -> skip ;
对上述语法文件运行ANTLR构建工具,通过命令参数-visitor指定生成包含访问器的代码
antlr4 -no-listener -visitor LabeledExpr.g4
自动生成访问器接口类LabeledExprVisitor,之前在语法文件中定义的标签都会生成对应的方法,传入相应的上下文作为参数,并且以泛型的方式定义接口类,我们可以根据需要自定义返回值类型。同时生成了接口的默认实现类LabeledExprBaseVisitor
public interface LabeledExprVisitor<T> extends ParseTreeVisitor<T> {T visitProg(LabeledExprParser.ProgContext ctx); //访问Prog标签T visitPrintExpr(LabeledExprParser.PrintExprContext ctx); //访问PrintExpr标签T visitAssign(LabeledExprParser.AssignContext ctx); //访问Assign标签......
}public class LabeledExprBaseVisitor<T> extends AbstractParseTreeVisitor<T> implements LabeledExprVisitor<T> {@Override public T visitProg(LabeledExprParser.ProgContext ctx) { return visitChildren(ctx); }@Override public T visitPrintExpr(LabeledExprParser.PrintExprContext ctx) { return visitChildren(ctx); }@Override public T visitAssign(LabeledExprParser.AssignContext ctx) { return visitChildren(ctx); }......
}
通过继承LabeledExprBaseVisitor,实现自定义访问器类EvalVisitor ,在其中实现具体访问节点的代码,完成计算器的运算操作。注意在每个visitXxx()方法中都通过visit()方法手动对子节点进行访问
import java.util.HashMap;
import java.util.Map;public class EvalVisitor extends LabeledExprBaseVisitor<Integer> {/** 计算器的“内存”,存放<变量名, 变量值> */Map<String, Integer> memory = new HashMap<String, Integer>();/** ID '=' expr NEWLINE */@Overridepublic Integer visitAssign(LabeledExprParser.AssignContext ctx) {String id = ctx.ID().getText(); // 获取=左边的变量int value = visit(ctx.expr()); // 计算右侧表达式的值memory.put(id, value); // 将计算结果储存到“内存”中return value;}/** expr NEWLINE */@Overridepublic Integer visitPrintExpr(LabeledExprParser.PrintExprContext ctx) {Integer value = visit(ctx.expr()); // 计算子节点的值System.out.println(value); // 打印结果return 0; // 返回虚值}/** INT */@Overridepublic Integer visitInt(LabeledExprParser.IntContext ctx) {return Integer.valueOf(ctx.INT().getText());}/** ID */@Overridepublic Integer visitId(LabeledExprParser.IdContext ctx) {String id = ctx.ID().getText();if ( memory.containsKey(id) ) return memory.get(id);return 0;}/** expr op=('*'|'/') expr */@Overridepublic Integer visitMulDiv(LabeledExprParser.MulDivContext ctx) {int left = visit(ctx.expr(0)); // 递归计算左侧表达式的值int right = visit(ctx.expr(1)); // 计算右侧表达式的值if ( ctx.op.getType() == LabeledExprParser.MUL ) return left * right; //两值相乘return left / right; // 或者相除}/** expr op=('+'|'-') expr */@Overridepublic Integer visitAddSub(LabeledExprParser.AddSubContext ctx) {int left = visit(ctx.expr(0)); // get value of left subexpressionint right = visit(ctx.expr(1)); // get value of right subexpressionif ( ctx.op.getType() == LabeledExprParser.ADD ) return left + right;return left - right; // must be SUB}/** '(' expr ')' */@Overridepublic Integer visitParens(LabeledExprParser.ParensContext ctx) {return visit(ctx.expr()); // 返回子表达式的值}
}
最后实现一个主程序Calc.java对语法分析树进行遍历,计算结果
import org.antlr.v4.runtime.*;
import org.antlr.v4.runtime.tree.ParseTree;import java.io.FileInputStream;
import java.io.InputStream;public class Calc {public static void main(String[] args) throws Exception {String inputFile = null;if ( args.length>0 ) inputFile = args[0];InputStream is = System.in; //从标准输入获取字符if ( inputFile!=null ) is = new FileInputStream(inputFile); //从文件获取输入字符ANTLRInputStream input = new ANTLRInputStream(is);LabeledExprLexer lexer = new LabeledExprLexer(input); //词法分析器CommonTokenStream tokens = new CommonTokenStream(lexer); //将词法分析器产生的词法符号放到缓冲区ArrayInitParser parser = new ArrayInitParser(tokens); //将词法符号送入语法分析器ParseTree tree = parser.prog(); //开始分析EvalVisitor eval = new EvalVisitor(); //创建访问器eval.visit(tree); //开始遍历分析树}
}
对上述文件进行编译、运行Calc,可以看到输出计算结果
D:\Code\antlr\demo\chapter4>javac *.javaD:\Code\antlr\demo\chapter4>java Calc
(1+2)
3+4
^Z
3
7
这篇关于ANTLR使用访问器遍历语法树的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






